TL;DR本文解释了 Linux 内核的计算机如何发送数据包,以及当数据包从用户程序流向网络硬件时,如何监控和调优网络栈的每个组件。
本文是之前的文章 监控和调优 Linux 网络栈:接收数据 的姊妹篇。
如果不阅读内核的源代码,不深入了解到底发生了什么,就不可能调优或监控 Linux 网络栈。
希望本文能给想做这方面工作的人提供参考。
关于监控和调优 Linux 网络栈的一般性建议
正如在上一篇文章中提到的,Linux 网络栈是复杂的,没有一刀切的监控或调优解决方案。 如果您真的想调优网络栈,您别无选择,只能投入大量的时间、精力和金钱来了解网络系统的各个部分是如何交互的。
本文中提供的许多示例设置仅用于说明目的,并不是对某个配置或默认设置的推荐或反对。 在调整任何设置之前,您应该围绕您需要监控的内容制定一个参考框架,以注意到有意义的变化。
网络连接到计算机时调整网络设置是危险的;你很容易地把自己锁在外面,或者完全关闭你的网络。 不要在生产机器上调整这些设置;相反,如果可能的话,在新机器上进行调整,再投入生产中。
概览
作为参考,您可能需要手边有一份设备数据手册。 这篇文章将研究由 igb 设备驱动程序控制的 Intel I350 以太网控制器。 您可以找到该数据手册(警告:大型 PDF)供您参考。
网络数据从用户程序到网络设备的流程概览:
- 使用系统调用(如
sendto、sendmsg等)写入数据。 - 数据通过套接字子系统传递到套接字协议族的系统(本例是
AF_INET)。 - 协议族通过协议层传递数据,协议层(在许多情况下)将数据转成数据包。
- 数据通过路由层,沿途填充目标和邻居缓存(如果是冷缓存)。 如果需要查找以太网地址,会生成 ARP 流量。
- 在通过协议层之后,数据包到达设备无关层。
- 使用 XPS(如果启用)或哈希函数选择输出队列。
- 调用设备驱动程序的发送函数。
- 然后,数据被传递到输出设备附属的排队规则(qdisc)。
- 如果可以,qdisc 将直接传输数据;或将其排队,等待
NET_TX 软中断期间发送。 - 最后,数据从 qdisc 传递给驱动程序。
- 驱动程序创建所需的 DMA 映射,以便设备可以从 RAM 读取数据。
- 驱动器向设备发送信号,表示数据准备就绪。
- 设备从 RAM 读取数据并传输。
- 传输完成后,设备发出硬中断信号,表示传输完成。
- 驱动程序注册的传输完成硬中断处理程序运行。 对于许多设备,此处理程序只是生成
NET_RX 软中断,触发 NAPI 轮询循环开始运行。 - 软中断触发轮询函数运行,并调用驱动程序以解除 DMA 映射、释放数据包。
接下来各节会详细介绍以上整个流程。
下面探讨的协议层是 IP 和 UDP 协议层。 本文介绍的许多信息也可作为其他协议层的参考。
详细探讨
与姊妹篇类似,本文将探讨 Linux 3.13.0 版本内核,贯穿全文提供了 GitHub 代码链接和代码片段。
从如何在内核中注册协议族、套接字子系统如何使用协议族开始探讨,然后探讨协议族接收数据。
协议族注册
当用户程序中运行这样一段代码来创建 UDP 套接字时,会发生什么?
sock = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP)
简而言之,Linux 内核查找 UDP 协议栈导出的一组函数,它们处理包括发送和接收网络数据在内的许多事情。 要准确理解其工作原理,必须深入 AF_INET 地址族代码。
Linux 内核在内核初始化的早期执行 inet_init 函数。 此函数注册 AF_INET 协议族、协议族中的各种协议栈(TCP、UDP、ICMP 和 RAW),并调用初始化程序使协议栈准备好处理网络数据。 您可以在 ./net/ipv4/af_inet.c 中找到 inet_init 的代码。
AF_INET 协议族导出了一个具有 create 函数的结构。 当用户程序创建套接字时,内核会调用此函数:
static const struct net_proto_family inet_family_ops = { .family = PF_INET, .create = inet_create, .owner = THIS_MODULE,};
inet_create 函数接受传递给套接字系统调用的参数,搜索已注册的协议,以找到链接到套接字的一组操作。 看一看:
lookup_protocol: err = -ESOCKTNOSUPPORT; rcu_read_lock(); list_for_each_entry_rcu(answer, &inetsw[sock->type], list) { err = 0; if (protocol == answer->protocol) { if (protocol != IPPROTO_IP) break; } else { if (IPPROTO_IP == protocol) { protocol = answer->protocol; break; } if (IPPROTO_IP == answer->protocol) break; } err = -EPROTONOSUPPORT; }
稍后,复制 answer 的 ops 字段到套接字结构中,answer 持有协议栈相关的引用:
sock->ops = answer->ops;
可以在 af_inet.c 中找到所有协议栈的结构定义。 让我们看一下TCP 和 UDP 协议结构:
static struct inet_protosw inetsw_array[] ={ { .type = SOCK_STREAM, .protocol = IPPROTO_TCP, .prot = &tcp_prot, .ops = &inet_stream_ops, .no_check = 0, .flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK, }, { .type = SOCK_DGRAM, .protocol = IPPROTO_UDP, .prot = &udp_prot, .ops = &inet_dgram_ops, .no_check = UDP_CSUM_DEFAULT, .flags = INET_PROTOSW_PERMANENT, },
在 IPPROTO_UDP 的情况下,ops 结构关联包含各种功能的函数,包括发送和接收数据:
const struct proto_ops inet_dgram_ops = { .family = PF_INET, .owner = THIS_MODULE, .sendmsg = inet_sendmsg, .recvmsg = inet_recvmsg, };EXPORT_SYMBOL(inet_dgram_ops);
协议相关的结构 prot 包含函数指针,指向 UDP 协议栈所有内部函数。UDP 协议中,此结构被称为 udp_prot,并由 ./net/ipv4/udp.c 导出:
struct proto udp_prot = { .name = "UDP", .owner = THIS_MODULE, .sendmsg = udp_sendmsg, .recvmsg = udp_recvmsg, };EXPORT_SYMBOL(udp_prot);
现在,转向一段发送 UDP 数据的用户程序,看内核是如何调用 udp_sendmsg 的!
套接字发送网络数据
用户程序想要发送 UDP 网络数据,因此它使用 sendto 系统调用,可能像这样:
ret = sendto(socket, buffer, buflen, 0, &dest, sizeof(dest));
此系统调用经过Linux 系统调用层,并落在./net/socket.c 中的这个函数:
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len, unsigned int, flags, struct sockaddr __user *, addr, int, addr_len){err = sock_sendmsg(sock, &msg, len);}
SYSCALL_DEFINE6 宏展开为一堆宏,这些宏反过来使用 6 个参数,建立基础结构来创建系统调用(因此是 DEFINE6)。 这样做的一个结果是,内核的系统调用函数名都有 sys_ 前缀。
sendto 的系统调用代码,组织数据为较低层能够处理的格式之后,调用 sock_sendmsg。 特别是,它将传递给 sendto 的目标地址构造一个结构,让我们来看一下:
iov.iov_base = buff;iov.iov_len = len;msg.msg_name = NULL;msg.msg_iov = &iov;msg.msg_iovlen = 1;msg.msg_control = NULL;msg.msg_controllen = 0;msg.msg_namelen = 0;if (addr) { err = move_addr_to_kernel(addr, addr_len, &address); if (err < 0) goto out_put; msg.msg_name = (struct sockaddr *)&address; msg.msg_namelen = addr_len;}
此段代码复制用户程序传入的 addr 到内核数据结构 address 中,然后以 msg_name 嵌入到 struct msghdr 结构中。 类似于 userland 程序不调用 sendto,而是直接调用 sendmsg 时所做的操作。内核提供此变化,是因为 sendto 和 sendmsg 都调用到 sock_sendmsg。
sock_sendmsg、__sock_sendmsg 和 __sock_sendmsg_nosec
在调用 __sock_sendmsg 之前,sock_sendmsg 会执行一些错误检查,而 __sock_sendmsg 在调用 __sock_sendmsg_nosec 之前也会进行自己的错误检查。__sock_sendmsg_nosec 传递数据到更深层的套接字子系统中。
static inline int __sock_sendmsg_nosec(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size){ struct sock_iocb *si = .... return sock->ops->sendmsg(iocb, sock, msg, size);}
如前一节解释套接字创建时所述,注册到此套接字 ops 结构的 sendmsg 函数是inet_sendmsg。
inet_sendmsg
从名字不难猜到,这是 AF_INET 协议族提供的一个通用函数。 此函数首先调用sock_rps_record_flow 记录最后一个处理流的 CPU;接收数据包转向会使用该信息。 接下来,查找并调用套接字的内部协议操作结构的 sendmsg 函数:
int inet_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size){ struct sock *sk = sock->sk; sock_rps_record_flow(sk); if (!inet_sk(sk)->inet_num && !sk->sk_prot->no_autobind && inet_autobind(sk)) return -EAGAIN; return sk->sk_prot->sendmsg(iocb, sk, msg, size);}EXPORT_SYMBOL(inet_sendmsg);
在处理 UDP 时,sk->sk_prot->sendmsg 指向 UDP 协议层 udp_sendmsg。 udp_sendmsg 是前面看到的 udp_prot 结构导出的。此函数调用从通用 AF_INET 协议族过渡到 UDP 协议栈。
UDP 协议层
udp_sendmsg
udp_sendmsg 函数位于 ./net/ipv4/udp.c。 整个函数相当长,因此我们将探讨其中的一些部分。 如果你想完整地阅读它,请点击前面的链接。
UDP corking
在变量声明和一些基本的错误检查之后,udp_sendmsg 要做的第一件事就是检查套接字是否“corked”。 UDP corking 是一项特性,允许用户程序请求内核累积多次 send 调用的数据到单个数据报中发送。 在用户程序中有两种方法可启用此选项:
- 使用
setsockopt 系统调用,传递 UDP_CORK 套接字选项。 - 调用
send、sendto 或 sendmsg 时,传递带有 MSG_MORE 的 flags 。
以上选项分别记录在 UDP 手册页 和 send / sendto / sendmsg 手册页 。
udp_sendmsg 检查 up->pending 以确定套接字当前是否被 corked。如果是,则直接追加数据。 稍后将看到如何追加数据。
int udp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t len){ fl4 = &inet->cork.fl.u.ip4; if (up->pending) { lock_sock(sk); if (likely(up->pending)) { if (unlikely(up->pending != AF_INET)) { release_sock(sk); return -EINVAL; } goto do_append_data; } release_sock(sk); }
获取 UDP 目标地址和端口
接下来,从两个可能的来源之一确定目标地址和端口:
- 套接字本身存储的目标地址,因为套接字在某个时间点已连接。
- 辅助结构传入的地址,正如在
sendto 的内核代码中看到的那样。
内核处理逻辑如下:
if (msg->msg_name) { struct sockaddr_in *usin = (struct sockaddr_in *)msg->msg_name; if (msg->msg_namelen < sizeof(*usin)) return -EINVAL; if (usin->sin_family != AF_INET) { if (usin->sin_family != AF_UNSPEC) return -EAFNOSUPPORT; } daddr = usin->sin_addr.s_addr; dport = usin->sin_port; if (dport == 0) return -EINVAL;} else { if (sk->sk_state != TCP_ESTABLISHED) return -EDESTADDRREQ; daddr = inet->inet_daddr; dport = inet->inet_dport; connected = 1;}
是的,UDP 协议层使用 TCP_ESTABLISHED! 不管怎样,套接字状态都使用 TCP 状态描述。
回想一下前面看到的,当用户程序调用 sendto 时,内核是如何代表用户组装一个 struct msghdr 结构。 上面的代码显示了内核解析该数据设置 daddr 和 dport。
当内核函数访问 udp_sendmsg 函数时,内核函数没有构造 struct msghdr 结构,则从套接字本身获取目标地址和端口,并标记套接字为“已连接”。
两种情况下,都设置 daddr 和 dport 为目标地址和端口。
套接字传输簿记和时间戳
接下来,获取并存储套接字上设置的源地址、设备索引和时间戳选项(如SOCK_TIMESTAMPING_TX_HARDWARE、SOCK_TIMESTAMPING_TX_SOFTWARE、SOCK_WIFI_STATUS):
ipc.addr = inet->inet_saddr;ipc.oif = sk->sk_bound_dev_if;sock_tx_timestamp(sk, &ipc.tx_flags);
sendmsg 发送辅助消息
除了发送或接收数据包之外,sendmsg 和 recvmsg 系统调用还允许用户设置或请求辅助数据。 用户程序可以创建一个嵌入了请求的 struct msghdr,来使用这些辅助数据。许多辅助数据类型都记录在 IP 手册页 中。
辅助数据的一个常见例子是 IP_PKTINFO。 在 sendmsg 的情况下,此数据类型允许程序设置 struct in_pktinfo,以便发送数据时使用。 通过在结构 struct in_pktinfo 中填充字段,程序可以指定要在数据包上使用的源地址。 如果程序是侦听多个 IP 地址的服务器程序,这是一个有用的选项。 在这种情况下,服务器程序可能希望使用与客户端连接服务器的 IP 地址来回复客户端。IP_PKTINFO 恰好适合这种情况。
类似地,当用户程序向 sendmsg 传递数据时, IP_TTL 和 IP_TOS 辅助消息允许用户在每个数据包的级别设置 IP 数据包的 TTL 和 TOS 值。如果需要,也可以通过使用 setsockopt 设置 IP_TTL 和 IP_TOS 在套接字级别,生效套接字的所有传出数据包。 Linux 内核使用数组转换指定的 TOS 值为优先级。 优先级影响数据包从排队规则传输的方式和时间。 稍后会详细了解这意味着什么。
内核如何处理 sendmsg 在 UDP 套接字上的辅助消息:
if (msg->msg_controllen) { err = ip_cmsg_send(sock_net(sk), msg, &ipc, sk->sk_family == AF_INET6); if (err) return err; if (ipc.opt) free = 1; connected = 0;}
./net/ipv4/ip_sockglue. c 中的 ip_cmsg_send 负责辅助消息的内部解析。 请注意,只要提供任何辅助数据,都会标记该套接字为未连接。
设置自定义 IP 选项
接下来,sendmsg 检查用户是否指定了任何带有自定义 IP 选项的辅助消息。 如果设置了选项,则使用这些选项。 如果没有,则使用此套接字已在使用的选项:
if (!ipc.opt) { struct ip_options_rcu *inet_opt; rcu_read_lock(); inet_opt = rcu_dereference(inet->inet_opt); if (inet_opt) { memcpy(&opt_copy, inet_opt, sizeof(*inet_opt) + inet_opt->opt.optlen); ipc.opt = &opt_copy.opt; } rcu_read_unlock();}
接下来,该函数检查是否设置了源记录路由(SRR)IP 选项。 源记录路由有两种类型:宽松源记录路由和严格源记录路由。 如果设置了此选项,记录并存储第一跳地址为 faddr,标记套接字为“未连接”。 faddr 将在后面用到:
ipc.addr = faddr = daddr;if (ipc.opt && ipc.opt->opt.srr) { if (!daddr) return -EINVAL; faddr = ipc.opt->opt.faddr; connected = 0;}
在处理 SRR 选项后,从用户辅助消息设置的值,或套接字当前使用的值中,获取 TOS IP 标志。 随后进行检查以确定:
- 套接字是否已设置(使用
setsockopt)SO_DONTROUTE ,或 - 调用
sendto 或 sendmsg 时,是否已指定 MSG_DONTROUTE 标志,或 - 是否已设置
is_strictroute ,代表需要严格源记录路由
然后,置位 tos 的 0x1(RTO_ONLINK)位,且标记套接字为“未连接”:
tos = get_rttos(&ipc, inet);if (sock_flag(sk, SOCK_LOCALROUTE) || (msg->msg_flags & MSG_DONTROUTE) || (ipc.opt && ipc.opt->opt.is_strictroute)) { tos |= RTO_ONLINK; connected = 0;}
组播还是单播?
接下来,代码尝试处理组播。 这有点棘手,因为如前所述,用户可以发送辅助 IP_PKTINFO 消息来指定一个源地址或设备索引来发送数据包。
如果目标地址是组播地址:
- 设置组播设备索引为数据包发送的设备索引,并且
- 设置组播源地址为数据包的源地址。
除非用户发送 IP_PKTINFO 辅助消息覆盖设备索引。 我们来看一下:
if (ipv4_is_multicast(daddr)) { if (!ipc.oif) ipc.oif = inet->mc_index; if (!saddr) saddr = inet->mc_addr; connected = 0;} else if (!ipc.oif) ipc.oif = inet->uc_index;
如果目标地址不是组播地址,则会设置设备索引,除非用户使用 IP_PKTINFO 覆盖了该索引。
路由
是时候探讨路由了!
UDP 层负责路由的代码从一个快速路径开始。如果套接字已连接,请尝试获取路由结构:
if (connected) rt = (struct rtable *)sk_dst_check(sk, 0);
如果套接字没有连接,或者虽然连接了,但路由助手 sk_dst_check 判定路由已淘汰,则代码进入慢速路径以生成路由结构。 首先调用 flowi4_init_output 来构造一个描述此 UDP 流的结构:
if (rt == NULL) { struct net *net = sock_net(sk); fl4 = &fl4_stack; flowi4_init_output(fl4, ipc.oif, sk->sk_mark, tos, RT_SCOPE_UNIVERSE, sk->sk_protocol, inet_sk_flowi_flags(sk)|FLOWI_FLAG_CAN_SLEEP, faddr, saddr, dport, inet->inet_sport);
一旦该流结构构造完成,套接字及其流结构就被传递到安全子系统,使得诸如 SELinux 或 SMACK 之类的系统可以在流结构上设置安全 id 值。 接下来,ip_route_output_flow 调用 IP 路由代码来生成此流的路由结构:
security_sk_classify_flow(sk, flowi4_to_flowi(fl4));rt = ip_route_output_flow(net, fl4, sk);
如果无法生成路由结构,并且错误为 ENETUNREACH,则 OUTNOROUTES 统计计数器增加。
if (IS_ERR(rt)) { err = PTR_ERR(rt); rt = NULL; if (err == -ENETUNREACH) IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES); goto out;}
保存上述统计计数器的文件的位置、其他计数器及其含义,将在下面的 UDP 监控章节中讨论。
接下来,如果路由用于广播,但是在套接字上没有设置 SOCK_BROADCAST 套接字选项,则代码终止。 如果套接字“已连接”(如本函数所述),则缓存路由结构到套接字:
err = -EACCES;if ((rt->rt_flags & RTCF_BROADCAST) && !sock_flag(sk, SOCK_BROADCAST)) goto out;if (connected) sk_dst_set(sk, dst_clone(&rt->dst));
使用 MSG_CONFIRM 阻止 ARP 缓存失效
在调用 send、sendto 或 sendmsg 时,如果用户指定了 MSG_CONFIRM 标志,UDP 协议层将处理该标志:
if (msg->msg_flags&MSG_CONFIRM) goto do_confirm;back_from_confirm:
此标志指示系统确认 ARP 缓存条目仍然有效,并阻止其被垃圾回收。 dst_confirm 函数只是在目标缓存条目上设置一个标志,在查询邻居缓存并找到条目时再次检查该标志。我们稍后再看。 UDP 网络应用程序常使用此功能 ,以减少不必要的 ARP 流量。 do_confirm 标签位于此函数的末尾附近,但它很简单:
do_confirm: dst_confirm(&rt->dst); if (!(msg->msg_flags&MSG_PROBE) || len) goto back_from_confirm; err = 0; goto out;
这段代码确认缓存条目,如果不是探测消息,则跳回到 back_from_confirm。
一旦 do_confirm 代码跳回到 back_from_confirm(或者没有跳转 do_confirm ),代码会尝试处理 UDP cork 和 uncorked 的情况。
uncorked UDP 套接字的快速路径:准备传输数据
如果未请求 UDP corking,调用 ip_make_skb ,数据可以打包到 struct sk_buff,并传递给 udp_send_skb,以向下移动栈并更接近 IP 协议层。 请注意,前面调用 ip_route_output_flow 生成的路由结构也会传入。 它将被关联到 skb,并稍后在 IP 协议层中使用。
if (!corkreq) { skb = ip_make_skb(sk, fl4, getfrag, msg->msg_iov, ulen, sizeof(struct udphdr), &ipc, &rt, msg->msg_flags); err = PTR_ERR(skb); if (!IS_ERR_OR_NULL(skb)) err = udp_send_skb(skb, fl4); goto out;}
ip_make_skb 函数尝试构建一个 skb,其考虑了各种因素,例如:
- MTU。
- UDP corking(如果启用)。
- UDP Fragmentation Offloading(UFO)。
- Fragmentation,如果不支持 UFO ,并且传输数据大于 MTU。
大多数网络设备驱动程序不支持 UFO,因为网络硬件本身不支持此功能。 让我们看一下这段代码,记住 corking 是禁用的。 接下来我们查看启用 corking 的路径。
ip_make_skb
ip_make_skb 函数可以在 ./net/ipv4/ip_output.c 中找到。 这个函数有点棘手。 ip_make_skb 依赖底层代码(译者释:__ip_make_skb)构建 skb,它需要传入一个 corking 结构和 skb 排队的队列。 在套接字没有 corked 的情况下,传入一个伪 corking 结构和空队列。
让我们来看看伪 corking 结构和队列是如何构造的:
struct sk_buff *ip_make_skb(struct sock *sk, ){ struct inet_cork cork; struct sk_buff_head queue; int err; if (flags & MSG_PROBE) return NULL; __skb_queue_head_init(&queue); cork.flags = 0; cork.addr = 0; cork.opt = NULL; err = ip_setup_cork(sk, &cork, ); if (err) return ERR_PTR(err);
如上所述,corking 结构(cork)和队列(queue)都在栈上分配的;当 ip_make_skb 完成时,两者都不再需要。 调用 ip_setup_cork 来构建伪 corking 结构,它分配内存、并初始化结构。 接下来,调用 __ip_append_data,传入队列和 corking 结构:
err = __ip_append_data(sk, fl4, &queue, &cork, ¤t->task_frag, getfrag, from, length, transhdrlen, flags);
稍后我们将看到这个函数是如何工作的,因为它在套接字是否被 corked 的情况下都会使用。 现在,我们只需要知道 __ip_append_data 会创建一个 skb,向其追加数据,并添加该 skb 到传入的队列中。 如果追加数据失败,则调用 __ip_flush_pending_frame 静默丢弃数据,并向上返回错误码:
if (err) { __ip_flush_pending_frames(sk, &queue, &cork); return ERR_PTR(err);}
最后,如果没有错误发生,__ip_make_skb 出队队列中的 skb,添加 IP 选项,并返回一个 skb,该 skb 已准备好传递给底层发送:
return __ip_make_skb(sk, fl4, &queue, &cork);
传输数据!
如果没有发生错误,则 skb 会交给 udp_send_skb,它传递 skb 到网络栈的下一层,即 IP 协议栈:
err = PTR_ERR(skb);if (!IS_ERR_OR_NULL(skb)) err = udp_send_skb(skb, fl4);goto out;
如果出现错误,将在稍后计数。 有关详细信息,请参阅 UDP corking 的“错误统计”部分。
corked UDP 套接字的慢速路径:没有预先存在的 corked 数据
如果正在使用 UDP corking,但没有预先存在的 corked 数据,则慢速路径开始:
- 锁定套接字。
- 检查应用程序缺陷:corked 套接字被 “re-corked”。
- 准备此 UDP 流的流结构,以进行 corking。
- 追加要发送的数据到现有数据。
你可以在下一段代码中看到这一点,udp_sendmsg 继续向下:
lock_sock(sk); if (unlikely(up->pending)) { release_sock(sk); LIMIT_NETDEBUG(KERN_DEBUG pr_fmt("cork app bug 2\n")); err = -EINVAL; goto out; } fl4 = &inet->cork.fl.u.ip4; fl4->daddr = daddr; fl4->saddr = saddr; fl4->fl4_dport = dport; fl4->fl4_sport = inet->inet_sport; up->pending = AF_INET;do_append_data: up->len += ulen; err = ip_append_data(sk, fl4, getfrag, msg->msg_iov, ulen, sizeof(struct udphdr), &ipc, &rt, corkreq ? msg->msg_flags|MSG_MORE : msg->msg_flags);
ip_append_data
ip_append_data 是一个小的包装函数,它在调用 __ip__append_data 之前做两件主要事情:
- 检查用户是否传入了
MSG_PROBE 标志。 此标志表示用户不想真正发送数据。 应探测路径(例如,以确定 PMTU)。 - 检查套接字的发送队列是否为空。 如果是,意味着没有待处理的 corking 数据,因此调用
ip_setup_cork 来设置 corking。
处理完上述条件后,就会调用 __ip_append_data 函数,该函数包含大量逻辑以处理数据为数据包。
__ip_append_data
如果套接字被 corked,则从 ip_append_data 调用该函数;如果套接字未被 corked ,则从 ip_make_skb 调用该函数。 在这两种情况下,该函数要么分配一个新的缓冲区来存储传入的数据,要么追加数据到现有数据中。
这种工作方式以套接字的发送队列为中心。 等待发送的现有数据(例如,如果套接字被 corked)在队列中有一个条目,可以在其中追加其他数据。
这个函数很复杂;它执行多轮计算,以确定如何构建传递给底层网络层的 skb,并且详细探讨缓冲器分配过程对于理解如何传输网络数据并非绝对必要。
该函数的重点包括:
- 处理 UDP fragmentation offloading(UFO)(如果硬件支持)。 绝大多数网络硬件不支持 UFO。 如果您的网卡驱动程序支持,它将设置功能标志
NETIF_F_UFO。 - 处理支持 分散/聚集 IO 的网卡。 许多卡都支持此功能,并使用
NETIF_F_SG 功能标志进行通告。 该功能的可用性表明,网络卡能够处理数据分散在一组缓冲区中的数据包;内核不需要花费时间合并多个缓冲区为单个缓冲区。期望的是结果避免额外的复制,大多数网卡都支持该功能。 - 调用
sock_wmalloc 跟踪发送队列的大小。 当分配一个新的 skb 时,skb 的大小会被计入拥有它的套接字,并且套接字的发送队列的分配字节会增加。 如果发送队列中没有足够的空间,则不分配 skb,并返回并跟踪错误。 我们将在下面的调优部分看到如何设置套接字发送队列大小。 - 增加错误统计信息。 此函数中的任何错误都将增加 “discard”。 我们将在下面的监控部分看到如何读取这个值。
此函数执行成功后,将返回 0。此时传输的数据已组装成适合网络设备的 skb,等待在发送队列上。
在 uncorked 的情况下,持有 skb 的队列传递给上述的 __ip_make_skb,在那里它出队并准备经由 udp_send_skb 发送到更低层。
在 corked 的情况下,向上传递 __ip_append_data 的返回值。 数据停留在发送队列中,直到udp_sendmsg 确定是时候调用 udp_push_pending_frames 确认 skb 并调用 udp_send_skb。
刷新 corked 套接字
现在,udp_sendmsg 继续检查 ___ip_append_skb 的返回值 (下面的 err ):
if (err) udp_flush_pending_frames(sk);else if (!corkreq) err = udp_push_pending_frames(sk);else if (unlikely(skb_queue_empty(&sk->sk_write_queue))) up->pending = 0;release_sock(sk);
让我们来看看每个分支:
- 如果出现错误(
err 非零),则调用 udp_flush_pending_frames,从而取消阻塞并从套接字的发送队列中删除所有数据。 - 如果发送此数据时未指定
MSG_MORE,则称为 udp_push_pending_frames,它尝试传递数据到较低的网络层。 - 如果发送队列为空,则标记套接字为不再阻塞。
如果 append 操作成功完成,并且还有更多的数据要 cork,则代码继续清理并返回所追加的数据的长度:
ip_rt_put(rt);if (free) kfree(ipc.opt);if (!err) return len;
这就是内核处理 corked 的 UDP 套接字的方式。
错误统计
如果:
- non-corking 快速路径无法创建 skb 或
udp_send_skb 报告错误,或 ip_append_data 无法追加数据到 corked 的 UDP 套接字,或- 在尝试传输 corked skb 时,
udp_push_pending_frames 返回从 udp_send_skb 收到的错误
只有当收到的错误是 ENOBUFS(没有可用的内核内存)或套接字设置了 SOCK_NOSPACE(发送队列已满)时,SNDBUFERRORS 统计信息才会增加:
if (err == -ENOBUFS || test_bit(SOCK_NOSPACE, &sk->sk_socket->flags)) { UDP_INC_STATS_USER(sock_net(sk), UDP_MIB_SNDBUFERRORS, is_udplite);}return err;
我们将在下面的监控部分看到如何读取这些计数。
udp_send_skb
udp_sendmsg 调用 udp_send_skb 函数 最终下推 skb 到网络栈的下一层,在本例中是 IP 协议层。 该函数做了几件重要的事情:
- 添加 UDP 报头到 skb。
- 处理校验和:软件校验和、硬件校验和或无校验和(如果禁用)。
- 尝试调用
ip_send_skb 发送 skb 到 IP 协议层。 - 增加传输成功或失败的统计计数器。
我们来看看。 首先,创建 UDP 报头:
static int udp_send_skb(struct sk_buff *skb, struct flowi4 *fl4){ uh = udp_hdr(skb); uh->source = inet->inet_sport; uh->dest = fl4->fl4_dport; uh->len = htons(len); uh->check = 0;
接下来,处理校验和。 有几种情况:
- 首先处理 UDP-Lite 校验和。
- 接下来,如果套接字被设置为不生成校验和(通过
setsockopt 设置 SO_NO_CHECK),将如此标记 skb。 - 接下来,如果硬件支持 UDP 校验和,调用
udp4_hwcsum 来设置。 请注意,如果数据包被分段,内核将在软件中生成校验和。 您可以在 udp4_hwcsum 的源代码中看到这一点。 - 最后,调用
udp_csum 生成软件校验和。
if (is_udplite) csum = udplite_csum(skb);else if (sk->sk_no_check == UDP_CSUM_NOXMIT) { skb->ip_summed = CHECKSUM_NONE; goto send;} else if (skb->ip_summed == CHECKSUM_PARTIAL) { udp4_hwcsum(skb, fl4->saddr, fl4->daddr); goto send;} else csum = udp_csum(skb);
接下来,添加 psuedo 报头:
uh->check = csum_tcpudp_magic(fl4->saddr, fl4->daddr, len, sk->sk_protocol, csum);if (uh->check == 0) uh->check = CSUM_MANGLED_0;
如果校验和为 0,则根据 RFC 768 设置其等效的补码值为校验和。最终,skb 被传递到 IP 协议栈,增加统计信息:
send: err = ip_send_skb(sock_net(sk), skb); if (err) { if (err == -ENOBUFS && !inet->recverr) { UDP_INC_STATS_USER(sock_net(sk), UDP_MIB_SNDBUFERRORS, is_udplite); err = 0; } } else UDP_INC_STATS_USER(sock_net(sk), UDP_MIB_OUTDATAGRAMS, is_udplite); return err;
如果 ip_send_skb 执行成功,则增加 OUTDATAGRAMS 统计信息。 如果 IP 协议层报告错误,则增加 SNDBUFERRORS,但仅当错误为 ENOBUFS(内核内存不足)且未启用错误队列时,才增加。
在讨论 IP 协议层之前,让我们先看看如何在 Linux 内核中监控和调优 UDP 协议层。
监控:UDP 协议层统计信息
获取 UDP 协议统计信息的两个非常有用的文件是:
/proc/net/snmp/proc/net/udp
/proc/net/snmp
读取 /proc/net/snmp 监控详细的 UDP 协议统计信息。
$ cat /proc/net/snmp | grep Udp\:Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrorsUdp: 16314 0 0 17161 0 0
为了准确地理解这些统计信息在哪里增加,您需要仔细阅读内核源代码。 在一些情况下,一些错误会计入多个统计量中。
InDatagrams:当用户程序使用 recvmsg 读取数据报时增加。 当 UDP 数据包被封装并发回处理时,也会增加。NoPorts:当 UDP 数据包到达目的地为没有程序侦听的端口时增加。InErrors:在以下几种情况下增加:接收队列中没有内存,当看到错误的校验和时,sk_add_backlog 无法添加数据报。OutDatagrams:当 UDP 数据包无错误地传递到要发送的 IP 协议层时增加。RcvbufErrors:当 sock_queue_rcv_skb 报告没有可用内存时增加;如果 sk->sk_rmem_alloc 大于等于 sk->sk_rcvbuf 就会发生这种情况。SndbufErrors:如果 IP 协议层在尝试发送数据包时报告错误,并且没有设置错误队列,则会增加。 如果没有可用的发送队列空间或内核内存,也会增加。InCsumErrors:检测到 UDP 校验和失败时增加。 请注意,在我能找到的所有情况下,InCsumErrors 与 InErrors 会同时增加。 因此,InErrors-InCsumErros 应当得出接收端的内存相关错误的计数。
请注意,UDP 协议层发现的一些错误会报告到其他协议层的统计信息文件。 举个例子:路由错误。 udp_sendmsg 发现的路由错误将增加 IP 协议层的 OutNoRoutes 统计信息。
/proc/net/udp
读取 /proc/net/udp 监控 UDP 套接字统计信息
$ cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 515: 00000000:B346 00000000:0000 07 00000000:00000000 00:00000000 00000000 104 0 7518 2 0000000000000000 0 558: 00000000:0371 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7408 2 0000000000000000 0 588: 0100007F:038F 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7511 2 0000000000000000 0 769: 00000000:0044 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7673 2 0000000000000000 0 812: 00000000:006F 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7407 2 0000000000000000 0
第一行描述后续行中的每个字段:
sl:套接字的内核哈希槽local_address:套接字的十六进制本地地址和端口号,以 :分隔。rem_address:套接字的十六进制远程地址和端口号,以 : 分隔。st:套接字的状态。 奇怪的是,UDP 协议层似乎使用了一些 TCP 套接字状态。 在上面的例子中,7 是 TCP_CLOSE。tx_queue:内核中为传出 UDP 数据报分配的内存量。rx_queue:内核中为传入 UDP 数据报分配的内存量。tr,tm->when,retrnsmt:UDP 协议层未使用这些字段。uid:创建此套接字的用户的有效用户 ID。timeout:UDP 协议层未使用。inode:与此套接字对应的 inode 编号。 您可以使用它来帮助您确定哪个用户进程打开了此套接字。 检查 /proc/[pid]/fd,它将包含到 socket:[inode] 的符号链接。ref:套接字的当前引用计数。pointer:内核中 struct sock 的内存地址。drops:与此套接字关联的数据报丢弃数。 请注意,这不包括任何与发送数据报有关的丢弃(在 corked 的 UDP 套接字上,或其他);在本博客考察的内核版本中,只在接收路径中增加。
可以在 net/ipv4/udp.c 中找到输出此内容的代码。
调优:套接字发送队列内存
发送队列(也称为写入队列)的最大大小可以设置 net.core.wmem_max sysctl 来调整
设置 sysctl 增加最大发送缓冲区大小。
$ sudo sysctl -w net.core.wmem_max=8388608
sk->sk_write_queue 从 net.core.wmem_default 值开始,也可以设置 sysctl 来调整,如下所示:
设置 sysctl 来调整默认的初始发送缓冲区大小 。
$ sudo sysctl -w net.core.wmem_default=8388608
您还可以从应用程序调用 setsockopt 并传递 SO_SNDBUF 来设置 sk->sk_write_queue 大小 。 您可以使用 setsockopt 设置的最大值是 net.core.wmem_max。
但是,当运行应用程序的用户具有 CAP_NET_ADMIN 权限时,可以调用 setsockopt 并传递 SO_SNDBUFFORCE 来覆盖 net.core.wmem_max 限制。
每次调用 ip_append_data 分配 skb 时,sk->sk_wmem_alloc 都会增加。 正如我们将看到的,UDP 数据报传输很快,通常不会在发送队列中花费太多时间。
IP 协议层
UDP 协议层简单地调用 ip_send_skb 传递 skbs 给 IP 协议,因此让我们从那开始,并掌握 IP 协议层!
ip_send_skb
ip_send_skb 函数位于 ./net/ipv4/ip_output.c 中,非常短。 它只是向下调用 ip_local_out,如果 ip_local_out 返回某种错误,它就会增加错误统计信息。 我们来看一下:
int ip_send_skb(struct net *net, struct sk_buff *skb){ int err; err = ip_local_out(skb); if (err) { if (err > 0) err = net_xmit_errno(err); if (err) IP_INC_STATS(net, IPSTATS_MIB_OUTDISCARDS); } return err;}
如上所述,调用 ip_local_out,然后处理返回值。 调用 net_xmit_errno “翻译” 来自底层的错误为 IP 和 UDP 协议层可以理解的错误。 如果发生错误,将增加 IP 协议统计信息 “OutDiscards” 。 稍后我们将看到获得此统计信息要读取哪些文件。 现在,让我们继续探索,看看 ip_local_out 会把我们带到哪里。
ip_local_out 和 __ip_local_out
幸运的是,ip_local_out 和 __ip_local_out 都很简单。ip_local_out 只是向下调用 __ip_local_out,并根据返回值调用路由层发送数据包:
int ip_local_out(struct sk_buff *skb){ int err; err = __ip_local_out(skb); if (likely(err == 1)) err = dst_output(skb); return err;}
可以从 __ip_local_out 的源代码中看到,该函数首先做了两件重要的事情:
- 设置 IP 数据包的长度
- 调用
ip_send_check 计算要写入 IP 数据包报头的校验和。 ip_send_check 函数调用 ip_fast_csum 来计算校验和。 在 x86 和 x86_64 体系结构上,此功能以汇编实现。 你可以在这里阅读 64 位的实现,在这里阅读 32 位的实现。
接下来,IP 协议层调用 nf_hook 向下调用 netfilter。传回 nf_hook 函数的返回值给 ip_local_out。 如果 nf_hook 返回 1,表明允许数据包通过,调用者应该自己传递它。 正如我们在上面看到的,实际正是如此:ip_local_out 检查返回值 1,并调用 dst_output 传递数据包。 让我们来看看 __ip_local_out 的代码:
int __ip_local_out(struct sk_buff *skb){ struct iphdr *iph = ip_hdr(skb); iph->tot_len = htons(skb->len); ip_send_check(iph); return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, skb, NULL, skb_dst(skb)->dev, dst_output);}
netfilter 和 nf_hook
简洁起见,我决定跳过对 netfilter、iptables 和 conntrack 的深入研究。 你可以从 这里 和 这里 开始深入了解 netfilter 的源代码。
简版:nf_hook 是一个包装器,它调用 nf_hook_thresh,首先检查指定的协议族和钩子类型(在本例中分别为 NFPROTO_IPV4 和 NF_INET_LOCAL_OUT)是否安装了过滤器,并试图返回执行流程到 IP 协议层,以避免深入 netfilter 和在其下面的钩子,如 iptables 和 conntrack。
请记住:如果你有很多或非常复杂的 netfilter 或 iptables 规则,这些规则将在启动原始 sendmsg 调用的用户进程的 CPU 上下文中执行。 如果您设置了 CPU pinning 以限制此进程的执行到特定的 CPU(或一组 CPU),请注意 CPU 将花费系统时间处理出站 iptables 规则。 根据系统的工作负载,如果您在这里测量性能回归,您可能需要小心地固定进程到 CPU 或降低规则集的复杂性。
为了便于讨论,我们假设 nf_hook 返回 1 表示调用方(在本例中是 IP 协议层)应该自己传递数据包。
目标缓存
在 Linux 内核中,dst 代码实现了协议无关的目标缓存。 为了理解如何设置 dst 条目以继续发送 UDP 数据报,我们需要简要地探讨一下 dst 条目和路由是如何生成的。 目标缓存、路由和邻居子系统都可以单独进行极其详细的探讨。 出于我们的目的,我们可以快速查看一下这一切是如何结合在一起的。
我们上面看到的代码调用了 dst_output(skb)。 这个函数只是查找 skb 附加的 dst 条目 skb 并调用 output 函数。 我们来看一下:
static inline int dst_output(struct sk_buff *skb){ return skb_dst(skb)->output(skb);}
看起来很简单,但 output 函数起初是如何被关联到 dst 条目的呢?
重要的是要了解,有许多不同的方式添加目标缓存条目。 到目前为止,我们在代码路径中看到的一种方式是从 udp_sendmsg 调用 ip_route_output_flow。 ip_route_output_flow 函数调用 __ip_route_output_key,后者调用 __mkroute_output。 __mkroute_output 函数创建路由和目标缓存条目。 当它执行时,它会确定适合于此目标的输出函数。 大多数时候,这个函数是 ip_output。
ip_output
因此,dst_output 执行 output 函数,在 UDP IPv4 情况下为 ip_output。 ip_output 函数很简单:
int ip_output(struct sk_buff *skb){ struct net_device *dev = skb_dst(skb)->dev; IP_UPD_PO_STATS(dev_net(dev), IPSTATS_MIB_OUT, skb->len); skb->dev = dev; skb->protocol = htons(ETH_P_IP); return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, skb, NULL, dev, ip_finish_output, !(IPCB(skb)->flags & IPSKB_REROUTED));}
首先,更新统计计数器 IPSTATS_MIB_OUT。 IP_UPD_PO_STATS 宏增加字节数和数据包数。 我们将在后面的部分中看到如何获得 IP 协议层统计信息以及它们各自的含义。 接下来,设置传输此 skb 的设备、协议。
最后,调用 NF_HOOK_COND 传递控制权给 netfilter。 查看 NF_HOOK_COND 的函数原型有助于更清楚地解释它的工作原理。 来源为 ./include/linux/netfilter.h:
static inline intNF_HOOK_COND(uint8_t pf, unsigned int hook, struct sk_buff *skb, struct net_device *in, struct net_device *out, int (*okfn)(struct sk_buff *), bool cond)
NF_HOOK_COND 检查传入的条件。 在此情况下,条件是 !(IPCB(skb)->flags & IPSKB_REROUTED。 如果条件为真,那么传递 skb 给 netfilter。 如果 netfilter 允许数据包通过,则调用 okfn。 此情况下,okfn 是 ip_finish_output。
ip_finish_output
ip_finish_output函数也很简洁明了。 我们来看一下:
static int ip_finish_output(struct sk_buff *skb){#if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM) if (skb_dst(skb)->xfrm != NULL) { IPCB(skb)->flags |= IPSKB_REROUTED; return dst_output(skb); }#endif if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb)) return ip_fragment(skb, ip_finish_output2); else return ip_finish_output2(skb);}
如果在此内核中启用了 netfilter 和数据包转换,会更新 skb 的标志,并通过 dst_output 将其发送回。 两种比较常见的情况是:
- 如果数据包的长度大于 MTU,并且数据包的分段不会卸载到设备,则调用
ip_fragment 以在传输之前对数据包进行分段。 - 否则,直接传递数据包到
ip_finish_output2。
在继续内核学习之前,让我们稍微绕个圈子来讨论一下路径 MTU 发现。
路径 MTU 发现
Linux 提供了一个我前面避免提到的特性:路径 MTU 发现。 此功能允许内核自动确定特定路由的最大 MTU。 确定此值并发送小于或等于路由 MTU 的数据包意味着可以避免 IP 分段。 这是首选设置,因为数据包分段会消耗系统资源,而且似乎很容易避免:简单地发送足够小的数据包,就不需要分段。
调用 setsockopt,您可以在应用程序中使用 SOL_IP 级别和 IP_MTU_DISCOVER optname 调整每个套接字的路径 MTU 发现设置。optval 可以是 IP 协议手册页中描述的几个值之一。 您可能希望设置的值为:IP_PMTUDISC_DO 表示“始终执行路径 MTU 发现”。 更高级的网络应用程序或诊断工具可以选择自己实现 RFC 4821 ,以在应用程序启动时确定特定路由的 PMTU。 在这种情况下,您可以使用 IP_PMTUDISC_PROBE 选项,该选项告诉内核设置“Don’t Fragment”位,允许您发送大于 PMTU 的数据。
调用 getsockopt,您的应用程序可以使用 SOL_IP 和 IP_MTU optname 来检索 PMTU。 您可以使用它来帮助指导应用程序尝试在传输之前构造 UDP 数据报的大小。
如果已启用 PTMU 发现,则任何发送大于 PMTU 的 UDP 数据的尝试都将导致应用程序收到错误码 EMSGSIZE。 然后,应用程序可以使用更少的数据重试。
强烈建议启用 PTMU 发现,因此我将避免详细描述 IP 分段代码路径。 当查看 IP 协议层统计信息时,我将解释所有统计信息,包括与分段相关的统计信息。 其中许多在 ip_fragment。 无论是否分段,都调用了 ip_finish_output2,所以让我们继续。
ip_finish_output2
ip_finish_output2 在 IP 分段之后被调用,并且也直接从 ip_finish_output 调用。 在向下传递数据包到邻居缓存之前,此函数增加各种统计计数器。 让我们看看它是如何工作的:
static inline int ip_finish_output2(struct sk_buff *skb){ if (rt->rt_type == RTN_MULTICAST) { IP_UPD_PO_STATS(dev_net(dev), IPSTATS_MIB_OUTMCAST, skb->len); } else if (rt->rt_type == RTN_BROADCAST) IP_UPD_PO_STATS(dev_net(dev), IPSTATS_MIB_OUTBCAST, skb->len); if (unlikely(skb_headroom(skb) < hh_len && dev->header_ops)) { struct sk_buff *skb2; skb2 = skb_realloc_headroom(skb, LL_RESERVED_SPACE(dev)); if (skb2 == NULL) { kfree_skb(skb); return -ENOMEM; } if (skb->sk) skb_set_owner_w(skb2, skb->sk); consume_skb(skb); skb = skb2; }
如果与此数据包相关联的路由结构是组播类型,使用IP_UPD_PO_STATS 宏来增加 OutMcastPkts 和 OutMcastOctets 计数器。 否则,如果路由类型为广播,则增加 OutBcastPkts 和 OutBcastOctets 计数器。
接下来,执行检查以确保 skb 结构具有足够的空间添加任何需要的链路层报头。 如果没有,则调用 skb_realloc_headroom 来分配额外的空间,并且新 skb 的成本将计入相关套接字。
rcu_read_lock_bh();nexthop = (__force u32) rt_nexthop(rt, ip_hdr(skb)->daddr);neigh = __ipv4_neigh_lookup_noref(dev, nexthop);if (unlikely(!neigh)) neigh = __neigh_create(&arp_tbl, &nexthop, dev, false);
继续,我们可以看到,下一跳是查询路由层,然后查找邻居缓存得到的。 如果找不到邻居,则调用 __neigh_create 创建一个。 例如,数据第一次发送到另一台主机时可能出现此情况。 请注意,此函数是调用 arp_tbl(在 ./net/ipv4/arp.c 中定义),在 ARP 表中创建邻居条目。 其他系统(如 IPv6 或 DECnet)维护自己的 ARP 表,并传递不同的结构给 __neigh_create。 本文并不旨在全面介绍邻居缓存,但如果必须创建邻居缓存,那么创建可能会导致缓存增长。 这篇文章将在下面的章节中介绍更多关于邻居缓存的细节。 无论如何,邻居缓存导出自己的统计信息,以便可以测量缓存增长。 有关详细信息,请参阅下面的监控部分。
if (!IS_ERR(neigh)) { int res = dst_neigh_output(dst, neigh, skb); rcu_read_unlock_bh(); return res; } rcu_read_unlock_bh(); net_dbg_ratelimited("%s: No header cache and no neighbour!\n", __func__); kfree_skb(skb); return -EINVAL;}
最后,如果没有返回错误,则调用 dst_neigh_output 沿着输出的旅程传递 skb。 否则,释放 skb 并返回 EINVAL。 此处的错误将产生连锁反应,并增加 ip_send_skb 中的 OutDiscards。 让我们继续探索 dst_neigh_output,并继续接近 Linux 内核的网络设备子系统。
dst_neigh_output
dst_neigh_output 函数为我们做了两件重要的事情。 首先,回想一下在这篇博客文章的前面,我们看到如果用户通过辅助消息指定 MSG_CONFIRM 给 sendmsg 函数,则会翻转一个标志,指示远程主机的目标缓存条目仍然有效,不应被垃圾回收。 该检查在这里发生,设置邻居的 confirmed 字段为当前的 jiffies 计数。
static inline int dst_neigh_output(struct dst_entry *dst, struct neighbour *n, struct sk_buff *skb){ const struct hh_cache *hh; if (dst->pending_confirm) { unsigned long now = jiffies; dst->pending_confirm = 0; if (n->confirmed != now) n->confirmed = now; }
其次,检查邻居的状态,并调用适当的输出函数。 让我们来看看以下条件句,试着理解是怎么回事:
hh = &n->hh; if ((n->nud_state & NUD_CONNECTED) && hh->hh_len) return neigh_hh_output(hh, skb); else return n->output(n, skb);}
如果邻居被认为是 NUD_CONNECTED,则意味着它是以下情况的一种或多种:
NUD_PERMANENT:静态路由。NUD_NOARP:不需要 ARP 请求(例如,目的地是组播或广播地址,或环回设备)。NUD_REACHABLE:邻居是“可达的”。只要 ARP 请求 成功处理,目的地就会被标记为可达。
且 “硬件头”(hh)已缓存(因为之前发送过数据并已生成它),则调用 neigh_hh_output。否则,调用 output 函数。两条代码路径都以 dev_queue_xmit 结束,它传递 skb 到 Linux 网络设备子系统,在到达设备驱动程序层之前会进行更多处理。让我们跟随 neigh_hh_output 和 n->output 代码路径,直至 dev_queue_xmit。
neigh_hh_output
如果目标是 NUD_CONNECTED,并且硬件头已缓存,则调用 neigh_hh_output ,它在移交skb 给 dev_queue_xmit 之前执行一小段处理逻辑。 让我们从 ./include/net/neighbor.h 来看看:
static inline int neigh_hh_output(const struct hh_cache *hh, struct sk_buff *skb){ unsigned int seq; int hh_len; do { seq = read_seqbegin(&hh->hh_lock); hh_len = hh->hh_len; if (likely(hh_len <= HH_DATA_MOD)) { memcpy(skb->data - HH_DATA_MOD, hh->hh_data, HH_DATA_MOD); } else { int hh_alen = HH_DATA_ALIGN(hh_len); memcpy(skb->data - hh_alen, hh->hh_data, hh_alen); } } while (read_seqretry(&hh->hh_lock, seq)); skb_push(skb, hh_len); return dev_queue_xmit(skb);}
这个函数有点难以理解,部分原因是同步读/写已缓存硬件头的锁定原语。 这段代码使用了一种叫做 seqlock 的东西。 你可以把上面的 do { } while() 循环想象成一种简单的重试机制,它将尝试执行循环中的操作,直到成功执行为止。
循环本身试图确定在复制之前是否需要对齐硬件头部的长度。 这是必需的,因为某些硬件报头(如 IEEE 802.11 报头)大于 HH_DATA_MOD(16 字节)。
一旦数据被复制到 skb,并且 skb_push 更新了 skb 的内部指针跟踪数据,skb 就会传递给 dev_queue_xmit 进入 Linux 网络设备子系统。
n->output
如果目标不是 NUD_CONNECTED 或硬件头尚未缓存,则代码沿着 n->output 路径继续。 邻居结构的输出函数指针关联了什么 output? 嗯,那要看情况了。 为了理解这是如何设置的,我们需要了解更多关于邻居缓存的工作原理。
一个 struct neighbour 包含几个重要的字段。 上面看到的 nud_state 字段,output 函数和 ops 结构。 回想一下之前看到的,如果在缓存中没有找到现有的条目,则从 ip_finish_output2 调用 __neigh_create。 当调用 __neigh_creaet 时,邻居被分配,其 output 函数初始设置为 neigh_blackhole。 随着 __neigh_create 代码执行,它根据邻居的状态调整 output 的值以指向适当的 output 函数。
例如,当代码确定要连接的邻居时,neigh_connect 设置 output 指针为 neigh->ops->connected_output。 或者,在代码怀疑邻居可能关闭时(例如,如果自发送探测以来已经超过/proc/sys/net/ipv4/neigh/default/delay_first_probe_time 秒),neigh_suspect 设置 output 指针为 neigh->ops->output。
换句话说:neigh->output 设置为 neigh->ops_connected_output 还是 neigh->ops->output, 取决于邻居的状态。 neigh->ops 从何而来?
在分配邻居之后,arp_constructor(来自 ./net/ipv4/arp.c)被调用来设置 struct neighbour 的一些字段。 特别地,此函数检查与邻居相关联的设备,并且如果该设备暴露包含cache(以太网设备这样做)函数的 header_ops 结构 ,则 neigh->ops 被设置为 ./net/ipv4/arp. c 中定义的以下结构:
static const struct neigh_ops arp_hh_ops = { .family = AF_INET, .solicit = arp_solicit, .error_report = arp_error_report, .output = neigh_resolve_output, .connected_output = neigh_resolve_output,};
因此,无论邻居缓存代码是否视邻居为 “已连接”或“可疑”,都将关联 neigh_resolve_output 函数到 neigh->output,并且在调用 n->output 时被调用。
neigh_resolve_output
此函数的目的是尝试解析未连接的邻居,或已连接但没有缓存硬件头的邻居。 让我们来看看这个函数是如何工作的:
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb){ struct dst_entry *dst = skb_dst(skb); int rc = 0; if (!dst) goto discard; if (!neigh_event_send(neigh, skb)) { int err; struct net_device *dev = neigh->dev; unsigned int seq;
代码首先执行一些基本检查,然后继续调用 neigh_event_send。 neigh_event_send 函数是__neigh_event_send 的简单包装。__neigh_event_send 实际完成解析邻居的繁重工作。 您可以在 ./net/core/neighbor.c 中阅读 __neigh_event_send 的源代码,但从代码中可以看出,用户最感兴趣的有三点:
- 假设
/proc/sys/net/ipv4/neigh/default/app_solicit /proc/sys/net/ipv4/neigh/default/mcast_solicit 中设置的值允许发送探测,则 NUD_NONE 状态(分配时的默认状态)的邻居将立即发送 ARP 请求(如果不允许,则标记状态为 NUD_FAILED)。 邻居状态被更新并设置为 NUD_INCOMPLETE。 - 更新状态为
NUD_STALE 的邻居为 NUD_DELAYED,并设置一个计时器以稍后探测它们(稍后:当前时间 +/proc/sys/net/ipv4/neigh/default/delay_first_probe_time 秒)。 - 检查
NUD_INCOMPLETE 的任何邻居 (包括上面第一点),以确保未解析邻居的排队数据包数量小于等于 /proc/sys/net/ipv4/neigh/default/unres_qlen。 如果有更多的数据包,则将数据包出队并丢弃,直到长度低于等于 proc 中的值。针对此类情况,邻居缓存统计中的统计计数器都将增加。
如果需要立刻发送 ARP 探测,它就会发送。__neigh_event_send 将返回 0,指示邻居被视为“已连接”或“已延迟”的,否则返回 1。 返回值 0 允许 neigh_resolve_output 函数继续执行:
if (dev->header_ops->cache && !neigh->hh.hh_len) neigh_hh_init(neigh, dst);
如果邻居关联的设备的协议实现(在此例子中是以太网)支持缓存硬件报头,并且它当前没有被缓存,则调用 neigh_hh_init 缓存它。
do { __skb_pull(skb, skb_network_offset(skb)); seq = read_seqbegin(&neigh->ha_lock); err = dev_hard_header(skb, dev, ntohs(skb->protocol), neigh->ha, NULL, skb->len);} while (read_seqretry(&neigh->ha_lock, seq));
接下来,使用 seqlock 同步访问邻居结构的硬件地址,当尝试为 skb 创建以太网报头时,dev_hard_header 将读取该地址。 一旦 seqlock 允许继续执行,就会进行错误检查:
if (err >= 0) rc = dev_queue_xmit(skb); else goto out_kfree_skb;}
如果以太网头被写入而没有返回错误,则 skb 被传递到 dev_queue_xmit,以通过 Linux 网络设备子系统进行传输。 如果有错误,goto 将丢弃 skb,设置返回代码并返回错误:
out: return rc;discard: neigh_dbg(1, "%s: dst=%p neigh=%p\n", __func__, dst, neigh);out_kfree_skb: rc = -EINVAL; kfree_skb(skb); goto out;}EXPORT_SYMBOL(neigh_resolve_output);
在进入 Linux 网络设备子系统前,让我们看一下一些监控和调优 IP 协议层的文件。
监控:IP 协议层
/proc/net/snmp
读取 /proc/net/snmp 监控详细的 IP 协议统计信息。
$ cat /proc/net/snmpIp: Forwarding DefaultTTL InReceives InHdrErrors InAddrErrors ForwDatagrams InUnknownProtos InDiscards InDelivers OutRequests OutDiscards OutNoRoutes ReasmTimeout ReasmReqds ReasmOKs ReasmFails FragOKs FragFails FragCreatesIp: 1 64 25922988125 0 0 15771700 0 0 25898327616 22789396404 12987882 51 1 10129840 2196520 1 0 0 0...
此文件包含多个协议层的统计信息。 首先显示 IP 协议层。第一行包含空格分隔的名称,每个名称对应下一行中的相应值。
在 IP 协议层中,您会发现统计计数器正在增加。计数器引用 C 枚举类型。 /proc/net/snmp 所有有效的枚举值和它们对应的字段名称可以在 include/uapi/linux/snmp.h 中找到:
enum{ IPSTATS_MIB_NUM = 0, IPSTATS_MIB_INPKTS, IPSTATS_MIB_INOCTETS, IPSTATS_MIB_INDELIVERS, IPSTATS_MIB_OUTFORWDATAGRAMS, IPSTATS_MIB_OUTPKTS, IPSTATS_MIB_OUTOCTETS,
一些有趣的统计数据:
OutRequests:每次尝试发送 IP 数据包时增加。 看起来,每次是否成功,都会增加此值。OutDiscards:每次丢弃 IP 数据包时增加。 如果数据追加到 skb(对于 corked 的套接字)失败,或者 IP 下面的层返回错误,就会发生这种情况。OutNoRoute:在多个位置增加,例如在 UDP 协议层(udp_sendmsg),如果无法为给定目标生成路由。 当应用程序在 UDP 套接字上调用 “connect” 但找不到路由时也会增加。FragOKs:每个被分段的数据包增加一次。 例如,被分割成 3 个片段的数据包增加该计数器一次。FragCreates:每个创建的片段增加一次。 例如,被分割成 3 个片段的数据包增加该计数器三次。FragFails:如果尝试分段,但不允许分段,则增加(因为设置了 “Don’t Fragment” 位)。 如果输出片段失败,也会增加。
其他统计数据记录在接收端博客文章中。
/proc/net/netstat
读取 /proc/net/netstat 监控扩展 IP 协议统计信息。
$ cat /proc/net/netstat | grep IpExtIpExt: InNoRoutes InTruncatedPkts InMcastPkts OutMcastPkts InBcastPkts OutBcastPkts InOctets OutOctets InMcastOctets OutMcastOctets InBcastOctets OutBcastOctets InCsumErrors InNoECTPkts InECT0Pktsu InCEPktsIpExt: 0 0 0 0 277959 0 14568040307695 32991309088496 0 0 58649349 0 0 0 0 0
格式类似于 /proc/net/snmp,不同之处在于行的前缀是 IpExt。
一些有趣的统计数据:
OutMcastPkts:每次发送目的地为组播地址的数据包时增加。OutBcastPkts:每次发送目的地为广播地址的数据包时增加。OutOctects:输出的数据包字节数。OutMcastOctets:输出的组播数据包字节数。OutBcastOctets:输出的广播数据包字节数。
其他统计数据记录在接收端博客文章中。
请注意,这些值都是在 IP 层的特定位置增加的。代码有时会移动,可能会出现双重计数错误或其他统计错误。如果这些统计数据对您很重要,强烈建议您阅读 IP 协议层源代码,了解您重要的指标何时增加(或不增加)。
Linux 网络设备子系统
在我们继续讨论 dev_queue_xmit 的数据包传输路径之前,让我们花一点时间来谈谈一些重要的概念,这些概念将出现在接下来的部分。
Linux 流量控制
Linux 支持一种叫做流量控制的特性。 此功能允许系统管理员控制如何从计算机传输数据包。 本文不会深入讨论 Linux 流量控制的各方面的细节。这篇文档提供了对系统、其控制和特性的深入研究。 有几个概念值得一提,以使下面看到的代码更容易理解。
流量控制系统包含几种不同的排队系统,它们为控制流量提供不同的功能。单个排队系统通常称为 qdisc,也称为排队规则。您可以将 qdisc 视为调度程序;qdisc 决定何时以及如何传输数据包。
在 Linux 上,每个接口都有一个与之关联的默认 qdisc。对于仅支持单个传输队列的网络硬件,使用默认 qdisc pfifo_fast。支持多个传输队列的网络硬件使用默认 qdisc mq。您可以运行 tc qdisc 来检查您的系统。
还需要注意的是,有些设备支持硬件流量控制,这可以让管理员将流量控制卸载到网络硬件上,从而节省系统上的 CPU 资源。
现在这些想法已经介绍过了,让我们从 ./net/core/dev.c 继续沿着 dev_queue_xmit 进行。
dev_queue_xmit 和 __dev_queue_xmit
dev_queue_xmit 是 __dev_queue_xmit 的一个简单包装:
int dev_queue_xmit(struct sk_buff *skb){ return __dev_queue_xmit(skb, NULL);}EXPORT_SYMBOL(dev_queue_xmit);
在此之后,__dev_queue_xmit 是完成繁重工作的地方。 让我们一步一步地看一下这段代码,继续:
static int __dev_queue_xmit(struct sk_buff *skb, void *accel_priv){ struct net_device *dev = skb->dev; struct netdev_queue *txq; struct Qdisc *q; int rc = -ENOMEM; skb_reset_mac_header(skb); rcu_read_lock_bh(); skb_update_prio(skb);
上面的代码开始于:
- 声明变量。
- 调用
skb_reset_mac_header 来准备要处理的 skb。 这将重置 skb 的内部指针,以便可以访问以太网报头。 - 调用
rcu_read_lock_bh 来准备读取 RCU 保护的数据结构。阅读更多关于安全使用 RCU 的信息。 - 如果正在使用网络优先级 cgroup,调用
skb_update_prio 来设置 skb 的优先级。
现在,我们将开始更复杂的数据传输部分 ;)
txq = netdev_pick_tx(dev, skb, accel_priv);
在这里,代码试图确定要使用哪个传输队列。 正如您将在本文后面看到的,一些网络设备公开了多个传输队列来传输数据。 让我们来详细看看这是如何工作的。
netdev_pick_tx
netdev_pick_tx 代码位于 ./net/core/flow_dissector.c 中。 我们来看一下:
struct netdev_queue *netdev_pick_tx(struct net_device *dev, struct sk_buff *skb, void *accel_priv){ int queue_index = 0; if (dev->real_num_tx_queues != 1) { const struct net_device_ops *ops = dev->netdev_ops; if (ops->ndo_select_queue) queue_index = ops->ndo_select_queue(dev, skb, accel_priv); else queue_index = __netdev_pick_tx(dev, skb); if (!accel_priv) queue_index = dev_cap_txqueue(dev, queue_index); } skb_set_queue_mapping(skb, queue_index); return netdev_get_tx_queue(dev, queue_index);}
正如您在上面看到的,如果网络设备只支持单个传输队列,则会跳过更复杂的代码,并返回单个传输队列。 在高端服务器上使用的大多数设备具有多个传输队列。 具有多个传输队列的设备有两种情况:
- 驱动程序实现
ndo_select_queue,它可以以硬件或功能特定的方式更智能地选择传输队列,或者 - 驱动程序没有实现
ndo_select_queue,所以内核应该自己选择设备。
截止 3.13 内核,实现 ndo_select_queue 的驱动程序并不多。 bnx2x 和 ixgbe 驱动程序实现了此功能,但它仅用于以太网光纤通道(FCoE)。 鉴于此,让我们假设网络设备不实现ndo_select_queue 和/或 FCoE 未被使用。 在这种情况下,内核将选择具有 __netdev_pick_tx。
一旦 __netdev_pick_tx 确定了队列的索引,skb_set_queue_mapping 将缓存该值(稍后将在流量控制代码中使用),netdev_get_tx_queue 将查找并返回指向该队列的指针。 在回到 __dev_queue_xmit 之前,让我们看看 __netdev_pick_tx 是如何工作 。
__netdev_pick_tx
让我们来看看内核如何选择传输队列来传输数据。 来自 ./net/core/flow_dissector.c:
u16 __netdev_pick_tx(struct net_device *dev, struct sk_buff *skb){ struct sock *sk = skb->sk; int queue_index = sk_tx_queue_get(sk); if (queue_index < 0 || skb->ooo_okay || queue_index >= dev->real_num_tx_queues) { int new_index = get_xps_queue(dev, skb); if (new_index < 0) new_index = skb_tx_hash(dev, skb); if (queue_index != new_index && sk && rcu_access_pointer(sk->sk_dst_cache)) sk_tx_queue_set(sk, new_index); queue_index = new_index; } return queue_index;}
代码首先调用 sk_tx_queue_get 检查传输队列是否已经缓存在套接字上。如果没有缓存,则返回 -1。
下一个 if 语句检查以下任一项是否为真:
- queue_index 小于 0。 如果尚未设置队列,则会发生这种情况。
ooo_okay 标志置位 。 如果设置了该标志,则意味着现在允许乱序数据包。 协议层必须适当地设置此标志。 在流的所有未完成数据包都已确认时,TCP 协议层会设置此标志。 当这种情况发生时,内核可以为该数据包选择不同的传输队列。 UDP 协议层不设置此标志-因此 UDP 数据包永远不会设置 ooo_okay 为非零值。- 队列索引大于队列数。 如果用户最近通过
ethtool 更改了设备上的队列计数,则可能会发生这种情况。 稍后会详细介绍。
以上任一情况下,代码都会进入慢速路径以获取传输队列。首先调用 get_xps_queue,它试图使用用户配置映射传输队列到 CPU。这称为“Transmit Packet Steering(XPS)”。我们稍后将更详细地了解 Transmit Packet Steering(XPS) 是什么以及它是如何工作的。
如果 get_xps_queue 返回 -1,则此内核不支持 XPS,或系统管理员未配置 XPS,或配置的映射指向无效队列,则代码将继续调用 skb_tx_hash。
一旦使用 XPS 或内核自动使用 skb_tx_hash 选择了队列,将使用 sk_tx_queue_set 缓存该队列到套接字对象上,并返回。在继续 dev_queue_xmit 之前,让我们看看 XPS 和 skb_tx_hash 是如何工作的。
Transmit Packet Steering(XPS)
Transmit Packet Steering(XPS)是一项特性,允许系统管理员确定哪些 CPU 可以处理设备的哪些传输队列的传输操作。此功能的主要目的是避免在处理传输请求时出现锁争用。使用 XPS 时,还期望获得其他好处,如减少缓存驱逐和避免在 NUMA 机器 上进行远程内存访问。
您可以 查看 XPS 的内核文档 来了解更多关于 XPS 如何工作的信息。我们将在下面研究如何为您的系统调整 XPS,但现在,您需要知道的是,要配置 XPS,系统管理员可以定义一个位图,映射传输队列到 CPU。
上面代码中调用 get_xps_queue 函数将查询此用户指定的映射,以确定应使用哪个传输队列。如果 get_xps_queue 返回 -1,则将改用 skb_tx_hash。
skb_tx_hash
如果内核未包含 XPS,或未配置 XPS,或建议的队列不可用(可能是因为用户调整了队列计数),则 skb_tx_hash 接管以确定发送数据到哪个队列。根据传输工作负载,准确了解 skb_tx_hash 工作原理非常重要。 请注意,这段代码已经随着时间的推移进行了调整,因此如果您使用的内核版本与本文档不同,您应该直接查阅您的内核源代码。
让我们看看它是如何工作的,来自 ./include/linux/netdevice.h:
static inline u16 skb_tx_hash(const struct net_device *dev, const struct sk_buff *skb){ return __skb_tx_hash(dev, skb, dev->real_num_tx_queues);}
代码只是调用 __skb_tx_hash,来自 ./net/core/flow_dissector.c。这个函数中有一些有趣的代码,让我们来看看:
u16 __skb_tx_hash(const struct net_device *dev, const struct sk_buff *skb, unsigned int num_tx_queues){ u32 hash; u16 qoffset = 0; u16 qcount = num_tx_queues; if (skb_rx_queue_recorded(skb)) { hash = skb_get_rx_queue(skb); while (unlikely(hash >= num_tx_queues)) hash -= num_tx_queues; return hash; }
函数中的第一个 if 语句是一个有趣的短路。函数名 skb_rx_queue_recorded 有些误导。skb 有一个 queue_mapping 字段,用于 rx 和 tx。无论如何,如果您的系统正在接收数据包,并转发它们到其他地方,则此 if 语句为真。如果不是这种情况,则代码继续。
if (dev->num_tc) { u8 tc = netdev_get_prio_tc_map(dev, skb->priority); qoffset = dev->tc_to_txq[tc].offset; qcount = dev->tc_to_txq[tc].count;}
要理解这段代码,重要的是要提到程序可以设置套接字发送数据的优先级。这可以使用 setsockopt 与 SOL_SOCKET 和 SO_PRIORITY 级别和 optname 分别完成。有关 SO_PRIORITY 的更多信息,请参阅 socket(7) 手册页。
请注意,如果您在应用程序中使用了 setsockopt 选项 IP_TOS 来设置特定套接字发送的 IP 数据包的 TOS 标志(或者如果作为辅助消息传递给 sendmsg 则按每个数据包设置),则内核转换您设置的 TOS 选项为优先级,最终进入 skb->priority。
如前所述,某些网络设备支持基于硬件的流量控制系统。如果 num_tc 非零,则表示此设备支持基于硬件的流量控制。
如果该数字非零,则表示此设备支持基于硬件的流量控制。将查询优先级映射,优先级映射映射数据包优先级到基于硬件的流量控制。根据此映射为数据优先级选择适当的流量类别。
接下来,将生成适合流量类别的传输队列范围。它们将确定传输队列。
如果 num_tc 为零(因为网络设备不支持基于硬件的流量控制),则 qcount 和 qoffset 变量分别设置为传输队列数和 0。
使用 qcount 和 qoffset,可以计算传输队列的索引:
if (skb->sk && skb->sk->sk_hash) hash = skb->sk->sk_hash; else hash = (__force u16) skb->protocol; hash = __flow_hash_1word(hash); return (u16) (((u64) hash * qcount) >> 32) + qoffset;}EXPORT_SYMBOL(__skb_tx_hash);
最后,返回适当的队列索引到 __netdev_pick_tx。
恢复 __dev_queue_xmit
此时,已选择适当的传输队列。__dev_queue_xmit 可以继续:
q = rcu_dereference_bh(txq->qdisc);#ifdef CONFIG_NET_CLS_ACT skb->tc_verd = SET_TC_AT(skb->tc_verd, AT_EGRESS);#endif trace_net_dev_queue(skb); if (q->enqueue) { rc = __dev_xmit_skb(skb, q, dev, txq); goto out; }
它首先获得与此队列相关联的排队规则的引用。回想一下,我们之前看到,对于单个传输队列设备,默认值是 pfifo_fast qdisc,而对于多队列设备,它是 mq qdisc。
接下来,如果在内核中启用了数据包分类 API,则代码会为传出数据分配一个流量分类“决定”。接下来,检查排队规则是否有方法将数据排队。像 noqueue qdisc 这样的一些排队规则没有队列。如果有队列,则代码调用 __dev_xmit_skb 来继续处理要传输的数据。之后,执行跳转到此函数的结尾。我们稍后将看一下 __dev_xmit_skb。现在,让我们看看如果没有队列会发生什么,从一个非常有用的注释开始:
if (dev->flags & IFF_UP) { int cpu = smp_processor_id();
正如注释所示,唯一可以拥有不带队列的 qdisc 的设备是环回设备和隧道设备。 如果设备当前已启动,则保存当前 CPU。 它用于下一项检查,这有点棘手,让我们来看看:
if (txq->xmit_lock_owner != cpu) { if (__this_cpu_read(xmit_recursion) > RECURSION_LIMIT) goto recursion_alert;
此处有两个分支:该设备队列上的传输锁是否由该 CPU 拥有。 如果是,则在此处检查为每个 CPU 分配的计数器变量 xmit_recursion,以确定计数是否超过 RECURSION_LIMIT。 一个程序可能试图发送数据,并在代码中的这个地方被抢占。 调度程序可以选择另一个程序来运行。 如果第二个程序也试图发送数据并运行到这里。 因此,xmit_recursion 计数器防止超过RECURSION_LIMIT 程序此处竞争传输数据。 让我们继续:
HARD_TX_LOCK(dev, txq, cpu); if (!netif_xmit_stopped(txq)) { __this_cpu_inc(xmit_recursion); rc = dev_hard_start_xmit(skb, dev, txq); __this_cpu_dec(xmit_recursion); if (dev_xmit_complete(rc)) { HARD_TX_UNLOCK(dev, txq); goto out; } } HARD_TX_UNLOCK(dev, txq); net_crit_ratelimited("Virtual device %s asks to queue packet!\n", dev->name); } else { recursion_alert: net_crit_ratelimited("Dead loop on virtual device %s, fix it urgently!\n", dev->name); } }
代码的其余部分首先尝试获取传输锁。检查要使用的设备的传输队列,以查看是否停止传输。如果没有,则增加 xmit_recursion 变量,并传递数据到更靠近设备的位置进行传输。我们稍后会更详细地看到 dev_hard_start_xmit。完成后,释放锁并打印警告。
另外,如果当前 CPU 是传输锁所有者,或者如果达到了 RECURSION_LIMIT,则不进行传输,但会打印警告。函数中剩余的代码设置错误码并返回。
由于我们对真实以太网设备感兴趣,因此让我们继续沿着前面 __dev_xmit_skb 为那些设备所采用的代码路径。
__dev_xmit_skb
现在我们从 ./net/core/dev. c 进入 __dev_xmit_skb,并配备了排队规则、网络设备和传输队列引用:
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq){ spinlock_t *root_lock = qdisc_lock(q); bool contended; int rc; qdisc_pkt_len_init(skb); qdisc_calculate_pkt_len(skb, q); contended = qdisc_is_running(q); if (unlikely(contended)) spin_lock(&q->busylock);
这段代码首先使用 qdisc_pkt_len_init 和 qdisc_calculate_pkt_len 计算 qdisc 稍后将使用的数据的准确长度。 这对于基于硬件的发送卸载(例如 UDP 分段卸载,如我们之前所看到的)的 skb 是必要的,因为需要考虑在分段发生时添加的附加报头。
接下来,使用一把锁来帮助减少 qdisc 主锁(稍后我们将看到第二把锁)的竞争。 如果 qdisc 当前正在运行,则其他试图传输的程序将竞争 qdisc 的 busylock。 使得运行中的 qdisc 处理数据包,并与较少数量的程序竞争第二把主锁。 该技巧减少了竞争者的数量,从而增加了吞吐量。 你可以在 这里 阅读描述这一点的原始提交消息。 接下来,主锁被占用:
spin_lock(root_lock);
现在,我们接近一个 if 语句,它处理 3 种可能的情况:
- qdisc 已停用。
- qdisc 允许数据包绕过排队系统,且没有其他数据包要发送,且 qdisc 当前未运行。 qdisc 变为 “工作节省” qdisc ,允许数据包绕过 —— 换句话说,流量整形目的的 qdisc 不延迟数据包传输。
- 所有其他情况。
让我们来看看在这些情况下会发生什么,从停用的 qdisc 开始:
if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) { kfree_skb(skb); rc = NET_XMIT_DROP;
这是直截了当的。 如果 qdisc 已停用,请释放数据并设置返回码为 NET_XMIT_DROP。 接下来,qdisc 允许数据包旁路,没有其他未完成的数据包,且 qdisc 当前未运行:
} else if ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) && qdisc_run_begin(q)) { if (!(dev->priv_flags & IFF_XMIT_DST_RELEASE)) skb_dst_force(skb); qdisc_bstats_update(q, skb); if (sch_direct_xmit(skb, q, dev, txq, root_lock)) { if (unlikely(contended)) { spin_unlock(&q->busylock); contended = false; } __qdisc_run(q); } else qdisc_run_end(q); rc = NET_XMIT_SUCCESS;
这个 if 语句有点棘手。 如果以下所有条件均为 true,则整个语句的计算结果为真:
q->flags & TCQ_F_CAN_BYPASS:qdisc 允许数据包绕过排队系统。 这对于“工作节省”的 qdisc 是 true;即,出于流量整形目的而不延迟数据包传输的 qdisc 被认为是 “工作节省” 的,并且允许数据包绕过。 pfifo_fast qdisc 允许数据包绕过排队系统。!qdisc_qlen(q):qdisc 的队列中没有等待传输的数据。qdisc_run_begin(p):此函数调用设置 qdisc 的状态为 “running” 并返回 true,如果 qdisc 已经在运行则返回 false。
如果上述所有值均为 true,则:
- 检查
IFF_XMIT_DST_RELEASE 标志。 如果启用,此标志表示允许内核释放 skb 的目标缓存结构。 此函数中的代码检查标志是否被禁用,并强制对该结构进行引用计数。 qdisc_bstats_update 增加 qdisc 发送的字节数和数据包数。sch_direct_xmit 尝试发送数据包。 我们将很快深入研究 sch_direct_xmit,因为它也用于较慢的代码路径中。
在两种情况下检查 sch_direct_xmit 的返回值:
- 队列不为空(返回
> 0 )。在这种情况下,会释放防止其他程序争用的锁,并调用__qdisc_run 重新启动 qdisc 处理。 - 队列为空(返回
0)。在这种情况下,调用 qdisc_run_end 关闭 qdisc 处理。
在这两种情况下,返回值 NET_XMIT_SUCCESS 都被设置为返回码。 还不算太糟。 让我们看看最后一个分支,即捕获所有情况:
} else { skb_dst_force(skb); rc = q->enqueue(skb, q) & NET_XMIT_MASK; if (qdisc_run_begin(q)) { if (unlikely(contended)) { spin_unlock(&q->busylock); contended = false; } __qdisc_run(q); }}
在所有其他情况下:
- 调用
skb_dst_force 强制增加 skb 的目标缓存引用计数。 - 调用 qdisc 的
enqueue 函数排队数据到 qdisc。 存储返回码。 - 调用
qdisc_run_begin(p) 标记 qdisc 为正在运行。 如果尚未运行,则释放 busylock 并调用 __qdisc_run(p) 来启动 qdisc 处理。
然后,该函数释放一些锁,并返回返回码:
spin_unlock(root_lock);if (unlikely(contended)) spin_unlock(&q->busylock);return rc;
调优:Transmit Packet Steering(XPS)
要使 XPS 工作,必须在内核配置中启用它(在 Ubuntu 的内核 3.13.0 上是启用的),并且需要一个位掩码来描述哪些 CPU 应该处理给定接口和传输队列的数据包。
这些位掩码类似于 RPS 位掩码,您可以在内核文档中找到关于这些位掩码的一些 文档。
简而言之,要修改的位掩码位于:
/sys/class/net/DEVICE_NAME/queues/QUEUE/xps_cpus
因此,对于 eth0 和传输队列 0,您需要修改文件:/sys/class/net/eth0/queues/tx-0/xps_cpus,其中十六进制数指示哪些 CPU 应处理来自 eth0 的传输队列 0 的传输完成。 正如文档所指出的,XPS 在某些配置中可能是不必要的。
排队规则!
要了解网络数据的路径,我们需要稍微了解一下 qdisc 代码。本文不打算涵盖每个不同传输队列选项的具体细节。 如果你对此感兴趣,请查看这本优秀的指南。
在这篇博客文章中,我们将继续代码路径,研究通用包调度器代码是如何工作的。 特别是,我们将探索 qdisc_run_begin、qdisc_run_end、__qdisc_run 和 sch_direct_xmit 如何移动网络数据到更靠近传输驱动程序的位置。
让我们先看看 qdisc_run_begin 是如何工作的,并从那里开始。
qdisc_run_begin 和 qdisc_run_end
qdisc_run_begin 函数可以在 ./include/net/sch_generic.h 中找到:
static inline bool qdisc_run_begin(struct Qdisc *qdisc){ if (qdisc_is_running(qdisc)) return false; qdisc->__state |= __QDISC___STATE_RUNNING; return true;}
这个函数很简单:检查 qdisc 的 __state 标志。 如果它已经在运行,则返回 false。 否则,更新 __state 以启用 __QDISC___STATE_RUNNING 位。
同样,qdisc_run_end 也是寡淡的:
static inline void qdisc_run_end(struct Qdisc *qdisc){ qdisc->__state &= ~__QDISC___STATE_RUNNING;}
它只是禁用 qdisc __state 字段中的 __QDISC__STATE_RUNNING 位。 需要注意的是,这两个函数都只是翻转位;自己既不实际开始,也不停止处理。 另一方面,函数 __qdisc_run 实际上开始处理。
__qdisc_run
__qdisc_run 看起来很简短:
void __qdisc_run(struct Qdisc *q){ int quota = weight_p; while (qdisc_restart(q)) { if (--quota <= 0 || need_resched()) { __netif_schedule(q); break; } } qdisc_run_end(q);}
该函数首先获取 weight_p 值。 该值通常是 sysctl 设置的,也会在接收路径中使用。我们稍后会看到如何调整这个值。 这个循环做两件事:
- 它在一个繁忙的循环中调用
qdisc_restart,直到返回 false(或者触发下面的 break)。 - 确定配额是否降至零以下或
need_resched() 返回 true。 如果其中一个为 true,则调用 __netif_schedule 并中断循环。
记住:到现在为止,内核仍然在执行代表用户程序对 sendmsg 的原始调用;用户程序当前正在累积系统时间。 如果用户程序已经用完了内核中的时间配额,那么 need_resched 将返回 true。 如果仍然有可用的配额,并且用户程序尚未使用完其时间片,qdisc_restart 将再次被调用。
让我们看看 qdisc_restart(q) 是如何工作的,然后我们将深入研究 __netif_schedule(q)。
qdisc_restart
让我们跳到 qdisc_restart 的代码中:
static inline int qdisc_restart(struct Qdisc *q){ struct netdev_queue *txq; struct net_device *dev; spinlock_t *root_lock; struct sk_buff *skb; skb = dequeue_skb(q); if (unlikely(!skb)) return 0; WARN_ON_ONCE(skb_dst_is_noref(skb)); root_lock = qdisc_lock(q); dev = qdisc_dev(q); txq = netdev_get_tx_queue(dev, skb_get_queue_mapping(skb)); return sch_direct_xmit(skb, q, dev, txq, root_lock);}
qdisc_restart 函数以一个有用的注释开始,该注释描述了调用此函数的一些加锁约束。 此函数执行的第一个操作是尝试从 qdisc 出队 skb。
函数 dequeue_skb 尝试获得下一个要传输的数据包。 如果队列为空 qdisc_restart 将返回 false(导致 __qdisc_run 退出)。
假设存在要传输的数据,则代码继续获取 qdisc 队列锁、qdisc 的关联设备和传输队列的引用。
所有这些都会传递到 sch_direct_xmit。 让我们先看一下 dequeue_skb,然后再看 sch_direct_xmit。
dequeue_skb
让我们看一下 ./net/sched/sch_generic.c 中的 dequeue_skb。 此函数处理两种主要情况:
- 将之前无法发送而重新排队的数据出队,或
- 将要处理的新数据从 qdisc 出队。
我们来看一下第一个案例:
static inline struct sk_buff *dequeue_skb(struct Qdisc *q){ struct sk_buff *skb = q->gso_skb; const struct netdev_queue *txq = q->dev_queue; if (unlikely(skb)) { txq = netdev_get_tx_queue(txq->dev, skb_get_queue_mapping(skb)); if (!netif_xmit_frozen_or_stopped(txq)) { q->gso_skb = NULL; q->q.qlen--; } else skb = NULL;
请注意,该代码首先引用 qdisc 的 gso_skb 字段。 此字段保存重新排队的数据的引用。 如果未重新排队数据,则此字段将为 NULL。 如果该字段不为 NULL,则代码继续获取数据的传输队列并检查队列是否停止。 如果队列没有停止,则清除 gso_skb 字段,并且减少队列长度计数器。 如果队列停止,数据仍然关联到 gso_skb,但此函数将返回 NULL。
让我们检查下一个案例,其中没有重新排队的数据:
} else { if (!(q->flags & TCQ_F_ONETXQUEUE) || !netif_xmit_frozen_or_stopped(txq)) skb = q->dequeue(q); } return skb;}
在没有数据被重新排队的情况下,另一个复杂的复合 if 语句被求值。 如果:
- qdisc 没有单个传输队列,或者
- 传输队列未停止
然后,调用 qdisc 的 dequeue 函数以获取新数据。 dequeue 的内部实现根据 qdisc 的实现和特性而有所不同。
该函数以返回待处理的数据结束。
sch_direct_xmit
现在我们来看看 sch_direct_xmit(在 ./net/sched/sch_generic.c 中),它是向下移动数据到网络设备的重要参与者。 让我们一点一点地来看看:
int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, struct net_device *dev, struct netdev_queue *txq, spinlock_t *root_lock){ int ret = NETDEV_TX_BUSY; spin_unlock(root_lock); HARD_TX_LOCK(dev, txq, smp_processor_id()); if (!netif_xmit_frozen_or_stopped(txq)) ret = dev_hard_start_xmit(skb, dev, txq); HARD_TX_UNLOCK(dev, txq);
该代码首先释放 qdisc 锁,然后锁定传输锁。 注意,HARD_TX_LOCK 是一个宏:
#define HARD_TX_LOCK(dev, txq, cpu) { \ if ((dev->features & NETIF_F_LLTX) == 0) { \ __netif_tx_lock(txq, cpu); \ } \}
此宏检查设备功能标志中是否设置了 NETIF_F_LLTX 标志。 此标志已弃用,新设备驱动程序不应使用此标志。 此内核版本中的大多数驱动程序都不使用此标志,因此此检查将评估为 true,并将获得此数据的传输队列的锁。
接下来,检查传输队列以确保它没有停止,然后调用 dev_hard_start_xmit。 我们将在后面看到,dev_hard_start_xmit 从 Linux 内核的网络设备子系统转换网络数据到设备驱动程序本身以进行传输。 存储此函数的返回码,然后检查该返回码以确定传输是否成功。
一旦这已经运行(或者由于队列停止而被跳过),则释放队列的传输锁。 让我们继续:
spin_lock(root_lock);if (dev_xmit_complete(ret)) { ret = qdisc_qlen(q);} else if (ret == NETDEV_TX_LOCKED) { ret = handle_dev_cpu_collision(skb, txq, q);
接下来,再次获取此 qdisc 的锁,然后检查 dev_hard_start_xmit。 第一种情况是调用 dev_xmit_complete 检查,它只是检查返回值以确定数据是否成功发送。 如果是,则设置 qdisc 队列长度为返回值。
如果 dev_xmit_complete 返回 false,则将检查返回值以查看 dev_hard_start_xmit 是否从设备驱动程序返回 NETDEV_TX_LOCKED。 当驱动程序尝试自己锁定传输队列并失败时,具有不推荐使用的 NETIF_F_LLTX 功能标志的设备可以返回 NETDEV_TX_LOCKED。 在这种情况下,调用 handle_dev_cpu_collision 来处理锁竞争。 我们稍后会仔细研究 handle_dev_cpu_collision,但现在,让我们继续 sch_direct_xmit 并查看捕获所有的分支:
} else { if (unlikely(ret != NETDEV_TX_BUSY)) net_warn_ratelimited("BUG %s code %d qlen %d\n", dev->name, ret, q->q.qlen); ret = dev_requeue_skb(skb, q);}
因此,如果驱动程序没有传输数据,并且传输锁未被持有,则可能是由于 NETDEV_TX_BUSY (如果没有打印警告)。NETDEV_TX_BUSY 可以由驱动程序返回,以指示设备或驱动程序“忙碌”并且现在不能传输数据。 在本例中,调用 dev_requeue_skb 将要重试的数据重新入队。
该函数(可能)调整返回值来结束:
if (ret && netif_xmit_frozen_or_stopped(txq)) ret = 0;return ret;
让我们深入了解 handle_dev_cpu_collision 和 dev_requeue_skb。
handle_dev_cpu_collision
来自 ./net/sched/sch_generic.c 的代码 handle_dev_cpu_collision 处理两种情况:
- 传输锁由当前 CPU 持有。
- 传输锁由其他 CPU 持有。
在第一种情况下,这被作为配置问题处理,因此打印警告。 在第二种情况下,增加统计计数器cpu_collision,并且数据经 dev_requeue_skb 发送,以便稍后重新排队传输。 回想一下,我们在 dequeue_skb 中看到的专门处理重新排队的 skb 代码。
handle_dev_cpu_collision 的代码很短,值得快速阅读:
static inline int handle_dev_cpu_collision(struct sk_buff *skb, struct netdev_queue *dev_queue, struct Qdisc *q){ int ret; if (unlikely(dev_queue->xmit_lock_owner == smp_processor_id())) { kfree_skb(skb); net_warn_ratelimited("Dead loop on netdevice %s, fix it urgently!\n", dev_queue->dev->name); ret = qdisc_qlen(q); } else { __this_cpu_inc(softnet_data.cpu_collision); ret = dev_requeue_skb(skb, q); } return ret;}
让我们来看看 dev_requeue_skb 做了什么,因为我们将看到这个函数是从 sch_direct_xmit 调用的。
dev_requeue_skb
值得庆幸的是,dev_requeue_skb 的源代码很短,而且直截了当,来自 ./net/sched/sch_generic.c:
static inline int dev_requeue_skb(struct sk_buff *skb, struct Qdisc *q){ skb_dst_force(skb); q->gso_skb = skb; q->qstats.requeues++; q->q.qlen++; __netif_schedule(q); return 0;}
这个函数做了几件事:
- 它强制增加 skb 引用计数。
- 它关联 skb 到 qdisc 的
gso_skb 字段。 回想一下,我们之前看到,在从 qdisc 的队列中取出数据之前,会在 dequeue_skb 中检查此字段。 - 增加统计计数器。
- 增加队列的大小。
- 调用
__netif_schedule。
简单明了。 让我们回顾一下我们是如何到达这里的,然后探讨 __netif_schedule。
提醒, __qdisc_run 中的 while 循环
回想一下,我们是检查函数 __qdisc_run 得出的这一点,该函数包含以下代码:
void __qdisc_run(struct Qdisc *q){ int quota = weight_p; while (qdisc_restart(q)) { if (--quota <= 0 || need_resched()) { __netif_schedule(q); break; } } qdisc_run_end(q);}
这段代码的工作原理是在一个循环中反复调用 qdisc_restart,在内部,它会使 skb 出队,并试图调用 sch_direct_xmit 来传输 skb,而 sch_direct_xmit 会调用 dev_hard_start_xmit 来执行实际的传输。 任何不能传输的内容都将在 NET_TX 软中断中重新排队以进行传输。
传输过程中的下一步是检查 dev_hard_start_xmit,以了解如何调用驱动程序来发送数据。 在此之前,我们应该研究 __netif_schedule 以完全理解 __qdisc_run 和 dev_requeue_skb 是如何工作的。
__netif_schedule
让我们从 ./net/core/dev.c 跳到 __netif_schedule:
void __netif_schedule(struct Qdisc *q){ if (!test_and_set_bit(__QDISC_STATE_SCHED, &q->state)) __netif_reschedule(q);}EXPORT_SYMBOL(__netif_schedule);
此代码检查并设置 qdisc 状态的 __QDISC_STATE_SCHED 位。 如果该位被翻转(意味着它之前没有处于 __QDISC_STATE_SCHED 状态),代码将调用 __netif_reschedule,这并不长,但有非常有趣的附带作用。 我们来看一下:
static inline void __netif_reschedule(struct Qdisc *q){ struct softnet_data *sd; unsigned long flags; local_irq_save(flags); sd = &__get_cpu_var(softnet_data); q->next_sched = NULL; *sd->output_queue_tailp = q; sd->output_queue_tailp = &q->next_sched; raise_softirq_irqoff(NET_TX_SOFTIRQ); local_irq_restore(flags);}
此函数执行以下操作:
- 保存当前的本地 IRQ 状态,并调用
local_irq_save 禁用 IRQ。 - 获取当前 CPU
softnet_data 结构。 - 添加 qdisc 到
softnet_data 的输出队列。 - 触发
NET_TX_SOFTIRQ 软中断。 - 恢复 IRQ 状态并重新启用中断。
你可以阅读我们之前关于网络栈接收端的文章,来了解更多关于 softnet_data 数据结构初始化的信息。
上面函数中的重要代码是:raise_softirq_irqoff 触发 NET_TX_SOFTIRQ 软中断。softirq 及其注册也在我们的前一篇文章中介绍过。 简单地说,您可以认为软中断是内核线程,它们以非常高的优先级执行,并代表内核处理数据。 它们处理传入的网络数据,也处理传出的数据。
正如你在上一篇文章中看到的,NET_TX_SOFTIRQ 软中断注册了函数 net_tx_action。这意味着有一个内核线程在执行 net_tx_action。 该线程偶尔会暂停,raise_softirq_irqoff 会恢复它。让我们来看看 net_tx_action 是做什么的,这样我们就可以理解内核是如何处理传输请求的。
net_tx_action
net_tx_action 函数位于 ./net/core/dev.c 文件中,它在运行时处理两个主要内容:
- 执行 CPU 的
softnet_data 结构的完成队列。 - 执行 CPU 的
softnet_data 结构的输出队列。
实际上,该函数的代码是两个大的 if 块。 让我们一次查看一个,同时记住这段代码是作为一个独立的内核线程在软中断上下文中执行的。 net_tx_action 的目的是在整个网络对战的传输侧执行不能在热点路径中执行的代码;工作被延迟,稍后由执行 net_tx_action 的线程进行处理。
net_tx_action 完成队列
softnet_data 的完成队列只是一个等待释放的 skb 队列。 函数 dev_kfree_skb_irq 添加 skb 到队列中以便稍后释放。 设备驱动程序通常使用此选项来延迟释放已使用的 skb。 驱动程序希望延迟释放 skb 而不是简单地释放 skb,原因是释放内存可能需要时间,在某些实例(如 hardirq 处理程序)中,代码需要尽可能快地执行并返回。
看一下 net_tx_action 代码,它处理在完成队列上释放 skb:
if (sd->completion_queue) { struct sk_buff *clist; local_irq_disable(); clist = sd->completion_queue; sd->completion_queue = NULL; local_irq_enable(); while (clist) { struct sk_buff *skb = clist; clist = clist->next; WARN_ON(atomic_read(&skb->users)); trace_kfree_skb(skb, net_tx_action); __kfree_skb(skb); }}
如果完成队列有条目,while 循环将遍历 skb 的链表,并对每个 skb 调用 __kfree_skb 以释放它们的内存。 请记住,这段代码是在一个单独的“线程”中运行的,该线程名为 softirq – 它并不代表任何特定的用户程序运行。
net_tx_action 输出队列
输出队列的用途完全不同。 如前所述,调用 __netif_reschedule 添加数据到输出队列,该调用通常从 __netif_schedule 调用的。 到目前为止,在我们在两个实例中看到过调用了 __netif_schedule 函数:
dev_requeue_skb:正如我们所看到的,如果驱动程序报告错误码 NETDEV_TX_BUSY 或 CPU 冲突,则可以调用此函数。__qdisc_run:我们之前也看到过这个函数。 一旦超过配额或需要重新调度进程,它还会调用 __netif_schedule。
在这两种情况下,都将调用 __netif_schedule 函数,该函数添加 qdisc 到 softnet_data 的输出队列中进行处理。 我将输出队列处理代码分成了三个块。 我们先来看看第一个:
if (sd->output_queue) { struct Qdisc *head; local_irq_disable(); head = sd->output_queue; sd->output_queue = NULL; sd->output_queue_tailp = &sd->output_queue; local_irq_enable();
这个块只是确保输出队列上有 qdisc,如果有,它设置 head 为第一个条目,并移动队列的尾指针。
接下来,遍历 qdsics 列表的 while 循环开始:
while (head) { struct Qdisc *q = head; spinlock_t *root_lock; head = head->next_sched; root_lock = qdisc_lock(q); if (spin_trylock(root_lock)) { smp_mb__before_clear_bit(); clear_bit(__QDISC_STATE_SCHED, &q->state); qdisc_run(q); spin_unlock(root_lock);
上面的代码段向前移动头指针,并获得对 qdisc 锁的引用。spin_trylock 检查是否可以获得锁;注意,该调用是专门使用的,因为它不阻塞。 如果锁已经被持有,spin_trylock 将立即返回,而不是等待获得锁。
如果 spin_trylock 成功获得锁,则返回一个非零值。 在这种情况下,qdisc 的状态字段的__QDISC_STATE_SCHED 位翻转,qdisc_run 被调用,从而翻转 __QDISC___STATE_RUNNING位,并开始执行 __qdisc_run。
这很重要。这里发生的情况是,我们之前检查过的代表用户进行系统调用的处理循环,现在再次运行,但在 softirq 上下文中,因为此 qdisc 的 skb 传输无法传输。 这种区别很重要,因为它会影响您如何监控发送大量数据的应用程序的 CPU 使用情况。 让我换个方式说:
- 程序的系统时间包括调用驱动程序以尝试发送数据所花费的时间,无论发送是否完成或驱动程序是否返回错误。
- 如果在驱动程序层发送不成功(例如,因为设备忙于发送其他内容),则添加 qdisc 到输出队列并稍后由 softirq 线程处理。 在这种情况下,将花费 softirq(si)时间来尝试传输您的数据。
因此,发送数据所花费的总时间是与发送相关的系统调用的系统时间和 NET_TX 软中断的软中断时间的组合。
无论如何,上面的代码释放 qdisc 锁来完成。 如果上面获取锁的 spin_trylock 调用失败,则执行以下代码:
} else { if (!test_bit(__QDISC_STATE_DEACTIVATED, &q->state)) { __netif_reschedule(q); } else { smp_mb__before_clear_bit(); clear_bit(__QDISC_STATE_SCHED, &q->state); } } }}
这段代码只在无法获得 qdisc 锁时执行,它处理两种情况。 两者之一:
- 未停用 qdisc,但无法获取执行
qdisc_run 的锁。 所以,调用 __netif_reschedule。 在这里调用 __netif_reschedule 会将 qdisc 放回该函数当前出列的队列中。这允许在以后可能已经放弃锁时再次检查 qdisc。 - qdisc 被标记为停用,确保
__QDISC_STATE_SCHED 状态标志也被清除。
最后,我们来看看我们的朋友 dev_hard_start_xmit
因此,我们已经遍历了整个网络栈,直到 dev_hard_start_xmit。 也许你是经 sendmsg 系统调用直接到达这里的,或者你是经 qdisc 上处理网络数据的 softirq 线程到达这里的。dev_hard_start_xmit 将向下调用设备驱动程序来实际执行传输操作。
dev_hard_start_xmit函数处理两种主要情况:
- 准备发送的网络数据,或
- 具有需要处理的分段卸载的网络数据。
我们将看到这两种情况是如何处理的,从准备发送的网络数据开始。 让我们一起来看看(如下所示:./net/code/dev.c:
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, struct netdev_queue *txq){ const struct net_device_ops *ops = dev->netdev_ops; int rc = NETDEV_TX_OK; unsigned int skb_len; if (likely(!skb->next)) { netdev_features_t features; if (dev->priv_flags & IFF_XMIT_DST_RELEASE) skb_dst_drop(skb); features = netif_skb_features(skb);
这段代码首先 ops 获取设备驱动程序暴露的操作的引用。当需要驱动程序执行一些工作来传输数据时,将使用它。 代码检查 skb->next 以确保此数据不是数据链的一部分,该数据链已分段准备就绪,并继续执行两件事:
- 首先,它检查设备是否设置了
IFF_XMIT_DST_RELEASE 标志。 此内核中的任何“真正的”以太网设备都不使用此标志。 但是,它被环回设备和其他一些软件设备使用。 如果启用此标志,则可以减少目标缓存条目的引用计数,因为驱动程序不需要它。 - 接下来,
netif_skb_features 从设备获取特性标志,并根据数据的目的协议(dev->protocol)对它们进行一些修改。 例如,如果协议是设备可以校验和的协议,则标记 skb 为这样的协议。 VLAN 标记(如果已设置)也会导致其他功能标志翻转。
接下来,将检查 VLAN 标记,如果设备无法卸载 VLAN 标记,则将在软件中__vlan_put_tag 来执行此操作:
if (vlan_tx_tag_present(skb) && !vlan_hw_offload_capable(features, skb->vlan_proto)) { skb = __vlan_put_tag(skb, skb->vlan_proto, vlan_tx_tag_get(skb)); if (unlikely(!skb)) goto out; skb->vlan_tci = 0;}
接下来,将检查数据是否是封装卸载请求,例如,可能是 GRE。 在这种情况下,更新功能标志,以包括可用的任何特定于设备的硬件封装功能:
if (skb->encapsulation) features &= dev->hw_enc_features;
接下来,netif_needs_gso 来确定 skb 本身是否需要分段。 如果 skb 需要分段,但设备不支持,则 netif_needs_gso 将返回 true 指示分段应在软件中进行。 在本例中,调用dev_gso_segment 来执行分段,代码将跳转到 gso 来传输数据包。 稍后我们将看到 GSO 路径。
if (netif_needs_gso(skb, features)) { if (unlikely(dev_gso_segment(skb, features))) goto out_kfree_skb; if (skb->next) goto gso;}
如果数据不需要分割,则处理一些其他情况。 第一:数据是否需要线性化? 也就是说,如果数据分布在多个缓冲区中,设备是否可以支持发送网络数据,或者是否需要首先组合所有数据到单个线性缓冲区中? 绝大多数网卡不需要在传输之前对数据进行线性化,因此在几乎所有情况下,这将被计算为 false 并跳过。
else { if (skb_needs_linearize(skb, features) && __skb_linearize(skb)) goto out_kfree_skb;
接下来提供了一个有用的注释,解释了下一个分支。 检查数据包以确定它是否仍需要校验和。 如果设备不支持校验和,则在软件中生成校验和:
if (skb->ip_summed == CHECKSUM_PARTIAL) { if (skb->encapsulation) skb_set_inner_transport_header(skb, skb_checksum_start_offset(skb)); else skb_set_transport_header(skb, skb_checksum_start_offset(skb)); if (!(features & NETIF_F_ALL_CSUM) && skb_checksum_help(skb)) goto out_kfree_skb; }}
现在我们继续讨论数据包抓取!回想一下,在 接收端博客文章 中,我们看到了如何传递数据包给数据包抓取(例如 PCAP)。此函数中的下一块代码将即将传输的数据包交给数据包抓取(如果有的话)。
if (!list_empty(&ptype_all)) dev_queue_xmit_nit(skb, dev);
最后,驱动程序的 ops 调用 ndo_start_xmit 向下传递数据到设备:
skb_len = skb->len; rc = ops->ndo_start_xmit(skb, dev); trace_net_dev_xmit(skb, rc, dev, skb_len); if (rc == NETDEV_TX_OK) txq_trans_update(txq); return rc;}
返回 ndo_start_xmit 的返回值,指示数据包是否被传输。 我们看到了这个返回值将如何影响上层:由该函数调用方的 QDisc 重新排队数据,以便它可以稍后再次传输。
让我们来看看 GSO 的案例。 如果 skb 已经由于在此函数中发生的分段,而被分离成一个数据包链,或者先前分段但未能发送并排队等待再次发送的数据包,则此代码将运行。
gso: do { struct sk_buff *nskb = skb->next; skb->next = nskb->next; nskb->next = NULL; if (!list_empty(&ptype_all)) dev_queue_xmit_nit(nskb, dev); skb_len = nskb->len; rc = ops->ndo_start_xmit(nskb, dev); trace_net_dev_xmit(nskb, rc, dev, skb_len); if (unlikely(rc != NETDEV_TX_OK)) { if (rc & ~NETDEV_TX_MASK) goto out_kfree_gso_skb; nskb->next = skb->next; skb->next = nskb; return rc; } txq_trans_update(txq); if (unlikely(netif_xmit_stopped(txq) && skb->next)) return NETDEV_TX_BUSY; } while (skb->next);
您可能已经猜到了,这段代码是一个 while 循环,它遍历在数据分段时生成的 skb 列表。
每个数据包:
- 通过数据包抓取(如果有)。
- 通过
ndo_start_xmit 传递给驱动器进行传输。
传输数据包中的任何错误都会调整需要发送的 skb 列表来处理。 错误将返回堆栈,未发送的 skb 可能会被重新排队,以便稍后再次发送。
此函数的最后一部分处理清理,并可能在出现上述错误时释放数据:
out_kfree_gso_skb: if (likely(skb->next == NULL)) { skb->destructor = DEV_GSO_CB(skb)->destructor; consume_skb(skb); return rc; }out_kfree_skb: kfree_skb(skb);out: return rc;}EXPORT_SYMBOL_GPL(dev_hard_start_xmit);
在继续讨论设备驱动程序之前,让我们看一下可以对我们刚刚浏览的代码进行的一些监控和调优。
监控 qdiscs
使用 tc 命令行工具
使用 tc 监控您的 qdisc 统计数据
$ tc -s qdisc show dev eth1qdisc mq 0: root Sent 31973946891907 bytes 2298757402 pkt (dropped 0, overlimits 0 requeues 1776429) backlog 0b 0p requeues 1776429
为了监控系统的数据包传输状况,检查连接到网络设备的队列规则的统计信息至关重要。 您可以运行命令行工具 tc 来检查状态。 上面的示例显示了如何检查 eth1 接口的统计信息。
bytes:下推到驱动程序进行传输的字节数。pkt:下推到驱动程序进行传输的数据包数量。dropped:qdisc 丢弃的数据包数。 如果传输队列长度不足以容纳排队的数据,则可能发生这种情况。overlimits:取决于排队规则,但可以是由于达到限制而无法入队的数据包数量,和/或在出队时触发节流事件的数据包数量。requeues:调用 dev_requeue_skb 重新排队 skb 的次数。 请注意,多次重新排队的 skb 将在每次重新排队时增加此计数器。backlog:当前在 qdisc 队列中的字节数。 这个数字通常在每次数据包入队时增加。
某些 qdics 可能会导出其他统计信息。 每个 qdisc 是不同的,并且可以在不同的时间增加这些计数器。 您可能需要研究您正在使用的 qdisc 的源代码,以准确了解这些值何时可以在您的系统上增加,从而帮助了解对您的影响。
调优 qdiscs
增加 __qdisc_run
您可以调整前面看到 __qdisc_run 循环的权重(上面看到的quota变量),这将导致执行更多__netif_schedule 的调用。 结果是当前 qdisc 更多次被添加到当前 CPU 的 output_queue 列表中,这应该会导致对传输数据包的额外处理。
示例:使用 sysctl 增加所有 qdisc 的 __qdisc_run 配额。
$ sudo sysctl -w net.core.dev_weight=600
增加传输队列长度
每个网络设备都有一个可以修改的 txqueuelen 调节旋钮。大多数 qdisc 在对最终应由 qdisc 传输的数据排队时,都会检查设备是否具有足够的 txqueuelen 字节。您可以调整此参数以增加 qdisc 可排队的字节数。
示例:增加 eth0 的 txqueuelen 到 10000。
$ sudo ifconfig eth0 txqueuelen 10000
以太网设备的默认值为 1000。 您可以读取 ifconfig 的输出来检查网络设备的 txqueuelen。
网络设备驱动程序
我们的旅程就要结束了。 关于数据包传输有一个重要的概念需要理解。 大多数设备和驱动程序将数据包传输处理分为两步过程:
- 数据被正确地排列,并且触发设备从 RAM DMA 写入数据到网络
- 传输完成后,设备引发中断,以便驱动程序可以取消缓冲区映射、释放内存或以其他方式清除其状态。
第二阶段通常被称为“传输完成”阶段。 我们将研究这两个阶段,但我们将从第一阶段开始:传输阶段。
我们看到 dev_hard_start_xmit 调用了 ndo_start_xmit(持有锁)来传输数据,所以让我们从检查驱动程序如何注册 ndo_start_xmit 开始,然后我们将深入研究该函数如何工作。
和 上一篇博文一样, 我们将研究 igb 驱动程序。
驱动操作注册
驱动程序为各种操作实现一系列功能,例如:
- 发送数据(
ndo_start_xmit) - 获取统计信息(
ndo_get_stats64) - 处理设备
ioctls(ndo_do_ioctl) - 还有更多。
函数被导出为一系列排列在结构中的函数指针。 让我们来看看 igb 驱动程序源代码中这些操作的结构定义:
static const struct net_device_ops igb_netdev_ops = { .ndo_open = igb_open, .ndo_stop = igb_close, .ndo_start_xmit = igb_xmit_frame, .ndo_get_stats64 = igb_get_stats64,};
此结构在 igb_probe 函数中注册:
static int igb_probe(struct pci_dev *pdev, const struct pci_device_id *ent){ netdev->netdev_ops = &igb_netdev_ops;}
正如我们在上一节中看到的,更高层的代码将获得对设备的 netdev_ops 结构的引用,并调用相应的函数。 如果你想了解更多关于 PCI 设备是如何启动的,以及何时/何地调用 igb_probe 的信息,请查看我们的其他博客文章中的驱动程序初始化部分。
使用 ndo_start_xmit 传输数据
网络栈的较高层使用 net_device_ops 结构调用驱动程序来执行各种操作。 正如我们前面看到的,qdisc 代码调用 ndo_start_xmit 传递数据给驱动程序进行传输。 对于大多数硬件设备,ndo_start_xmit 函数在锁被持有时被调用,正如我们上面看到的。
在 igb 设备驱动程序中,注册到 ndo_start_xmit 称为 igb_xmit_frame,因此让我们从igb_xmit_frame 开始,了解此驱动程序如何传输数据。 进入 ./drivers/net/ethernet/intel/igb/igb_main.c ,并记住,在执行以下代码的整个过程中,都会持有一个锁:
netdev_tx_t igb_xmit_frame_ring(struct sk_buff *skb, struct igb_ring *tx_ring){ struct igb_tx_buffer *first; int tso; u32 tx_flags = 0; u16 count = TXD_USE_COUNT(skb_headlen(skb)); __be16 protocol = vlan_get_protocol(skb); u8 hdr_len = 0; if (NETDEV_FRAG_PAGE_MAX_SIZE > IGB_MAX_DATA_PER_TXD) { unsigned short f; for (f = 0; f < skb_shinfo(skb)->nr_frags; f++) count += TXD_USE_COUNT(skb_shinfo(skb)->frags[f].size); } else { count += skb_shinfo(skb)->nr_frags; }
该函数开始使用 TXD_USER_COUNT 宏来确定需要多少个传输描述符来传输传入的数据。 count 值初始化为适合 skb 的描述符数量。 然后考虑需要传输的任何附加片段,对其进行调整。
if (igb_maybe_stop_tx(tx_ring, count + 3)) { return NETDEV_TX_BUSY;}
然后驱动程序调用一个内部函数 igb_maybe_stop_tx,该函数检查所需的描述符数量,以确保传输队列有足够的可用资源。 如果没有,则在此处返回 NETDEV_TX_BUSY。 正如我们前面在 qdisc 代码中看到的,这将导致 qdisc 重新排队数据以便稍后重试。
first = &tx_ring->tx_buffer_info[tx_ring->next_to_use];first->skb = skb;first->bytecount = skb->len;first->gso_segs = 1;
然后,代码获得对传输队列中的下一个可用缓冲区信息的引用。 此结构将跟踪稍后设置缓冲区描述符所需的信息。 对数据包的引用及其大小被复制到缓冲区信息结构中。
skb_tx_timestamp(skb);
上面的代码调用 skb_tx_timestamp 获得基于软件的发送时间戳。 应用程序可以使用发送时间戳来确定数据包通过网络栈的传输路径所花费的时间量。
一些设备还支持为在硬件中传输的数据包生成时间戳。 这允许系统卸载时间戳到设备,并且它允许程序员获得更准确的时间戳,因为它将更接近硬件的实际传输发生的时间。 现在我们来看看这段代码:
if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_HW_TSTAMP)) { struct igb_adapter *adapter = netdev_priv(tx_ring->netdev); if (!(adapter->ptp_tx_skb)) { skb_shinfo(skb)->tx_flags |= SKBTX_IN_PROGRESS; tx_flags |= IGB_TX_FLAGS_TSTAMP; adapter->ptp_tx_skb = skb_get(skb); adapter->ptp_tx_start = jiffies; if (adapter->hw.mac.type == e1000_82576) schedule_work(&adapter->ptp_tx_work); }}
一些网络设备可以使用精确时间协议在硬件中对数据包加时间戳。 当用户请求硬件时间戳时,驱动程序代码将在此处处理此问题。
上面的 if 语句检查 SKBTX_HW_TSTAMP 标志。 此标志指示用户请求了硬件时间戳。 如果用户请求了硬件时间戳,代码接下来检查是否设置 ptp_tx_skb。 一次可以对一个数据包加时间戳,,因此在此处获取正在进行时间戳的数据包的引用,并在 skb 上设置 SKBTX_IN_PROGRESS 标志。 更新 tx_flags 以标记 IGB_TX_FLAGS_TSTAMP 标志。 变量稍后复制 tx_flags 到 buffer info 结构中。
获取 skb 的引用,复制当前 jiffies 计数到 ptp_tx_start。驱动程序中的其他代码将使用此值来确保 TX 硬件时间戳不会挂起。最后,如果这是一个 82576 以太网硬件适配器,则使用 schedule_work 函数来启动 工作队列。
if (vlan_tx_tag_present(skb)) { tx_flags |= IGB_TX_FLAGS_VLAN; tx_flags |= (vlan_tx_tag_get(skb) << IGB_TX_FLAGS_VLAN_SHIFT);}
上面的代码检查是否设置了 skb 的 vlan_tci 字段。 如果已设置,则启用IGB_TX_FLAGS_VLAN 标志并存储 vlan ID。
first->tx_flags = tx_flags;first->protocol = protocol;
标志和协议被记录到缓冲区信息结构。
tso = igb_tso(tx_ring, first, &hdr_len);if (tso < 0) goto out_drop;else if (!tso) igb_tx_csum(tx_ring, first);
接下来,驱动程序调用其内部函数 igb_tso。 此函数确定 skb 是否需要分段。 如果是,则缓冲器信息引用(first)更新其标志以向硬件指示需要 TSO。
如果 tso 不必要,igb_tso 将返回 0,否则返回 1。 如果返回 0,igb_tx_csum 来处理启用校验和卸载(如果需要并且该协议支持)。 igb_tx_csum 函数检查 skb 的属性,并首先翻转 缓冲区 first 中的一些标志位,以指示需要卸载校验和。
igb_tx_map(tx_ring, first, hdr_len);
调用 igb_tx_map 函数来准备设备要消耗的数据以进行传输。 接下来我们将详细研究这个函数。
igb_maybe_stop_tx(tx_ring, DESC_NEEDED);return NETDEV_TX_OK;
传输完成后,驱动程序进行检查,以确保有足够的空间可用于另一次传输。 如果没有,则关闭队列。 在任何一种情况下,NETDEV_TX_OK 都会返回到更高层(qdisc 代码)。
out_drop: igb_unmap_and_free_tx_resource(tx_ring, first); return NETDEV_TX_OK;}
最后是一些错误处理代码。 这段代码只在 igb_tso 遇到某种错误时才被命中。 igb_unmap_and_free_tx_resource 清理数据。在这种情况下也返回 NETDEV_TX_OK。 传输不成功,但驱动程序释放了关联的资源,没有什么可做的了。 请注意,在这种情况下,此驱动程序不会增加数据包丢弃,但它可能应该这样做。
igb_tx_map
igb_tx_map函数处理映射 skb 数据到 RAM 的可 DMA 区域的细节。 它还更新设备上的传输队列的尾指针,这是触发设备“唤醒”、从 RAM 获取数据,并开始传输数据。
让我们简单地看看这个函数是如何工作的:
static void igb_tx_map(struct igb_ring *tx_ring, struct igb_tx_buffer *first, const u8 hdr_len){ struct sk_buff *skb = first->skb; u32 tx_flags = first->tx_flags; u32 cmd_type = igb_tx_cmd_type(skb, tx_flags); u16 i = tx_ring->next_to_use; tx_desc = IGB_TX_DESC(tx_ring, i); igb_tx_olinfo_status(tx_ring, tx_desc, tx_flags, skb->len - hdr_len); size = skb_headlen(skb); data_len = skb->data_len; dma = dma_map_single(tx_ring->dev, skb->data, size, DMA_TO_DEVICE);
上面的代码做了几件事:
- 声明一组变量并初始化它们。
- 使用
IGB_TX_DESC宏确定获取下一个可用描述符的引用。 igb_tx_olinfo_status 更新 tx_flags 并复制其到描述符(tx_desc)中。- 捕获大小和数据长度,以便稍后使用。
dma_map_single 构造获得 skb->data 数据的 DMA 可访问地址所需的任何内存映射。 这样做使得设备可以从存储器读取数据包数据。
接下来是驱动程序中的一个非常密集的循环,为 skb 的每个片段生成有效的映射。 具体如何发生这种情况的细节并不特别重要,但值得一提:
- 驱动程序遍历数据包片段的集合。
- 当前描述符中填入数据的 DMA 地址。
- 如果片段的大小大于单个IGB描述符可以传输的大小,则构造多个描述符以指向可DMA区域的块,直到描述符指向整个片段。
- 增加描述符迭代器。
- 减少剩余长度。
- 当出现以下情况时,循环终止:没有剩余片段或者整个数据长度已经被消耗。
以下提供循环的代码,以供参考以上描述。 这应该进一步向读者说明,如果可能的话,避免碎片化是一个好主意。 需要在堆栈的每一层运行大量额外的代码来处理它,包括驱动程序。
tx_buffer = first;for (frag = &skb_shinfo(skb)->frags[0];; frag++) { if (dma_mapping_error(tx_ring->dev, dma)) goto dma_error; dma_unmap_len_set(tx_buffer, len, size); dma_unmap_addr_set(tx_buffer, dma, dma); tx_desc->read.buffer_addr = cpu_to_le64(dma); while (unlikely(size > IGB_MAX_DATA_PER_TXD)) { tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type ^ IGB_MAX_DATA_PER_TXD); i++; tx_desc++; if (i == tx_ring->count) { tx_desc = IGB_TX_DESC(tx_ring, 0); i = 0; } tx_desc->read.olinfo_status = 0; dma += IGB_MAX_DATA_PER_TXD; size -= IGB_MAX_DATA_PER_TXD; tx_desc->read.buffer_addr = cpu_to_le64(dma); } if (likely(!data_len)) break; tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type ^ size); i++; tx_desc++; if (i == tx_ring->count) { tx_desc = IGB_TX_DESC(tx_ring, 0); i = 0; } tx_desc->read.olinfo_status = 0; size = skb_frag_size(frag); data_len -= size; dma = skb_frag_dma_map(tx_ring->dev, frag, 0, size, DMA_TO_DEVICE); tx_buffer = &tx_ring->tx_buffer_info[i];}
一旦所有必要的描述符都已构建,并且所有 skb 的数据都已映射到 DMA 地址,驱动程序将继续执行其最后步骤以触发传输:
cmd_type |= size | IGB_TXD_DCMD;tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type);
写入终止描述符以向设备指示它是最后一个描述符。
netdev_tx_sent_queue(txring_txq(tx_ring), first->bytecount);first->time_stamp = jiffies;
调用 netdev_tx_sent_queue 函数时,会添加字节数到此传输队列。 这个函数是字节查询限制特性的一部分,我们稍后会详细介绍。 当前 jiffies 被存储在第一缓冲器信息结构中。
接下来,有一点棘手:
wmb();first->next_to_watch = tx_desc;i++;if (i == tx_ring->count) i = 0;tx_ring->next_to_use = i;writel(i, tx_ring->tail);mmiowb();return;
上面的代码正在执行一些重要的操作:
- 首先调用
wmb 函数强制完成内存写入。这将作为适用于 CPU 平台的特殊指令执行,通常称为“写屏障”。这在某些 CPU 架构上很重要,因为如果我们在没有确保所有更新内部状态的内存写入都已完成之前触发设备启动 DMA,则设备可能会从 RAM 中读取不一致状态的数据。这篇文章 和这个 讲座 深入探讨了有关内存排序的细节。 - 设置
next_to_watch 字段。它将在完成阶段后使用。 - 增加计数器,并更新传输队列的
next_to_use 字段为下一个可用描述符。 - 使用
writel 函数更新传输队列的尾部。writel 将一个 “long” 写入 内存映射 I/O 地址。在这种情况下,地址是 tx_ring->tail(这是一个硬件地址),要写入的值是 i。此写入会触发设备,让它知道有更多数据准备好从 RAM 进行 DMA 并写入网络。 - 最后,调用
mmiowb 函数。此函数将执行适用于 CPU 架构的指令,使内存映射写入操作有序。它也是一个写屏障,但用于内存映射 I/O 写入。
如果您想了解更多关于 wmb、mmiowb 以及何时使用它们,可以阅读 Linux 内核中包含的一些出色的 关于内存屏障的文档。
最后,只有当从 DMA API 返回错误时(当尝试映射 skb 数据地址到可 DMA 地址时),才会执行此代码。
dma_error: dev_err(tx_ring->dev, "TX DMA map failed\n"); for (;;) { tx_buffer = &tx_ring->tx_buffer_info[i]; igb_unmap_and_free_tx_resource(tx_ring, tx_buffer); if (tx_buffer == first) break; if (i == 0) i = tx_ring->count; i--; } tx_ring->next_to_use = i;
在继续传输完成之前,让我们检查一下上面传递的内容:动态队列限制。
动态队列限制(DQL)
正如你在这篇文章中看到的那样,随着网络数据越来越靠近传输设备,它会在不同阶段花费大量时间排队。随着队列大小的增加,数据包在未传输的队列中停留的时间更长,即数据包传输延迟随着队列大小增加而增加。
对抗这种情况的一种方法是背压。动态队列限制(DQL)系统是一种机制,设备驱动程序可以使用该机制向网络系统施加背压,
要使用此系统,网络设备驱动程序需要在其传输和完成例程期间进行一些简单的 API 调用。 DQL 系统内部使用一种算法来确定何时有足够的数据传输。 一旦达到此限制,传输队列将暂时禁用。 这种队列禁用是对网络系统产生背压的原因。当DQL系统确定有足够的数据完成传输时,队列将自动重新启用。
查看这组关于 DQL 系统的优秀幻灯片,了解一些性能数据和 DQL 内部算法的解释。
我们刚才看到的代码中调用的函数 netdev_tx_sent_queue 是 DQL API 的一部分。 当数据排队到设备进行传输时,会调用此函数。 传输完成后,驱动程序调用 就会调用 netdev_tx_completed_queue。 在内部,这两个函数都将调用 DQL 库(位于 ./lib/dynamic_queue_limits.c 和 ./include/linux/dynamic_queue_limits.h 中),以确定传输队列是否应该被禁用、重新启用或保持原样。
DQL 在 sysfs 中导出统计信息和调优旋钮。 调优 DQL 应该是不必要的;该算法将随时间调整其参数。 不过,为了完整起见,我们将在后面看到如何监控和调优 DQL。
传输完成
一旦设备传输了数据,它将产生一个中断信号,表示传输完成。 然后设备驱动程序可以安排一些长时间运行的工作来完成,比如取消映射内存区域和释放数据。 具体如何工作取决于设备。 在 igb 驱动程序(及其相关设备)的情况下,发射相同的 IRQ 以完成传输和接收数据包。 这意味着对于 igb 驱动程序,NET_RX 处理发送完成和传入数据包接收。
让我重申这一点,以强调其重要性:您的设备可能会在接收数据包时发出与发送数据包完成信号相同的中断。如果是,NET_RX 软中断将运行处理传入数据包和传输完成。
由于两个操作共享同一个 IRQ,因此只能注册一个 IRQ 处理函数,并且它必须处理两种可能的情况。 当接收到网络数据时,调用以下流程:
- 接收网络数据。
- 网络设备引发 IRQ。
- 设备驱动程序的 IRQ 处理程序执行,清除 IRQ 并确保 softIRQ 被调度运行(如果尚未运行)。 这里触发的软中断是
NET_RX 软中断。 - 软中断本质上是作为一个单独的内核线程执行的。 它运行并实现 NAPI 轮询循环。
- NAPI 轮询循环只是一段代码,只要有足够的预算,它就在循环中执行,收集数据包。
- 每次处理数据包时,预算都会减少,直到没有更多的数据包要处理,预算达到 0,或者时间片到期为止。
igb 驱动程序(和 ixgbe 驱动程序[greetings,tyler])中的上述步骤 5 在处理传入数据之前处理传输完成。 请记住,根据驱动程序的实现,传输完成和传入数据的处理功能可能共享相同的处理预算。 igb 和 ixgbe 驱动器分别跟踪传输完成和传入数据包预算,因此处理传输完成将不一定耗尽传入预算。
也就是说,整个 NAPI 轮询循环在硬编码的时间片内运行。 这意味着,如果要处理大量的传输完成处理,传输完成可能会比处理传入数据占用更多的时间片。 对于那些在非常高的负载环境中运行网络硬件的人来说,这可能是一个重要的考虑因素。
让我们看看 igb 驱动程序在实践中是如何做到这一点的。
传输完成 IRQ
这篇文章将不再重复Linux 内核接收端网络博客文章中已经涵盖的信息,而是按顺序列出步骤,并链接到接收端博客文章中的相应部分,直到传输完成。
所以,让我们从头开始:
- 网络设备启动。
- IRQ 处理程序已注册。
- 用户程序发送数据到网络套接字。 数据在网络栈中传输,直到设备从内存中获取数据并将其传输。
- 设备完成数据传输并引发 IRQ 以通知传输完成。
- 驱动程序的IRQ 处理程序执行以处理中断。
- IRQ 处理程序调用
napi_schedule 来响应 IRQ。 - NAPI 代码 触发
NET_RX 软中断执行。 NET_RX 软中断函数 net_rx_action 开始执行。net_rx_action 函数调用驱动程序注册的 NAPI 轮询函数。- 执行 NAPI 轮询函数
igb_poll。
轮询函数 igb_poll 是代码分离并处理传入数据包和传输完成的地方。 让我们深入研究这个函数的代码,看看它在哪里发生的。
igb_poll
让我们来看看 igb_poll(来自 ./drivers/net/ethernet/intel/igb/igb_main.c):
static int igb_poll(struct napi_struct *napi, int budget){ struct igb_q_vector *q_vector = container_of(napi, struct igb_q_vector, napi); bool clean_complete = true;#ifdef CONFIG_IGB_DCA if (q_vector->adapter->flags & IGB_FLAG_DCA_ENABLED) igb_update_dca(q_vector);#endif if (q_vector->tx.ring) clean_complete = igb_clean_tx_irq(q_vector); if (q_vector->rx.ring) clean_complete &= igb_clean_rx_irq(q_vector, budget); if (!clean_complete) return budget; napi_complete(napi); igb_ring_irq_enable(q_vector); return 0;}
此函数执行几个操作,顺序如下:
- 如果在内核中启用了直接缓存访问(DCA)支持,则 CPU 缓存将预热,以便对 RX 环的访问将命中 CPU 缓存。 您可以在接收端网络帖子的附加部分阅读有关 DCA 的更多信息。
- 调用
igb_clean_tx_irq,执行发送完成操作。 - 接下来调用
igb_clean_rx_irq,其执行传入数据包处理。 - 最后,检查
clean_complete 以确定是否还有更多的工作可以完成。 如果是,则返回budget。 如果发生这种情况,net_rx_action 移动这个 NAPI 结构到轮询列表的末尾,以便稍后再次处理。
要了解更多关于 igb_clean_rx_irq 工作原理,请阅读上一篇博客文章的这一部分。
这篇博客文章主要关注发送端,所以我们将继续研究上面的 igb_clean_tx_irq 是如何工作的。
igb_clean_tx_irq
请查看 ./drivers/net/ethernet/intel/igb/igb_main.c 中此函数的源代码。
它有点长,所以我们把它分成块并研究它:
static bool igb_clean_tx_irq(struct igb_q_vector *q_vector){ struct igb_adapter *adapter = q_vector->adapter; struct igb_ring *tx_ring = q_vector->tx.ring; struct igb_tx_buffer *tx_buffer; union e1000_adv_tx_desc *tx_desc; unsigned int total_bytes = 0, total_packets = 0; unsigned int budget = q_vector->tx.work_limit; unsigned int i = tx_ring->next_to_clean; if (test_bit(__IGB_DOWN, &adapter->state)) return true;
该函数首先初始化一些有用的变量。 一个重要的考虑因素是 budget。 正如你在上面看到的budget 被初始化为这个队列的 tx.work_limit。 在 igb 驱动程序中,tx.work_limit 被初始化为硬编码值 IGB_DEFAULT_TX_WORK(128)。
值得注意的是,虽然我们现在看到的传输完成代码与接收处理在相同的 NET_RX 软中断中运行,但 TX 和 RX 函数在 igb 驱动程序中并不共享处理预算 。由于整个 poll 函数在相同的时间片内运行,因此单次运行 igb_poll 函数不可能使传入的数据包处理或传输完成饿死。只要调用igb_poll,两者都会被处理。
接下来,上面的代码片段以检查网络设备是否关闭结束。如果是,则返回 true 并退出igb_clean_tx_irq。
tx_buffer = &tx_ring->tx_buffer_info[i];tx_desc = IGB_TX_DESC(tx_ring, i);i -= tx_ring->count;
tx_buffer 变量被初始化为位于 tx_ring->next_to_clean(其本身被初始化为0)的传输缓冲区信息结构。- 获得相关联的描述符的引用,并将其存储在
tx_desc。 - 计数器
i 减少发送队列的大小。 这个值可以调整(正如我们将在调优部分看到的那样),但是被初始化为 IGB_DEFAULT_TXD(256)。
接下来,循环开始。 它包括一些有用的注释,以解释每个步骤中发生的事情:
do { union e1000_adv_tx_desc *eop_desc = tx_buffer->next_to_watch; if (!eop_desc) break; read_barrier_depends(); if (!(eop_desc->wb.status & cpu_to_le32(E1000_TXD_STAT_DD))) break; tx_buffer->next_to_watch = NULL; total_bytes += tx_buffer->bytecount; total_packets += tx_buffer->gso_segs; dev_kfree_skb_any(tx_buffer->skb); dma_unmap_single(tx_ring->dev, dma_unmap_addr(tx_buffer, dma), dma_unmap_len(tx_buffer, len), DMA_TO_DEVICE); tx_buffer->skb = NULL; dma_unmap_len_set(tx_buffer, len, 0);
- 首先,
eop_desc 被设置为缓冲区的 next_to_watch 字段。这是在我们之前看到的传输代码中设置的。 - 如果
eop_desc(eop = 数据包结束)为 NULL,则没有工作待处理。 - 调用
read_barrier_depends 函数,该函数将为此 CPU 架构执行适当的 CPU 指令,以防止读取被重新排序到此屏障之前。 - 接下来,在数据包结束描述符
eop_desc 中检查一个状态位。如果未设置 E1000_TXD_STAT_DD 位,则传输尚未完成,因此从循环中退出。 - 清除
tx_buffer->next_to_watch。驱动程序中的看门狗定时器将监视此字段以确定传输是否挂起。清除此字段将防止看门狗触发。 - 更新发送的总字节数和数据包数的统计计数器。一旦处理完所有描述符,复制这些到驱动程序读取的统计计数器中。
- 释放 skb。
- 使用
dma_unmap_single 取消映射 skb 数据区域。 - 设置
tx_buffer->skb 为 NULL 并取消映射 tx_buffer。
接下来,在上面的循环内部开始另一个循环:
while (tx_desc != eop_desc) { tx_buffer++; tx_desc++; i++; if (unlikely(!i)) { i -= tx_ring->count; tx_buffer = tx_ring->tx_buffer_info; tx_desc = IGB_TX_DESC(tx_ring, 0); } if (dma_unmap_len(tx_buffer, len)) { dma_unmap_page(tx_ring->dev, dma_unmap_addr(tx_buffer, dma), dma_unmap_len(tx_buffer, len), DMA_TO_DEVICE); dma_unmap_len_set(tx_buffer, len, 0); }}
该内部循环将在每个传输描述符上循环,直到 tx_desc 到达 eop_desc。 这段代码取消映射任何附加描述符引用的数据。
外部循环继续:
tx_buffer++; tx_desc++; i++; if (unlikely(!i)) { i -= tx_ring->count; tx_buffer = tx_ring->tx_buffer_info; tx_desc = IGB_TX_DESC(tx_ring, 0); } prefetch(tx_desc); budget--;} while (likely(budget));
外部循环增加迭代器并减少 budget 值。 检查循环不变量以确定循环是否应继续。
netdev_tx_completed_queue(txring_txq(tx_ring), total_packets, total_bytes);i += tx_ring->count;tx_ring->next_to_clean = i;u64_stats_update_begin(&tx_ring->tx_syncp);tx_ring->tx_stats.bytes += total_bytes;tx_ring->tx_stats.packets += total_packets;u64_stats_update_end(&tx_ring->tx_syncp);q_vector->tx.total_bytes += total_bytes;q_vector->tx.total_packets += total_packets;
此代码:
- 调用
netdev_tx_completed_queue,它是上面解释的 DQL API 的一部分。 如果处理了足够的传输完成,这将潜在地重新启用传输队列。 - 统计数据被添加到适当位置,以便用户可以访问它们,我们将在后面看到。
代码继续执行,首先检查是否设置了 IGBIGB_RING_FLAG_TX_DETECT_HANG 标志。 看门狗定时器在每次运行定时器回调时设置此标志,以强制执行传输队列的定期检查。 如果该标志现在恰好打开,代码将继续并检查传输队列是否挂起:
if (test_bit(IGB_RING_FLAG_TX_DETECT_HANG, &tx_ring->flags)) { struct e1000_hw *hw = &adapter->hw; clear_bit(IGB_RING_FLAG_TX_DETECT_HANG, &tx_ring->flags); if (tx_buffer->next_to_watch && time_after(jiffies, tx_buffer->time_stamp + (adapter->tx_timeout_factor * HZ)) && !(rd32(E1000_STATUS) & E1000_STATUS_TXOFF)) { dev_err(tx_ring->dev, "Detected Tx Unit Hang\n" " Tx Queue <%d>\n" " TDH <%x>\n" " TDT <%x>\n" " next_to_use <%x>\n" " next_to_clean <%x>\n" "buffer_info[next_to_clean]\n" " time_stamp <%lx>\n" " next_to_watch <%p>\n" " jiffies <%lx>\n" " desc.status <%x>\n", tx_ring->queue_index, rd32(E1000_TDH(tx_ring->reg_idx)), readl(tx_ring->tail), tx_ring->next_to_use, tx_ring->next_to_clean, tx_buffer->time_stamp, tx_buffer->next_to_watch, jiffies, tx_buffer->next_to_watch->wb.status); netif_stop_subqueue(tx_ring->netdev, tx_ring->queue_index); return true; }
上面的 if 语句检查:
- 设置了
tx_buffer->next_to_watch,并且 - 当前
jiffies 大于在传输路径上记录到 tx_buffer 的 time_stamp,其中添加了超时因子,以及 - 设备的传输状态寄存器未设置为
E1000_STATUS_TXOFF。
如果这三个测试都为真,则打印一个错误,表明检测到挂起。使用 netif_stop_subqueue 关闭队列,并返回 true。
让我们继续阅读代码,看看如果没有传输挂起检查,或者如果有,但没有检测到挂起,会发生什么:
#define TX_WAKE_THRESHOLD (DESC_NEEDED * 2) if (unlikely(total_packets && netif_carrier_ok(tx_ring->netdev) && igb_desc_unused(tx_ring) >= TX_WAKE_THRESHOLD)) { smp_mb(); if (__netif_subqueue_stopped(tx_ring->netdev, tx_ring->queue_index) && !(test_bit(__IGB_DOWN, &adapter->state))) { netif_wake_subqueue(tx_ring->netdev, tx_ring->queue_index); u64_stats_update_begin(&tx_ring->tx_syncp); tx_ring->tx_stats.restart_queue++; u64_stats_update_end(&tx_ring->tx_syncp); } } return !!budget;
在上面的代码中,驱动程序重新启动传输队列(如果先前已禁用)。它首先检查是否:
- 某些数据包已经处理完成(
total_packets 非零),并且 netif_carrier_ok 以确保设备未被关闭,以及- 传输队列中未使用的描述符数量大于或等于
TX_WAKE_THRESHOLD。在我的 x86_64 系统上,此阈值似乎为 42。
如果所有条件都满足,则使用写屏障(smp_mb)。接下来检查另一组条件:
然后调用 netif_wake_subqueue 唤醒传输队列并向更高层次发出信号,表示它们可以再次排队数据。增加 restart_queue 统计计数器。接下来我们将看到如何读取此值。
最后,返回一个布尔值。如果有任何剩余的未使用预算,则返回 true,否则返回 false。在 igb_poll 中检查此值以确定返回给 net_rx_action 的内容。
igb_poll 返回值
igbigb_poll 函数有以下代码来确定返回给 net_rx_action:
if (q_vector->tx.ring) clean_complete = igb_clean_tx_irq(q_vector);if (q_vector->rx.ring) clean_complete &= igb_clean_rx_irq(q_vector, budget);if (!clean_complete) return budget;
换句话说,如果:
igb_clean_tx_irq 清除了所有传输完成,而没有耗尽其传输完成预算,以及igb_clean_rx_irq 清除了所有传入数据包,而没有耗尽其数据包处理预算
然后,将返回整个预算数量(对于大多数驱动程序,它被硬编码为 64,包括 igb)。 如果传输或传入处理中的任何一个不能完成(因为还有更多的工作要做),则调用 napi_complete 并返回 0:
napi_complete(napi); igb_ring_irq_enable(q_vector); return 0;}
监控网络设备
有几种不同的方法可以监控网络设备,提供不同级别的粒度和复杂性。 让我们从最细粒度开始,然后转到最细粒度。
你可以运行以下命令在 Ubuntu 系统上安装 ethtool:sudo apt-get install ethtool.
安装后,您可以传递 -S 标志以及需要统计信息的网络设备的名称来访问统计信息。
使用 ethtool -S 监控详细的 NIC 设备统计信息(例如, 传输错误)。
$ sudo ethtool -S eth0NIC statistics: rx_packets: 597028087 tx_packets: 5924278060 rx_bytes: 112643393747 tx_bytes: 990080156714 rx_broadcast: 96 tx_broadcast: 116 rx_multicast: 20294528 ....
监测这些数据可能很困难。 它很容易获得,但字段值没有标准化。 不同的驱动程序,甚至不同版本的同一 驱动可能会产生具有相同含义的不同字段名称。
你应该在标签中寻找带有“drop”、“buffer”、“miss”、“errors”等的值。接下来,您将不得不阅读驱动程序源代码。您将能够确定哪些值完全在软件中计算(例如,在没有内存时增加)以及哪些值直接通过寄存器从硬件读取获得。对于寄存器值,您应该查阅硬件的数据表以确定计数器的真实含义; ethtool 给出的许多标签可能会产生误导。
使用 sysfs
sysfs 也提供了许多统计值,但它们比直接提供的 NIC 级别统计值略高一些。
您可以使用 cat 在文件上查找丢弃的传入网络数据帧的数量,例如 eth0。
使用 sysfs 监控更高级别的 NIC 统计信息。
$ cat /sys/class/net/eth0/statistics/tx_aborted_errors2
计数器值将被拆分为 tx_aborted_errors、tx_carrier_errors、tx_compressed、tx_dropped 等文件。
不幸的是,由驱动程序来决定每个字段的含义,以及何时增加它们以及值来自何处。 您可能会注意到,一些驱动程序将某种类型的错误情况视为丢弃,但其他驱动程序可能会将其视为未命中。
如果这些值对您很重要,您需要阅读驱动程序源代码和设备数据表,以准确了解驱动程序认为的每个值的含义。
使用 /proc/net/dev
更高级的文件是 /proc/net/dev,它为系统上的每个网络适配器提供高级摘要式信息。
读取 /proc/net/dev 来监视高级 NIC 统计信息。
$ cat /proc/net/devInter-| Receive | Transmit face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed eth0: 110346752214 597737500 0 2 0 0 0 20963860 990024805984 6066582604 0 0 0 0 0 0 lo: 428349463836 1579868535 0 0 0 0 0 0 428349463836 1579868535 0 0 0 0 0 0
这个文件显示了您在上面提到的 sysfs 文件中找到的值的子集,但它可能作为一个有用的一般参考。
上面提到的警告也适用于这里:如果这些值对您很重要,您仍然需要阅读驱动程序源代码,以准确了解何时、何地以及为什么它们会增加,以确保您对 error、drop 或 fifo 的理解与驱动程序相同。
监控动态队列限制
您可以读取位于以下位置的文件来监控网络设备的动态队列限制:
/sys/class/net/NIC/queues/tx-QUEUE_NUMBER/byte_queue_limits/。
替换 NIC 为您的设备名称(eth0、eth1 等),替换 tx-QUEUE_NUMBER 为传输队列号(tx-0、tx-1、tx-2 等)。
其中一些文件是:
hold_time:初始化为 HZ(单个赫兹)。 如果队列在 hold_time 内已满,则减小最大大小。inflight:它是尚未处理完成的正在传输的数据包的当前数量。该值等于(排队的数据包数量-完成的数据包数量)。 limit_max:硬编码值,设置为 DQL_MAX_LIMIT(在我的 x86_64 系统上为 1879048192)。limit_min:硬编码值,设置为 0。limit:一个介于 limit_min 和 limit_max 之间的值,表示当前可以排队的对象的最大数量。
在修改任何这些值之前,强烈建议阅读这些演示幻灯片,以深入了解算法。
读取 /sys/class/net/eth0/queues/tx-0/byte_queue_limits/inflight 监控在传输过程中的数据包情况。
$ cat /sys/class/net/eth0/queues/tx-0/byte_queue_limits/inflight350
调优网络设备
检查正在使用的传输队列数
如果您的 NIC 和系统上加载的设备驱动程序支持多个传输队列,则通常可以使用 ethtool 调整 TX 队列(也称为 TX 通道)的数量 ethtool。
使用 ethtool 检查 NIC 传输队列的数量 ethtool
$ sudo ethtool -l eth0Channel parameters for eth0:Pre-set maximums:RX: 0TX: 0Other: 0Combined: 8Current hardware settings:RX: 0TX: 0Other: 0Combined: 4
此输出显示预设的最大值(由驱动程序和硬件强制执行)和当前设置。
注意: 并非所有设备驱动程序都支持此操作。
如果您的 NIC 不支持此操作,则会出现错误。
$ sudo ethtool -l eth0Channel parameters for eth0:Cannot get device channel parameters: Operation not supported
这意味着您的驱动程序尚未实现 ethtool get_channels 操作。 这可能是因为 NIC 不支持调整队列数量,不支持多个传输队列,或者您的驱动程序尚未更新以处理此功能。
调整使用的传输队列数
找到当前和最大队列计数后,可以使用 sudo ethtool -L 调整这些值。
注意: 某些设备及其驱动程序仅支持为发送和接收配对的组合队列,如上一节中的示例所示。
使用 ethtool -L 设置组合 NIC 传输和接收队列为 8
$ sudo ethtool -L eth0 combined 8
如果您的设备和驱动程序支持 RX 和 TX 的单独设置,并且您只想更改 TX 队列计数为 8,则可以运行:
使用 ethtool -L 设置 NIC 传输队列的数量为 8。
$ sudo ethtool -L eth0 tx 8
注意: 对于大多数驱动程序来说,进行这些更改将关闭接口,然后再重新打开; 与该接口的连接将被中断。 不过,这对于一次性的改变来说可能并不重要。
调整传输队列的大小
某些 NIC 及其驱动程序还支持调整 TX 队列的大小。 具体的工作原理是硬件相关的,但幸运的是,ethtool 为用户提供了一种通用的方法来调整大小。 由于使用了 DQL 来防止更高层次的网络代码在某些时候排队更多数据,因此增加发送队列的大小可能不会产生巨大的差异。尽管如此,您可能仍然希望增加发送队列到最大大小,并让 DQL 为您处理其他所有事情:
使用 ethtool -g 检查当前网卡队列大小。
$ sudo ethtool -g eth0Ring parameters for eth0:Pre-set maximums:RX: 4096RX Mini: 0RX Jumbo: 0TX: 4096Current hardware settings:RX: 512RX Mini: 0RX Jumbo: 0TX: 512
上面的输出指示硬件支持多达 4096 个接收和发送描述符,但是它当前仅使用 512 个。
使用 ethtool -G 增加每个 TX 队列的大小到 4096
$ sudo ethtool -G eth0 tx 4096
注意: 对于大多数驱动程序来说,进行这些更改将关闭接口,然后再重新打开;与该接口的连接将被中断。 不过,这对于一次性的改变来说可能并不重要。
结束
结束了! 现在你已经知道了 Linux 上数据包传输的工作原理:从用户程序到设备驱动程序再返回。
其他
有一些额外的事情值得一提,值得一提的是,似乎不太正确的其他任何地方。
减少 ARP 流量(MSG_CONFIRM)
send、sendto 和 sendmsg 系统调用都采用 flags 参数。 如果您传递 MSG_CONFIRM 标志给应用程序中的这些系统调用,它将导致内核中发送路径上的 dst_neigh_output 函数更新邻居结构的时间戳。 这样做的结果是相邻结构将不会被垃圾收集。 这可以防止产生额外的 ARP 流量,因为邻居缓存条目将保持更热、更长时间。
UDP Corking
我们在整个 UDP 协议栈中广泛地研究了 UDP corking。 如果要在应用程序中使用它,可以调用 setsockopt 启用 UDP corking,设置 level 为 IPPROTO_UDP,optname 设置为 UDP_CORK,optval 设置为 1。
时间戳
正如上面的博客文章中提到的,网络栈可以收集传出数据的时间戳。 请参阅上面的网络栈演练,了解软件中的传输时间戳发生的位置。 一些 NIC 甚至还支持硬件中的时间戳。
如果您想尝试确定内核网络栈在发送数据包时增加了多少延迟,这是一个有用的特性。
关于时间戳的内核文档非常好,甚至还有一个包含的示例程序和 Makefile,你可以查看!
使用 ethtool -T 确定您的驱动程序和设备支持的时间戳模式。
$ sudo ethtool -T eth0Time stamping parameters for eth0:Capabilities: software-transmit (SOF_TIMESTAMPING_TX_SOFTWARE) software-receive (SOF_TIMESTAMPING_RX_SOFTWARE) software-system-clock (SOF_TIMESTAMPING_SOFTWARE)PTP Hardware Clock: noneHardware Transmit Timestamp Modes: noneHardware Receive Filter Modes: none
不幸的是,这个网卡不支持硬件传输时间戳,但是软件时间戳仍然可以在这个系统上使用,以帮助我确定内核给我的数据包传输路径增加了多少延迟。
结论
Linux 网络栈很复杂。
正如我们上面看到的,即使像 NET_RX 这样简单的东西也不能保证像我们期望的那样工作。 即使RX 在名称中,传输完成仍在此 softIRQ 中处理。
这突出了我认为是问题的核心:除非您仔细阅读并理解网络栈的工作原理,否则无法优化和监控网络栈。您无法监控您不深入了解的代码。
原文: Monitoring and Tuning the Linux Networking Stack: Sending Data
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/04-25-2023/monitoring-and-tuning-the-linux-networking-stack-sent-cn.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!
]]>
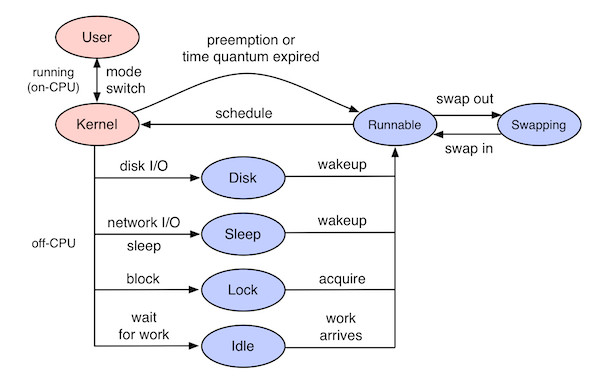
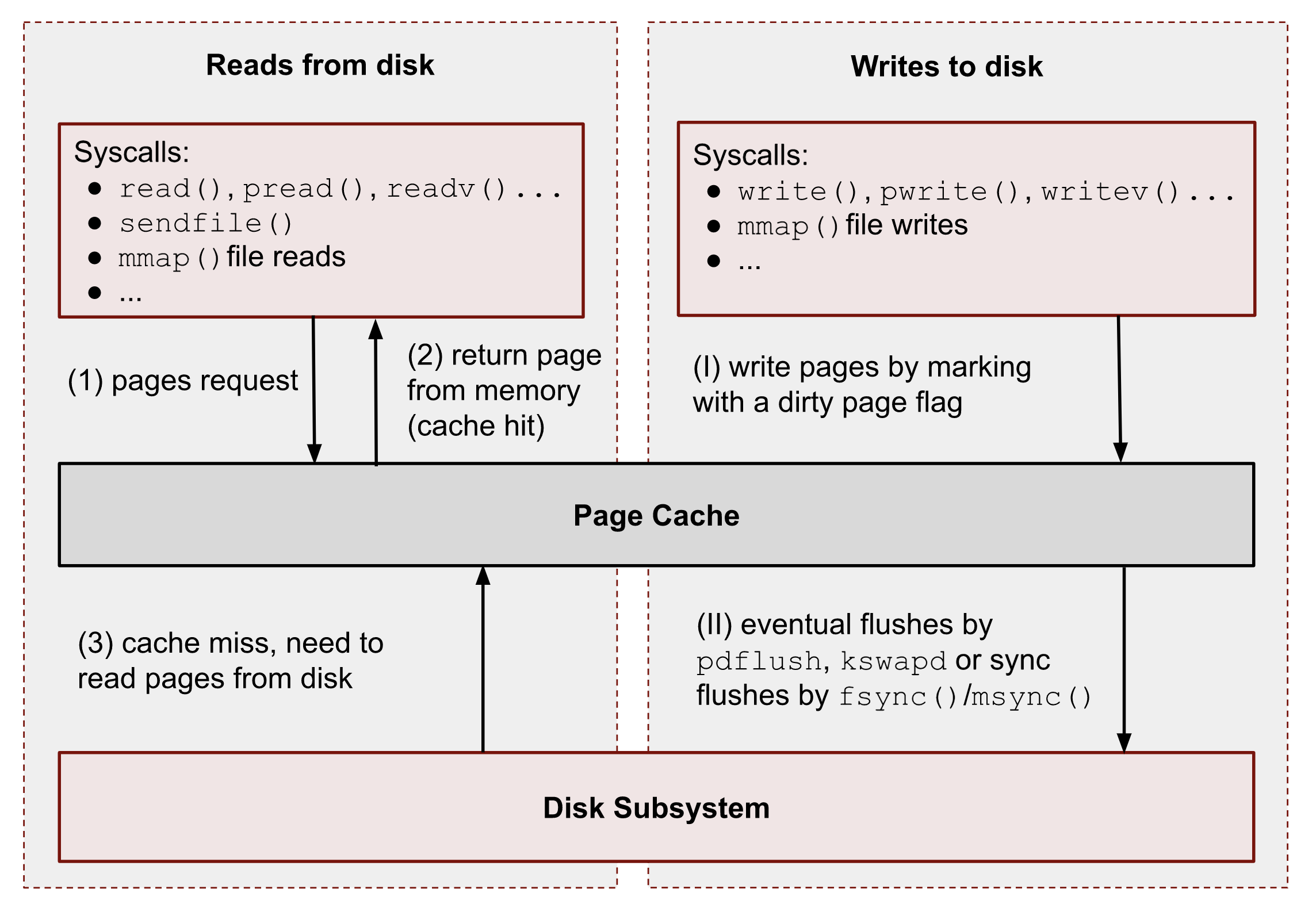
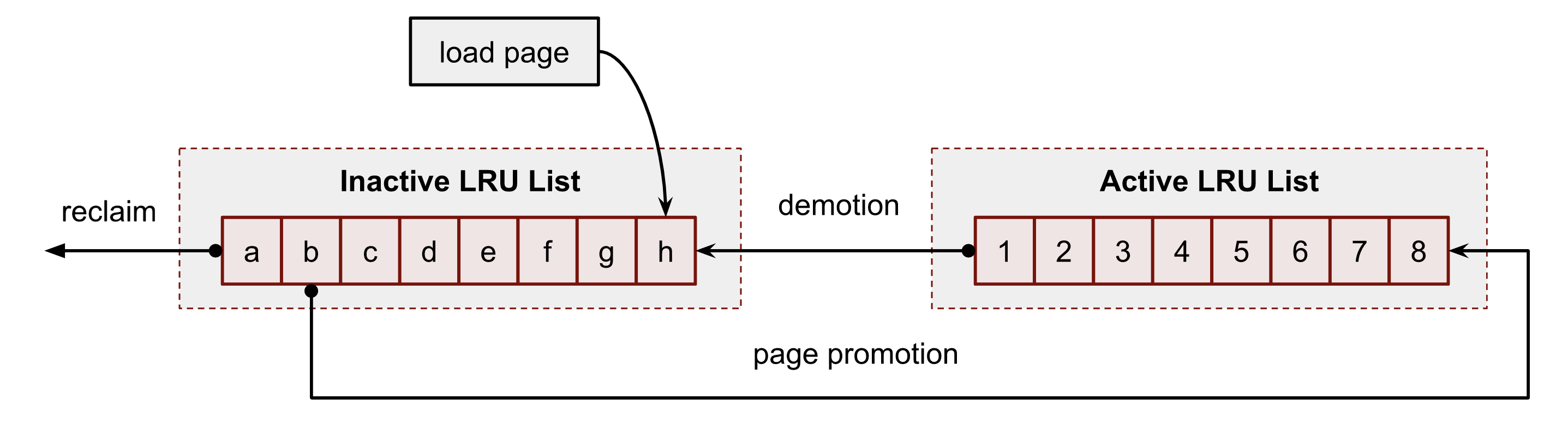






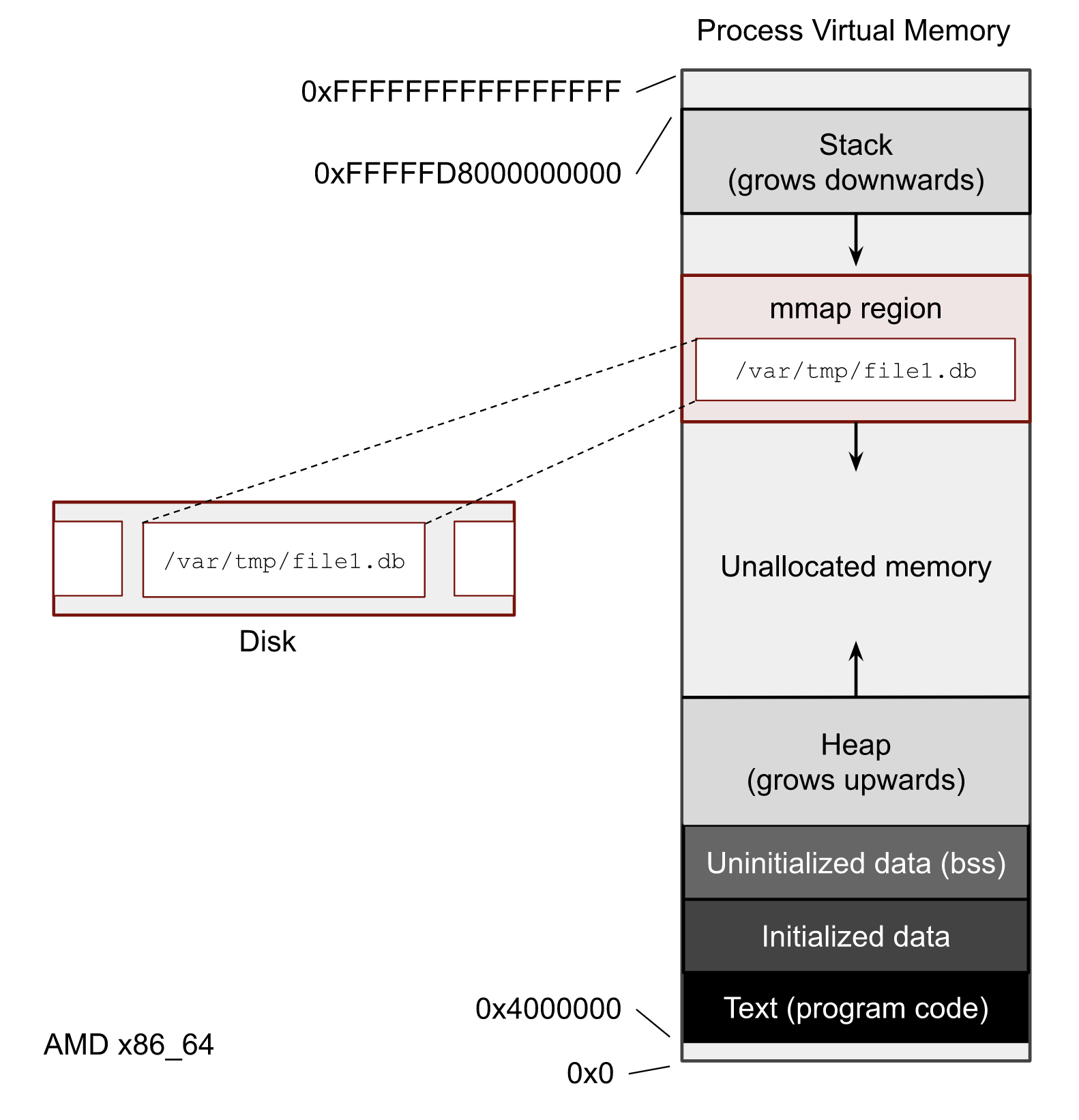
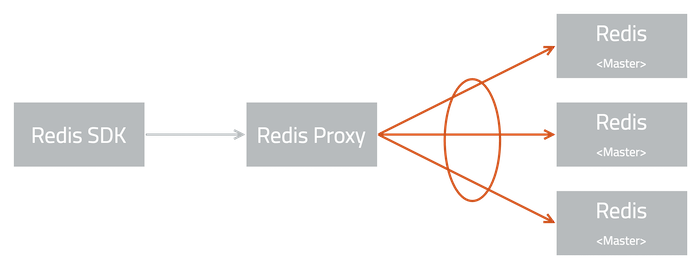
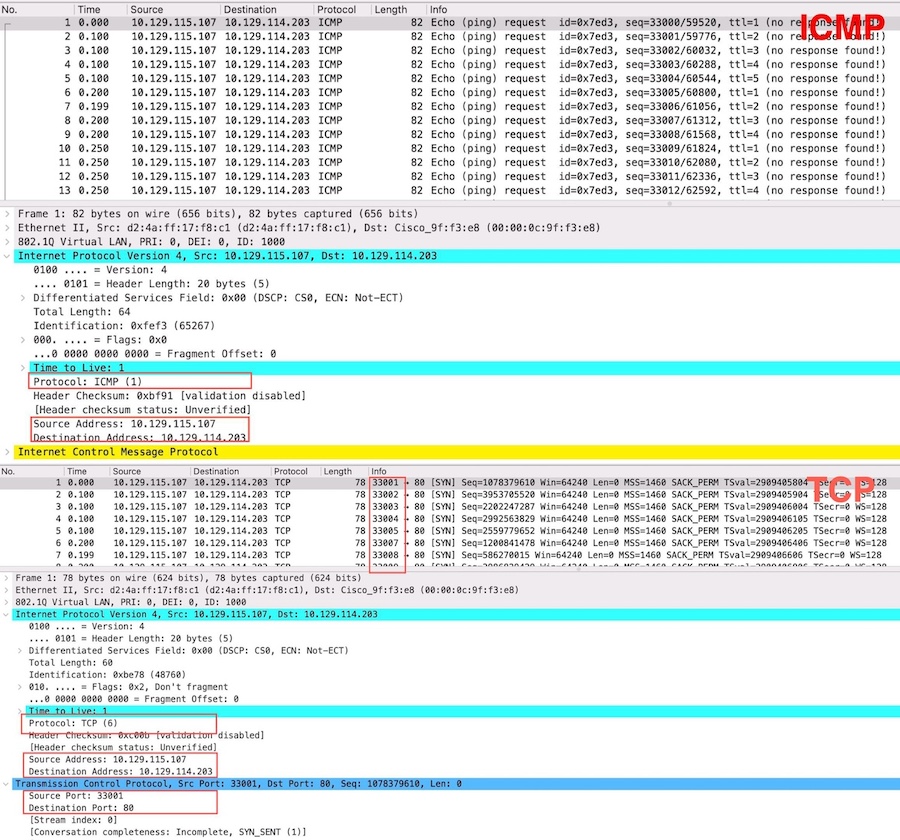

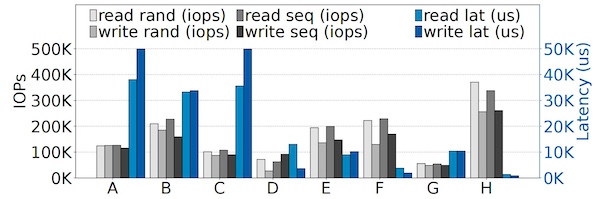
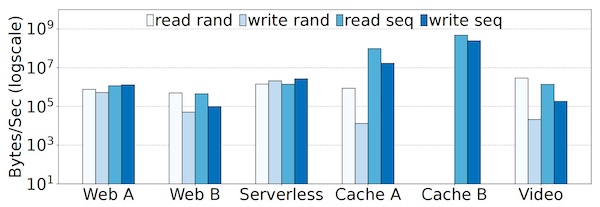
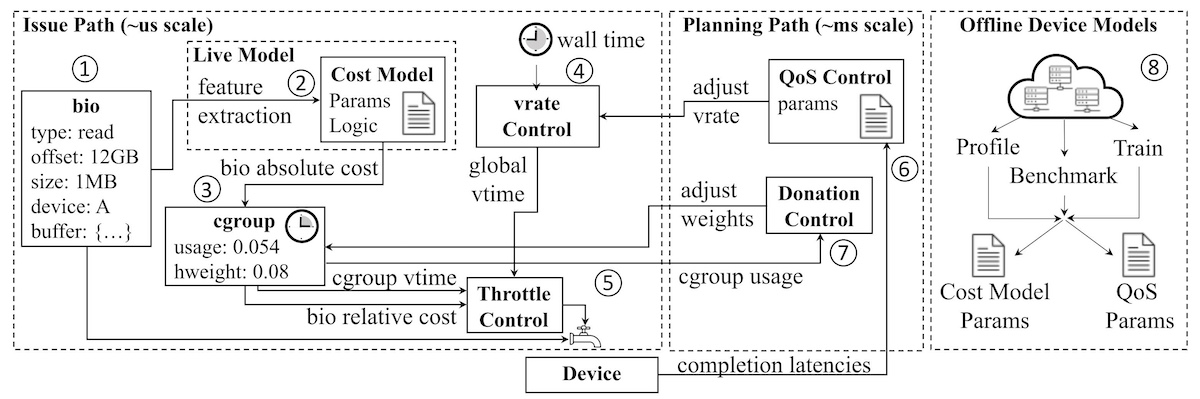


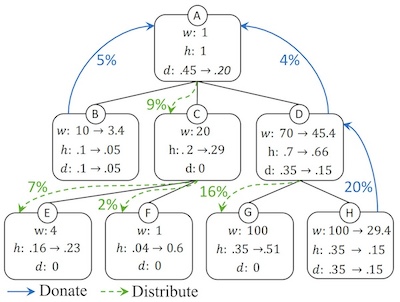
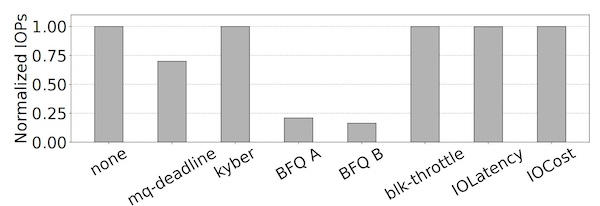
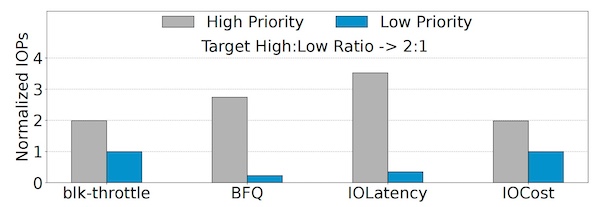
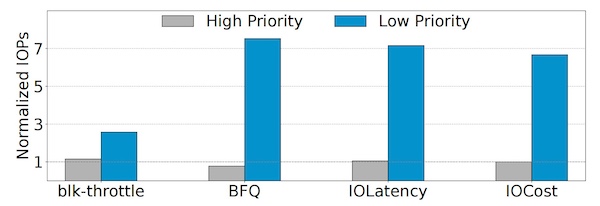
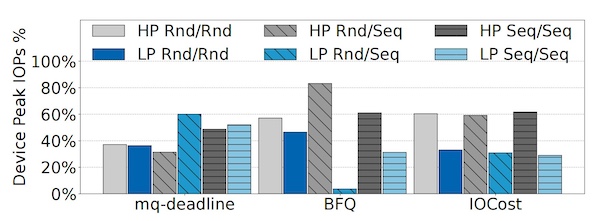
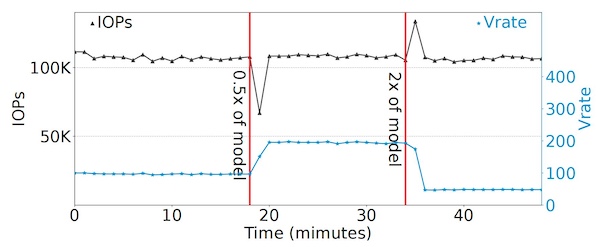
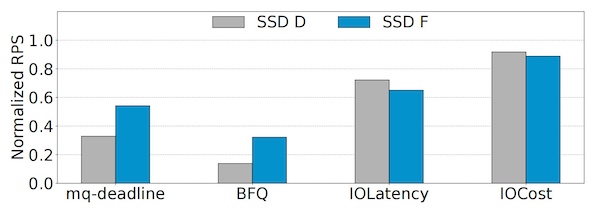
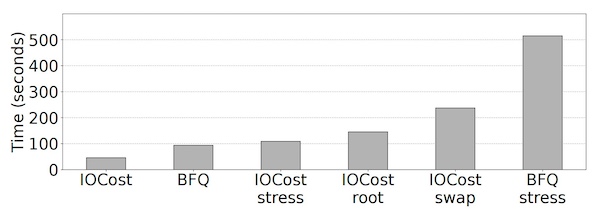
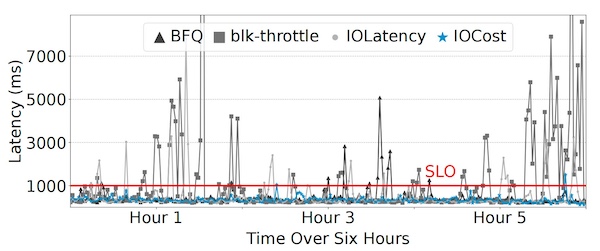
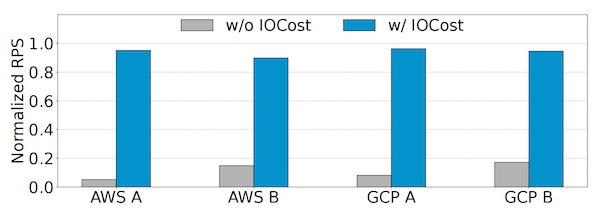
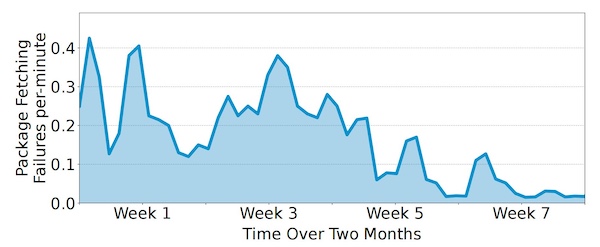
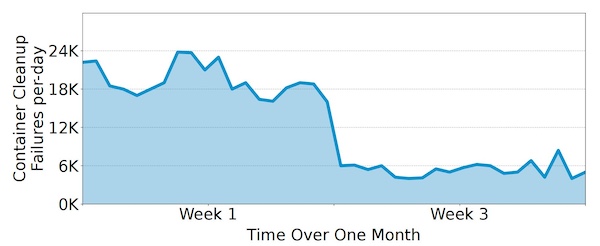
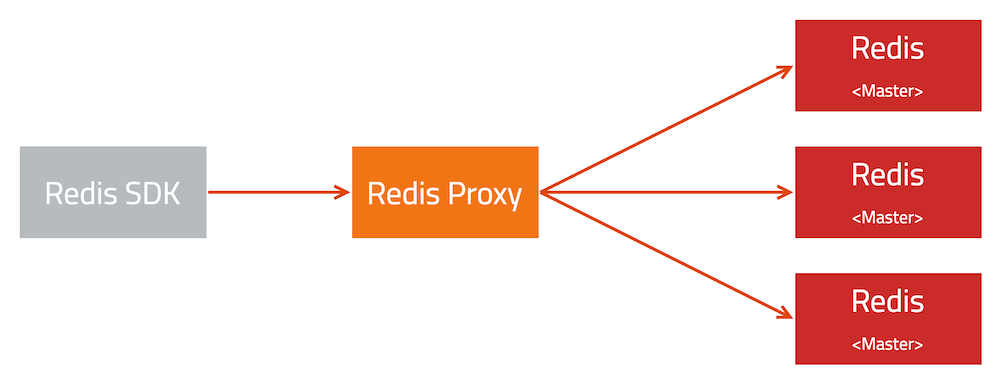
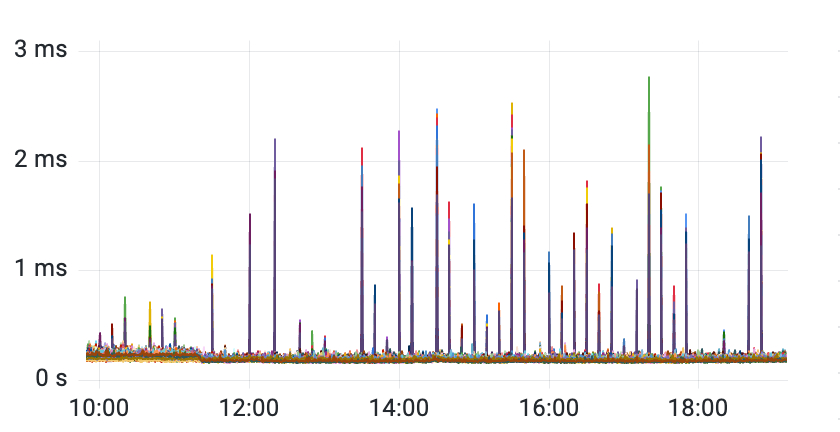

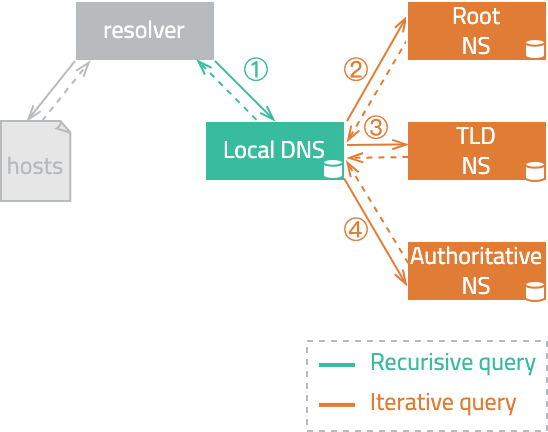
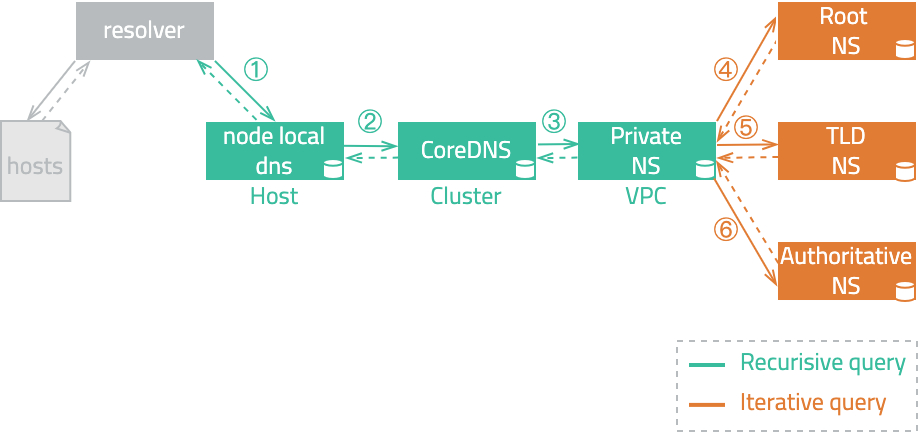

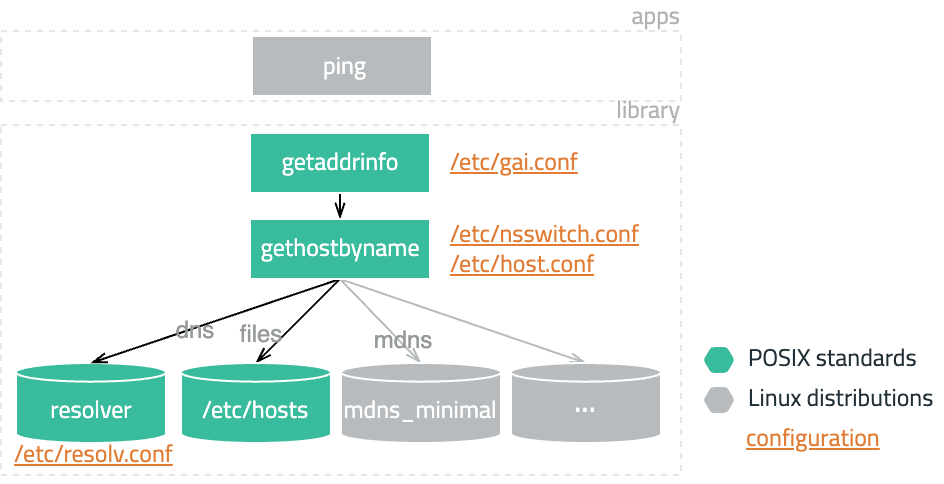
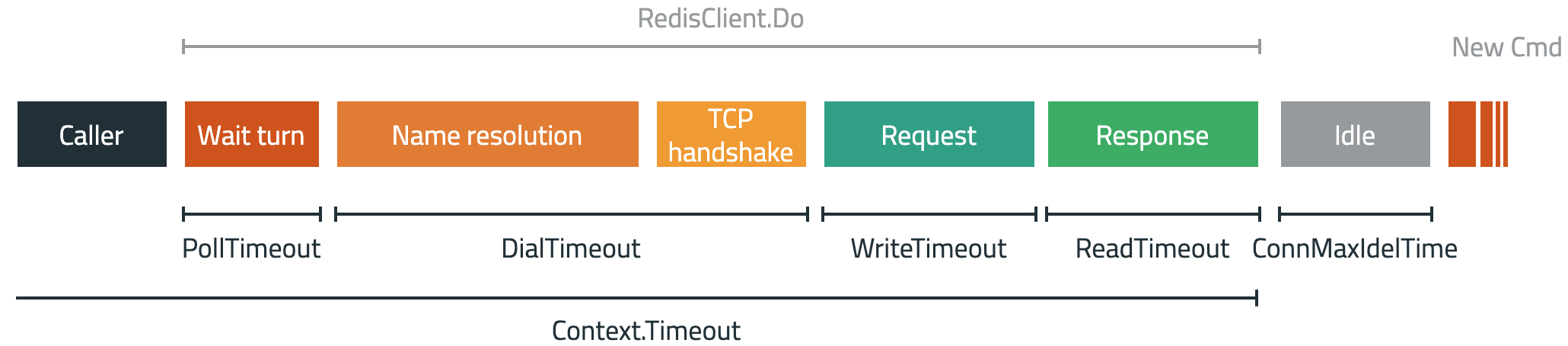
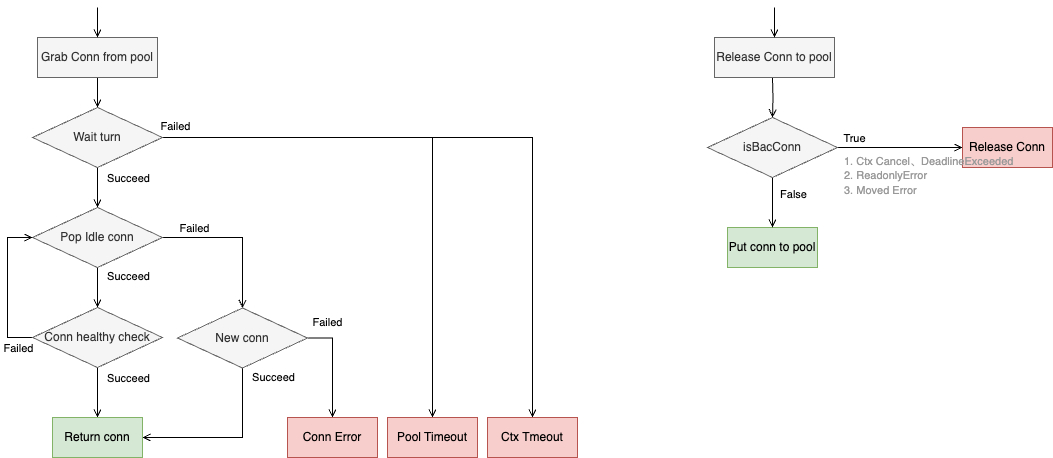
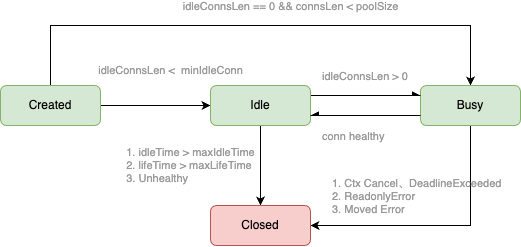
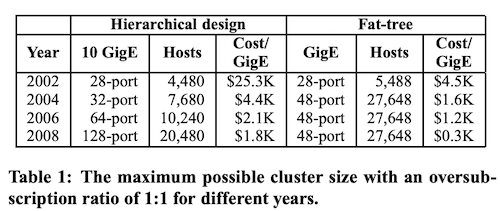
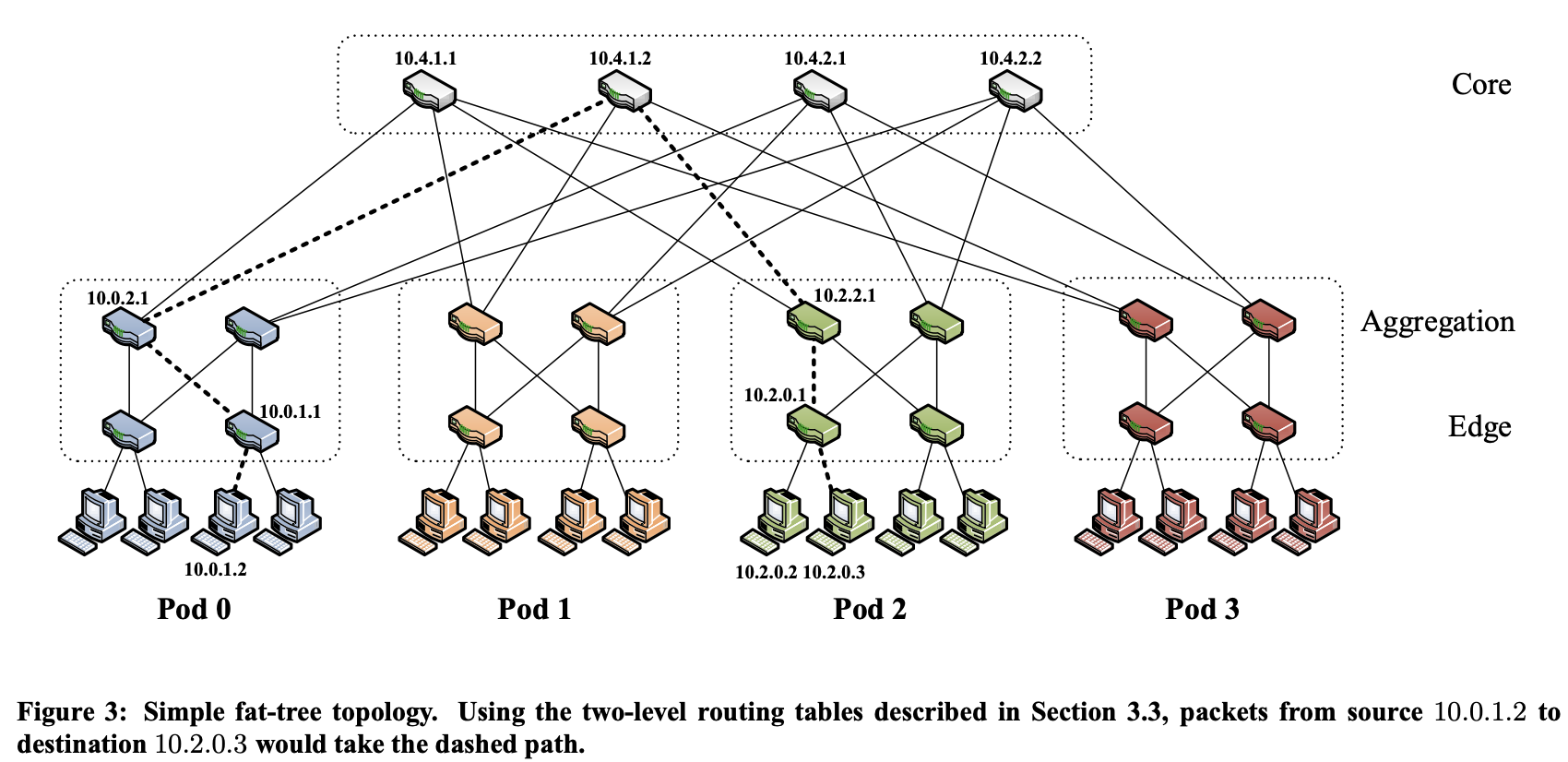

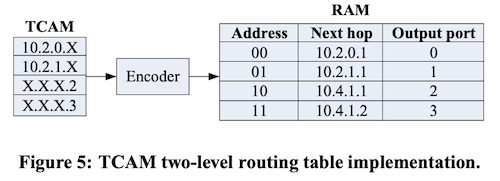

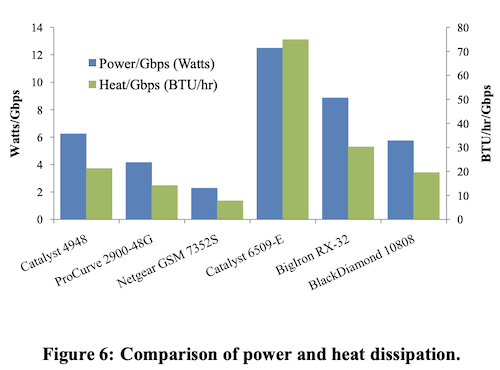
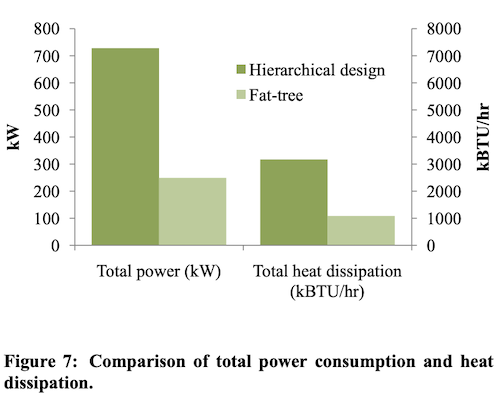

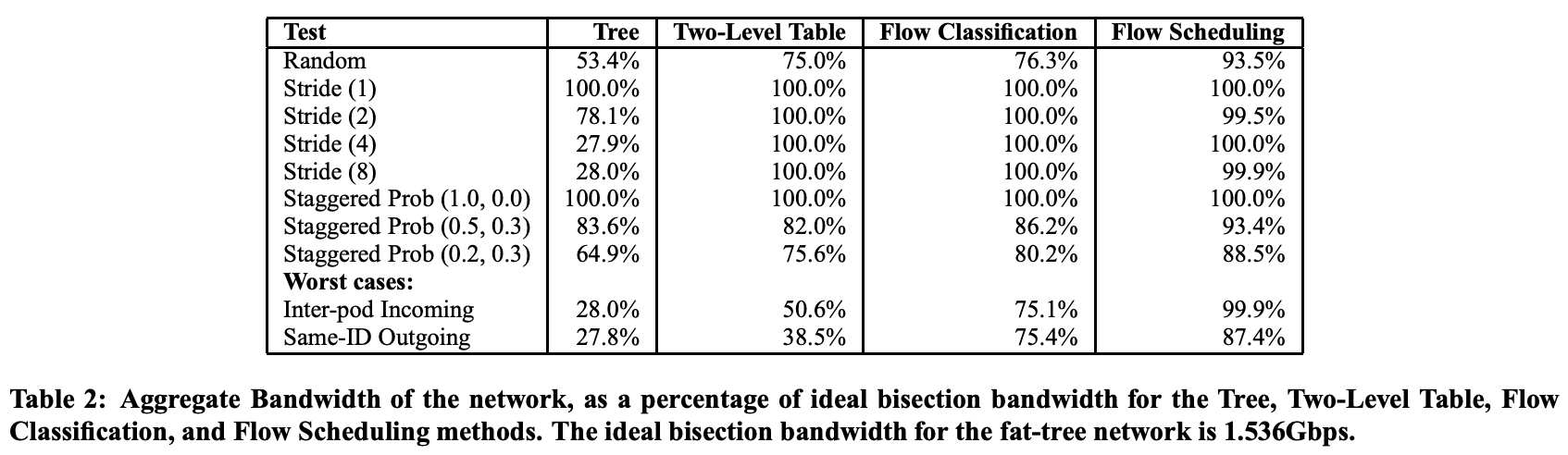
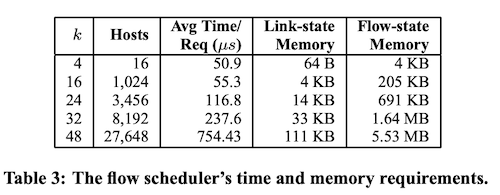
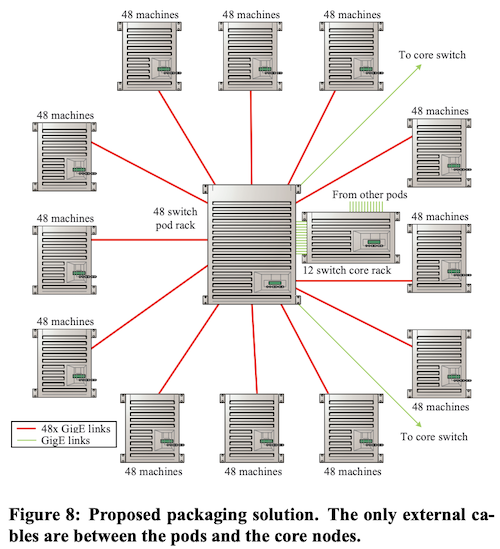
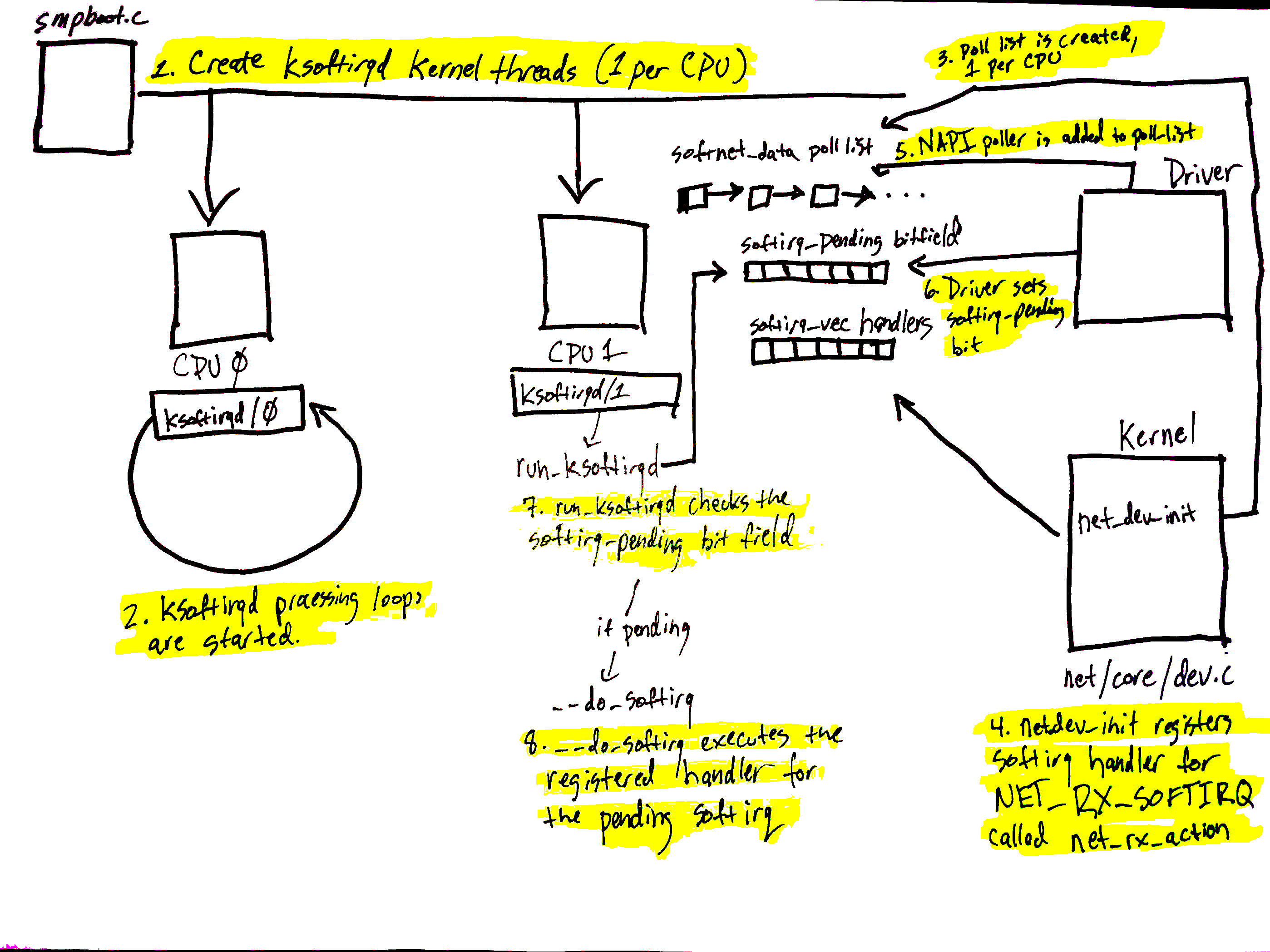

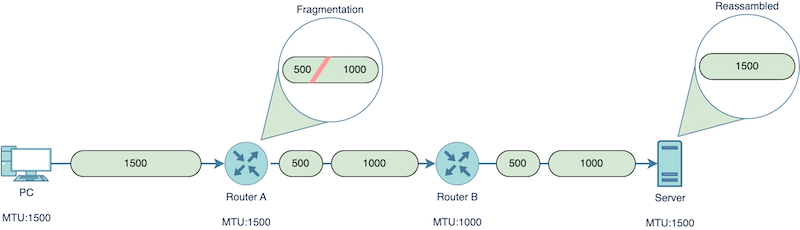

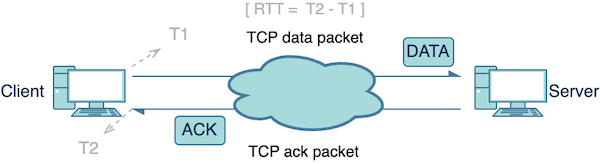
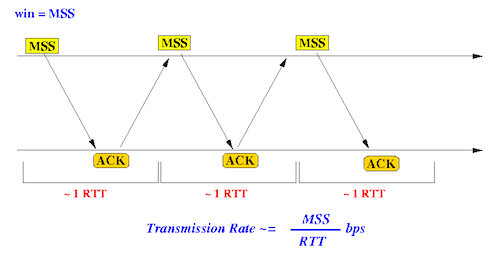
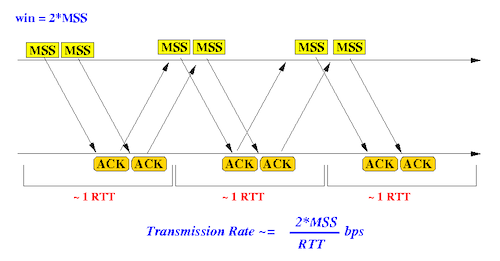
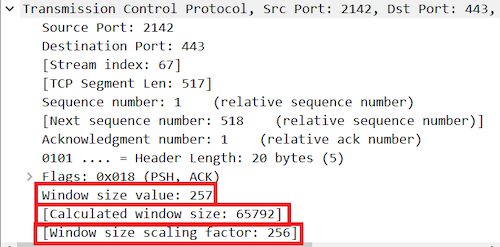
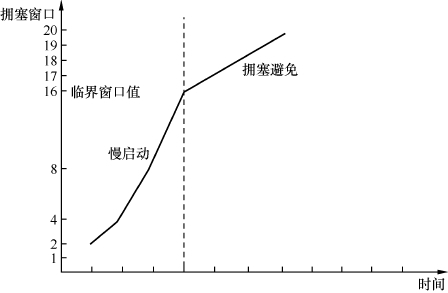

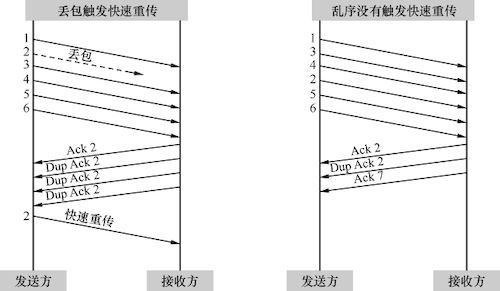

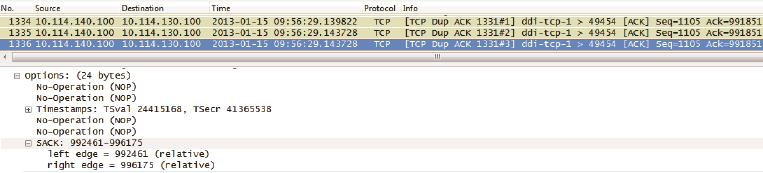
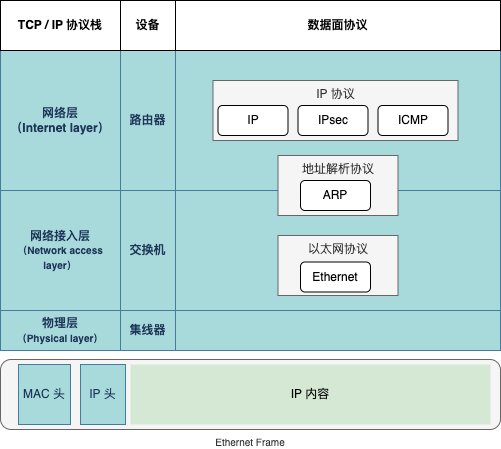
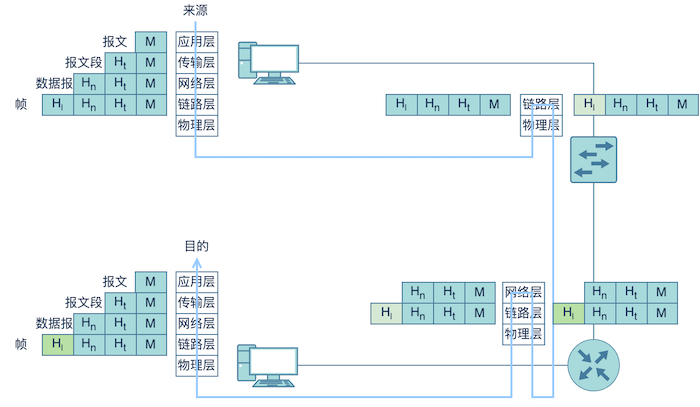
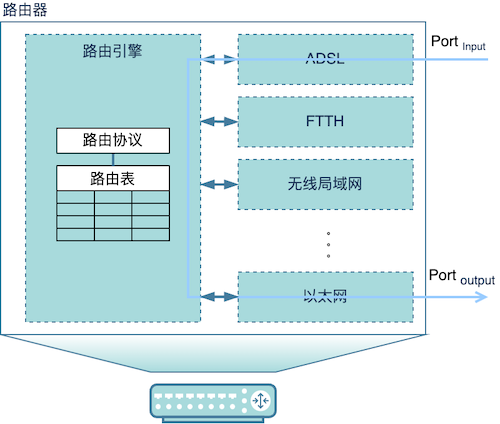
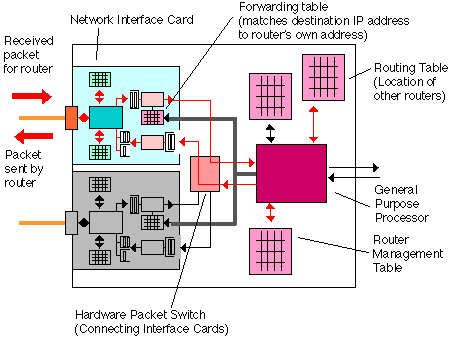
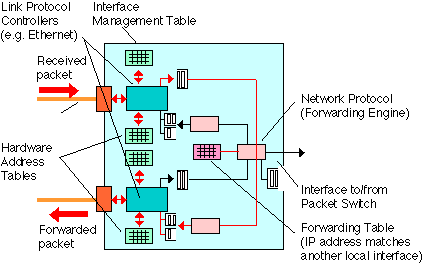
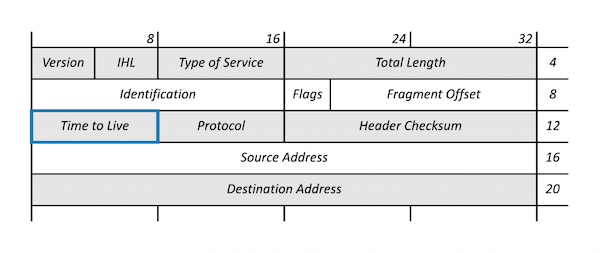

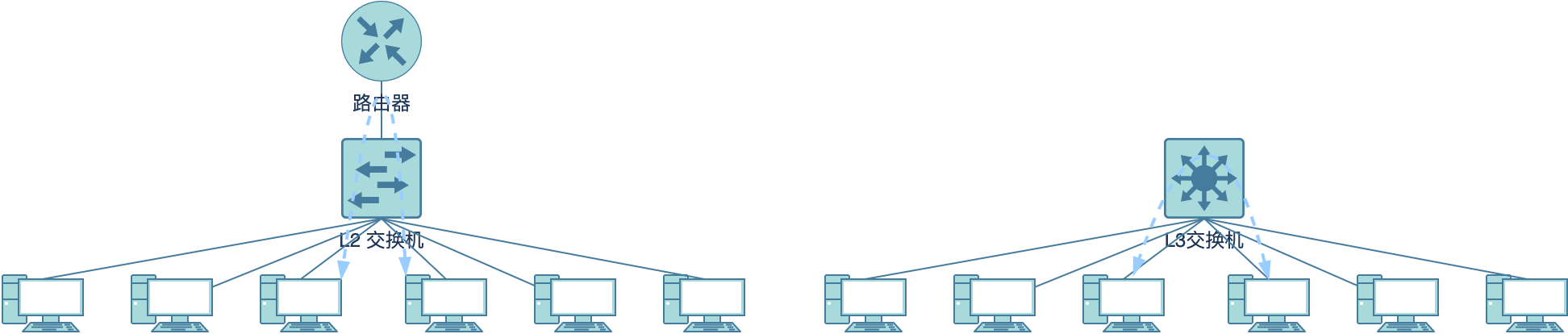

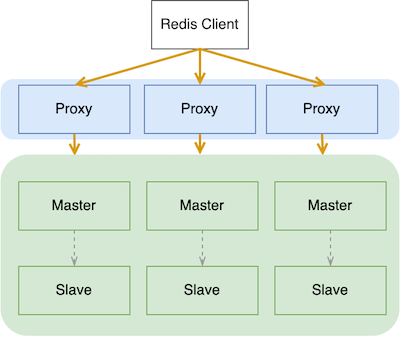
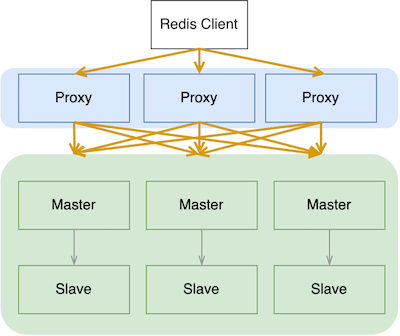
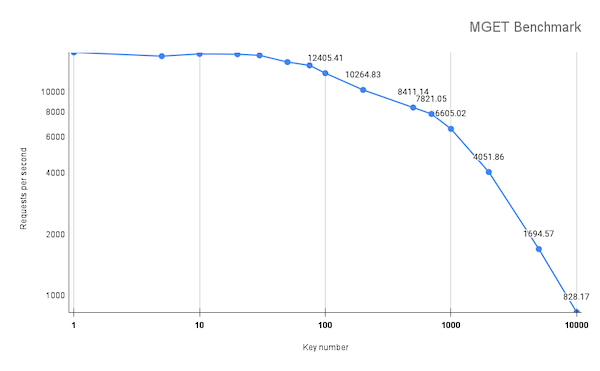
{kind=link}