
Thrift是一个加快高效、可扩展后端服务开发和实现的开源库,它轻量级框架和对跨语言通信的支持,使得它的许多操作比其他类似SOA(REST/SOAP)的RPC框架更强大、高效。然而,Thrift的能力倍受新兴企业解决方案的挑战,例如,大数据方面,由于一个端口绑定一个服务的局限性,增加了绑定多种业务的企业网络的可维护性和管理的成本。本文针对这一挑战,详细介绍了增强Thrift能力的实现方法,使其能满足企业的期望。
介绍
Thrift是一个非常轻量的用于开发和获取远程服务的框架,它在跨语言通信方面,可靠,扩展性好、高效。Thrift API 被各企业广泛用于创建如搜索,日志记录,移动广告等类似服务和开发者平台。HBase、Hive、Cassandra等大数据开源项目的服务都承载于Thrift。简单,版本控制支持,开发高效和可扩展性使其成为SOA市场的有力竞争者,帮助它在与多数已有集成方法和产品的竞争中取得成功。
Thrift具有支持大量的功能,服务的跨语言沟通能力。这种能力可以通过扩展Thrift支持在每个服务器上绑定多个services得到进一步加强。在本白皮书中,我们将讨论如何提高Thrift的能力,以善用企业资源。基于标准的环境,我们还提出了一个框架,可以支持服务器绑定多个services的创建,服务的注册和服务的查询。
Thrift有何特别之处?
在开源舞台上有多种类型的RPC实现,包括Thrift、Avro、MessagePack、Protocol Buffers、BSON等等。每一个RPC实现库都有自己的优点和缺点。理想情况下,我们应该根据项目特定的企业解决方案的需求选择RPC库。
所有RPC实现追求的特性:
1.跨平台通信
2.多种编程语言
3.支持快速协议(本地,二进制,压缩等)
4.支持多种传输
5.灵活的服务器(配置无阻塞,多线程等)
6.标准的服务器和客户端实现
7.与其他的RPC库的兼容性
8.支持不同的数据类型和容器
9.支持异步通信
10.支持动态类型(无架构编译)
11.快速序列化
与其他RPC实现,Thrift、Avro、MessagePack是顶级竞争者,满足以上列出的大多数需求。Avro的实现中,低频会话时服务器和客户端的带外模式会成为过度之举。同时,MessagePack本质上基于JSON并且无scheme的类型检查,由于数据类型容器的缺乏,比Thrift要弱。另一方面,支持各种协议和传输,可配置的服务器,简单标准化的IDL,和久经实战集成于大数据NoSQL数据存储,如Cassandra,使Thrift成为一个强大的竞争者和企业解决方案的首选RPC实现。
Thrift功能强大,但尚缺少功能
尽管是一个强大、高效率的跨语言通讯的工具,Thrift的services倍受高管理和维护成本的挑战。实际上,每一个Thrift服务器能够在同一时间公开唯一一个service。为了绑定多种功能,Thrift为企业提供以下两个选项:
1.写一个唯一、笨拙的实现并丙丁它作为单一服务
2.绑定多个小服务到一系列端口
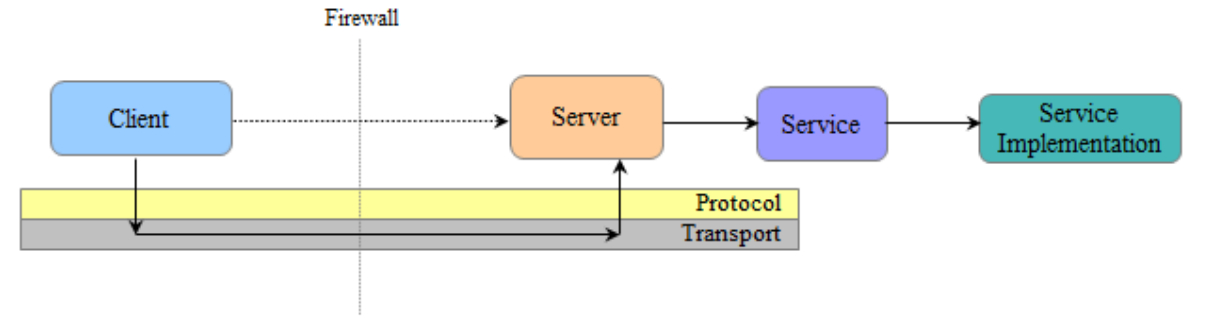
如果企业做选择第一种选项:那么,唯一、笨重的实现增加了解决方案的开发成本。该解决方案的复杂性将随着每个新服务的增加而增长。投资回报率(ROI)将由于高昂的维护成本受到不利影响。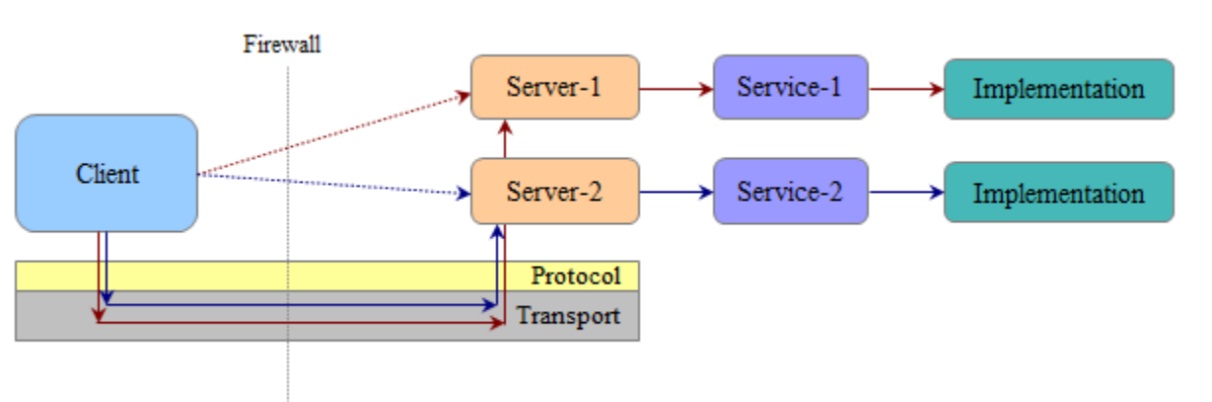
如果企业选择第二种选项,绑定多个服务消耗的端口数量会很高,由于端口是一种有限的企业资源,需要谨慎使用,这是一个严重的问题。此选择倍受高管理和维护成本的挑战。此外,为防止与每个调用连接建立的相关成本,客户端的必须保持很多的连接(至少有一个到每一个端口)。每增加一个新的service,必须在防火墙上打开新的端口。Thrift的灵活设计在解决方案的优势备受高管理成本的挑战。
通过复用为优秀的API增加魅力
需要一个小时以实现和利用Thrift API的潜力,克服每个服务器绑定唯一service的局限。这份白皮书提出的解决方案是试图建立一个框架,可以使Java开发人员能够在每个服务器上创建和绑定多个services。该解决方案还提供了一个查询的框架,任何Java客户机/服务器可以快捷方便的查找和使用每个服务器上所托管的services,
方案
基本的方法是分配一个本文称作“service context”的符号给每个服务。这将帮助我们绑定多个services到一个服务器上,每一个service可以被各自的service context识别。使用查找服务的客户端应该能够获取合适的service context,并引导服务调用到各自的服务者。
组件
该解决方案扩展了Thrift API引进一些如下提到的新的组件(图1.3红色边界高亮):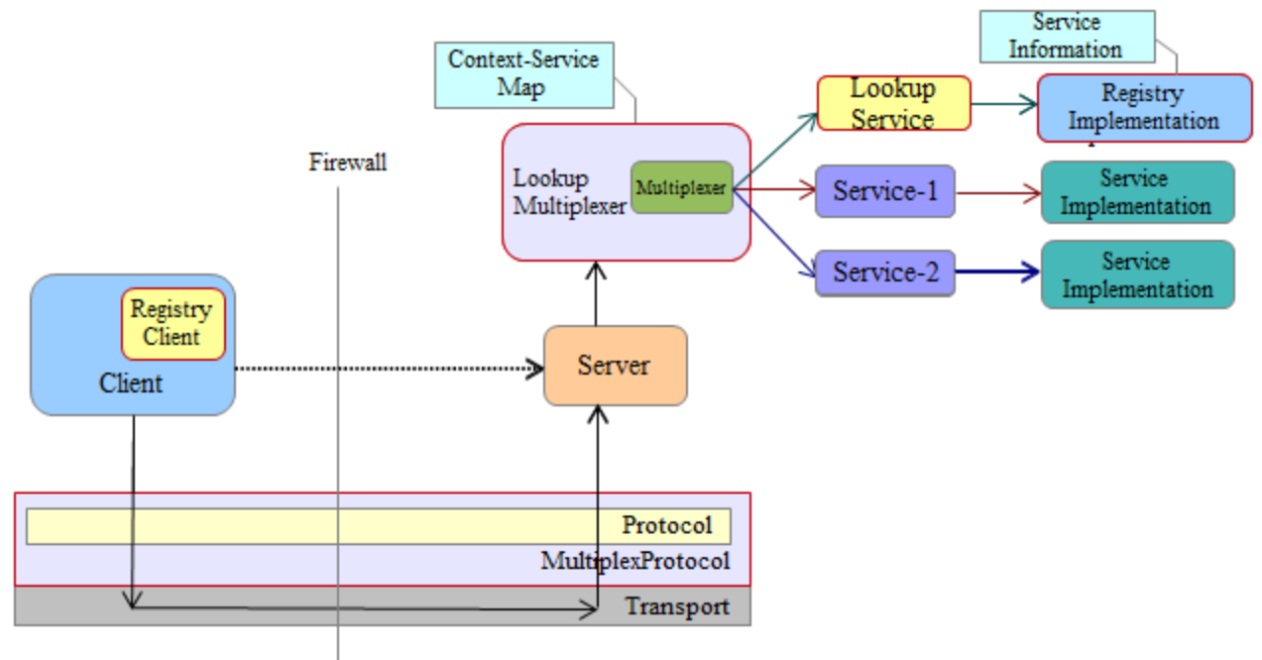
Multiplexer
复用器(Multiplexer)是Processor,是本方案的核心。该组件作为服务器端请求代理并负责根据由客户端传输的service context识别客户端请求。此组件保持service context和service之间的映射。在处理任何请求时,它读取来自底层协议的service context,并根据该映射,将请求定向到适当的service。
Protocol
在我们的方法中,我们使我们的解决方案transport和protocol无关。我们创建了一层底层协议(协议的任何实例)的封装,客户端侧把service context嵌入消息,并在服务端侧查找它。因此,我们增加了一个新的类TMultiplexProtocol包装现有的TProtocol,它重写writeMessageBegin (TMessage)和readMessageBegin()方法的行为。所有与TMultiplexer进行通信的客户端需要使用TMultiplexProtocol实例来包装底层协议。
Registry and Lookup
为了减少与手动管理service context相关的开销,我们在此解决方案中创建了一个registry组件,负责管理托管在特定服务器上的所有service。该组件托管为底层复用器上的一个service,客户端可以通过在TMultiplexerConstants.LOOKUP_CONTEXT查询绑定service的相关信息进行查询。TRegistry是基本的用于查询lookup registry的客户端侧API接口。它提供了多种查询方法查询registry,如基于service context、服务名称、正则表达式。这也方便了用户使用registry检查任何service context的存在,以及列出所有可用的服务上下文。TRegistryHelper是服务端侧的API接口,它使用lookup registry用于绑定,重新绑定和解除绑定service context。我们已经提供了registry API的基本实现,执行service context内存管理的TRegistryBase。基于特定的需求,该组件可以通过覆盖默认方法进行扩展,并且可以与工厂类一起使用。TRegistryClientFactory是用于创建registry client的工厂类,便于远程查找registry。
Service Information
本解决方案采用了URIContext类体现/代表绑定在特定服务器上的services的信息。这个对象能够在网络中传输;,因此客户端可以远程访问。service context、服务名称和描述由目前的解决方案代表作为该信息的一部分。
#####Multiplexer-extension for lookup
就其本身而言,Multiplexer能够绑定多个service。然而,管理服务信息是客户端和服务端管理者的成本。为了减少这方面的成本,我们引入了registry组件,能够管理服务信息。为了充分利用在单处理器的Multiplexer和registry组件的能力,我们引入了新的processor TLookupMultiplexer,能够使用一个额外的基于registry的查找服务承载多个service。因此,处理器创建一个拥有所有service信息的registry的实例,并将其公开为一项额外的服务给客户。使得客户端能够使用Registry API,并使用查询后所得到的service context访问底层服务。
Server
我们提出了一个新的抽象server,TMultiplexingServer,它可以使用TLookupMultiplexer绑定任何server信息到任何transport和任何protocol。该类抽象了对象创建的底层复杂性,并公开两个抽象方法,getServer和configureMultiplexer,用来被任何继承该类的类实现。该类使得用户可以在创建server对象时识别出server transport、protocol,因此提供了额外的灵活性,当涉及到将不同的transport和protocol的多个service绑定到同一server,而无需额外的编码工作。
Source Code
我们扩展了Thrift Java库【version 0.9.0】,并增加了一个以ext命名的源文件夹,包含multiplexing组件的底层实现。此外,build.xml已被修改以先后和扩展的源代码。该方案的兼容性已经过测试与目前稳定版本0.8.0 Thrift无缝继承。为了使用Thrift的multiplexing功能,你需要从git-hub download/pull扩展的Thrift库源代码,然后在下载的Thrift Java库上运行ant命令。这将在build文件夹中生成libthrift-xxx.jar,可以被开发人员用于创建自己的企业解决方案。
怎样使用Thrift Multiplexing?
multiplexing server可以通过扩展org.apache.thrift.server.TMultiplexingServer类,并通过实现抽象方法configureMultiplexer()和getServer(TServerTransportserverTransport,TProtocolFactoryprotFactory,TProcessor processor)来创建。示例代码提供如下:
第一步:继承TMultiplexingServer类创建server类。
public class Server1<T extends TServerTransport, F extends TProtocolFactory>
extends TMultiplexingServer<T, F>第二步:有选择的重载默认的构造函数以接收server transport和protocol。
public Server1(T serverTransport, F protFactory) {
super(serverTransport, protFactory);
}第三步:实现configureMultiplexer()方法以配置lookup multiplexer。作为配置的一部分,你需要创建包含绑定到server上所有service以及相应的service information详细信息列表的MultiplexerArgs。示例如下,我们已经绑定HR和Finance service到Server1
@Override
protected List<MultiplexerArgs<URIContext, TProcessor>> configureMultiplexer() {
// list of multiplexer arguments
List<MultiplexerArgs<URIContext, TProcessor>> args = new ArrayList<MultiplexerArgs<URIContext, TProcessor>>();
// configuring HR service context
TProcessor processor = new HRService.Processor<HRServiceImpl>(
new HRServiceImpl());
URIContext context = new URIContext(Constants.HR_CONTEXT,
"HumanResource_Service");
MultiplexerArgs<URIContext, TProcessor> arg = new MultiplexerArgs<URIContext, TProcessor>(
processor, context);
args.add(arg);
// configuring FIN service context
processor = new FinanceService.Processor<FinanceServiceImpl>(
new FinanceServiceImpl());
context = new URIContext(Constants.FIN_CONTEXT, "Finance_Service");
arg = new MultiplexerArgs<URIContext, TProcessor>(processor, context);
args.add(arg);
return args;
}第四步:实现getServer(…)方法以创建目的Server的实例。在下面的示例中,我们使用参数创建了一个TThreadPoolServer的实例。
@Override
protected TServer getServer (TServerTransport serverTransport, TProtocolFactory protFactory, TProcessor processor) {
//creating server args
Args serverArgs= new Args(serverTransport);
serverArgs.protocolFactory(protFactory);
serverArgs.transportFactory(new TTransportFactory());
serverArgs.processor(processor);
serverArgs.minWorkerThreads=1;
serverArgs.maxWorkerThreads=5;
//creating server instance
return new TThreadPoolServer(serverArgs);
}第五步:使用合适的transport和protocol创建server类的实例,并启动server
public static void main(String[] args) {
//identifying server transport
TServerSocket SERVER1_TRANSPORT = new TServerSocket(Constants.SERVICE1_PORT);
//identifying server protocol
Factory SERVER1_FACTORY = new TBinaryProtocol.Factory();
//creating server instances for specific transport and protocol
Server1<TServerSocket, TBinaryProtocol.Factory> server1 = new Server1<TServerSocket, TBinaryProtocol.Factory>(SERVER1_TRANSPORT, SERVER1_FACTORY);
//starting server
server1.start();
}创建一个客户端查询registry并使用service context
一个来查询multiplexing server registry的客户端可以从org.apache.thrift.registry.TRegistryClientFactory类获得。class.TRegistryClientFactory是便利类,它提供multiplexing客户端的实例。在客户端侧,你可以使用工厂的静态方法getClient(..)以获取registry客户端。它可以进一步用来查询registry和确定合适的server处理该请求。下面提供的示例代码是关于客户端使用的finance service检索雇员的税务细节的客户端:
public double getTaxDetails(intempId){
TTransport transport = null;
TProtocol protocol = null;
try {
//transport
transport = new TSocket(Constants.SERVICE_IP,
Constants.SERVICE1_PORT, 60);
//Multiplexing protocol
protocol = Factory.getProtocol(new TBinaryProtocol(transport),
TConstants.LOOKUP_CONTEXT);
//Procuring Registry client
TRegistry client = TRegistryFactory.getClient(protocol);
//opening transport
transport.open();
//querying registry to get context
Set<URIContext> contexts = client.lookupByName("Finance_Service");
//executing the request on appropriate service using the context
if(contexts.size()==1){
URIContext uricontext = contexts.iterator().next();
protocol =
newTMultiplexProtocol(newTBinaryProtocol(transport),uricontext.getContext())
;
com.service.FinanceService.Client finService = new
com.service.FinanceService.Client(protocol);
return finService.getTaxDeductedTillDate(empId);
}
}finally {
if(transport!=null)
//closing transport
transport.close();
}
}明智的投资利润丰厚
Thrift在当今的企业环境中有巨大优势,因为它通过有效的方式解决了所有大数据解决方案带来的挑战,并提供了一个公开为整个网络提供服务的解决方案。大多数企业,特别是在生产环境中,具有有限的端口,打开新的端口将引入相关的成本。使用Thrift作为解决方案的RPC机制是考虑到端口的有限。此外,像Hadoop、Hive、HBase、Cassandra、NoSQL数据存储等等,以及其他企业软件,如Web服务器、应用服务器和ESBs已经使用了多个端口。在成本和资源方面,如果企业将服务公开到网络上,然后为每个服务打开额外的端口是低效的。这一企业问题,可以通过Thrift multiplexing的帮助,减少端口数为一个,用很小的开发和管理开支绑定所有的服务。
一个组织投资于这项技术肯定会收获快速的周转时间和开发成本低的好处。此外,从长远来看,对复用做扩展,减少了企业的维护和管理费用,使得这项投资的利润丰厚。随着复用,多个services可以绑定在一个Thrift服务器上,从而降低维护成本。服务的模块化设计可以使用复用减少服务未来发展的成本,引入新的服务/功能或修改现有服务。因此,复用以其简单的实现,不仅使投资划算,而且使业务增值。
总结
因为可靠和高效的方式跨编程语言通信,近来Thrift已经成为一项强大的技术。企业应对大数据等先进技术,可以使用Thrift解决方案通过有效地利用企业资源以低维护成本,来绑定多个服务到网络。
参考:
[1] http://thrift.apache.org/
[2] http://avro.apache.org/
[3] http://msgpack.org/
[4] http://code.google.com/p/protobuf/
[5] http://bsonspec.org/
[6] http://hbase.apache.org/
[7] http://hive.apache.org/
[8] http://cassandra.apache.org/
[9] git://github.com/impetus-opensource/thrift.git
英文原文:
(完)
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/04-17-2014/multiplexing-in-thrift-enhancing-thrift-to-meet-enterprise-expectations.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!