
接上篇:Thinking Clearly about Performance (Part 1)
效率
即使整个系统中的每个人都在遭受痛苦,你仍然应该首先关注业务需要第一个改进的程序。首先确保程序尽可能高效地工作。在不增加容量和不牺牲所需的业务功能的情况下,效率与任务执行的总处理时间成反比。
换句话说,效率与滥用成反比。以下是数据库应用中常见的一些滥用的示例:
- 中间层程序为每一行插入到数据库的数据创建一条不同的SQL语句。它本可以用一个
prepare调用(从而减少9999次网络I/O调用)完成任务,却执行10000次数据库prepare调用(因而产生10000次网络I/O调用)。 - 中间层程序执行100次数据库 fetch 调用(因而产生100次网络I/O调用)以获取994行数据。它本可以用10次 fetch 调用获取994行数据(从而减少90次网络I/O调用)。
- 一条SQL语句访问数据库缓存7428322次以返回698行的结果集。添加一个筛选谓词返回最终用户真正希望看到的7行,可以只访问数据库缓存52次。(选择该措辞是彻底的泄密:我是在 Oracle 社区初次了解 SQL 的)
当然,如果一个系统存在一些全局性问题,导致整个系统中的大量任务效率低下(例如,考虑不周的索引、设置错误的参数、配置不当的硬件),那么你应该改进它。但是,不要调整系统以适应效率低下的程序。(诚然,有时你需要止血带来防止流血致死,但不要把权宜之计作为永久解决办法解决效率低下的问题。)有很多手段可以解决项目效率低下的问题。即使是现有的商业化应用,与软件供应商合作以使程序高效,而不是效率低下的试图优化系统使其尽可能高效,从长远来看对你的益处更大。
提高程序效率的改进可以为系统中的每个人带来巨大的好处。不难看出最大程度减少滥用是如何帮助改进任务的响应时间的。许多人也不明白的是,提高一个程序的效率会给该系统中与被改进程序没有明显关系的程序带来性能改进方面的负面影响。出现这种情况是因为 负载 对系统硬件的影响
负载
负载是由并发任务执行引起的资源的竞争。这就是为什么软件开发人员所做的性能测试,不能捕捉到生产后期出现的所有性能问题。
负载的一个度量是利用率,即在指定的时间间隔内,资源利用率除以资源容量。随着资源利用率的提高,用户向该资源请求服务的响应时间也会增加。任何一个在大城市的交通高峰时期乘坐过汽车的人,都经历过这种现象。当交通非常拥挤时,你必须在收费站等更长的时间。
使用的软件实际上并不像车那样“变慢”。在公路上以60英里每小时的速度,而在拥挤的交通中只能每小时30英里的速度行驶。无论发生什么情况,计算机软件总是以相同的速度运行(每个时钟周期的指令数是恒定的),但是随着系统上的资源越来越繁忙,响应时间肯定会变差。
当负载增加时,系统变慢有两个原因:排队延迟和一致性延迟。
排队延迟
负载和响应时间之间的数学关系是众所周知的。一种数学模型称为 M/M/m,在满足一些特定要求时,将响应时间与系统负载相关联[11]。M/M/m 的一个假设是,所建模的系统具有“理论上完美的可扩展性”。类似于拥有一个“无摩擦”的物理系统,物理入门课程中的许多问题都基于该假设。
尽管有一些过激的假设,比如 “完美可扩展性”,M/M/m 在性能方面仍有很多东西值得学习。Figure 4 展示了 M/M/m 响应时间和负载之间的关系。
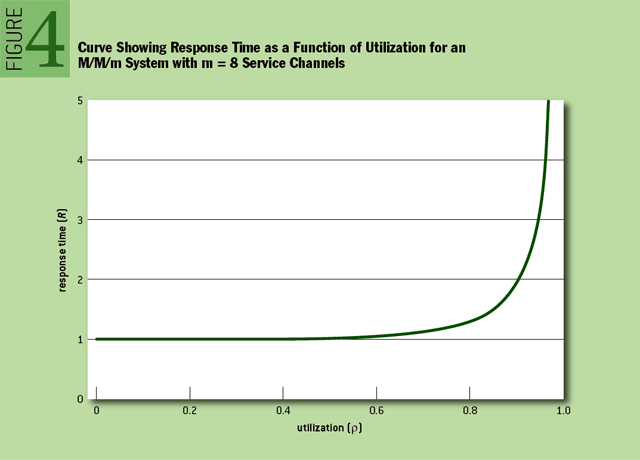
Figure 4,你可以从数学角度看到,在不同负载条件下使用系统时的感受。在低负载时,响应时间与空载时的响应时间基本相同。随着负载的增加,会感觉到响应时间有平缓的略微的变差。这种逐渐的变差并不会造成多大的危害,但是随着负载的不断增加,响应时间开始某种意义上快速的剧烈的变差。在某种程度上来说,响应时间变差变得相当令人不快,并且事实上变成了抛物型的。
在完美可扩展 M/M/m 模型中,响应时间(R)由两部分组成:处理时间(S)和排队延迟(Q),或 R=S+Q。处理时间是任务消耗给定资源的持续时间,以每次任务执行的时间为单位,例如以每次单击的秒数为单位。排队延迟是任务在给定资源处排队,等待消耗该资源的条件满足的时间。排队延迟也以每次任务执行的时间来衡量(例如,每次单击的秒数)。
换言之,当你在 Taco Tico 点午餐时,你收到订单的响应时间(R)是你在柜台前等待有人接受你的订单所花费的排队延迟时间(Q),再加上你在开始与订单管理员交谈后等待订单送达的处理时间(S)。队列延迟是指给定任务的响应时间与空载系统上同一任务的响应时间之差(不要忘记我们完美可扩展性假设)。
拐点
说到性能,你希望从一个系统中得到两点:
- 你可以获得的最佳响应时间:你不想等太久才能完成任务。
- 你可以获得的最佳吞吐量:你希望能够将尽可能多的负载塞进系统,以便尽可能多的人能够同时运行他们的任务。
不幸的是,两个目标是互相矛盾的。优化达到第一个目标需要最大程度地减少系统的负载;优化达到第二个目标需要将负载最大化。两者无法同时兼得。系统的最佳负载是在介于两者之间的某个位置的某种负载水平(即,在某个利用率值)。
负载达到最佳平衡的利用率值称为拐点,该点是吞吐量最大化且对响应时间的负面影响最小的点。(我正在就在这种情况下使用拐点一词是否合适进行持续的辩论。目前,我将继续使用它。有关详细信息,请参阅下面的注解。)从数学角度讲,拐点是响应时间除以利用率的最小值时的利用率值。拐点有一个很好的特性,穿过原点的直线与响应时间曲线的切点,此时的利用率值即拐点。在一个精心制作的 M/M/m 图上,你可以很好地用直尺定位拐点,如 Figure 5 所示。
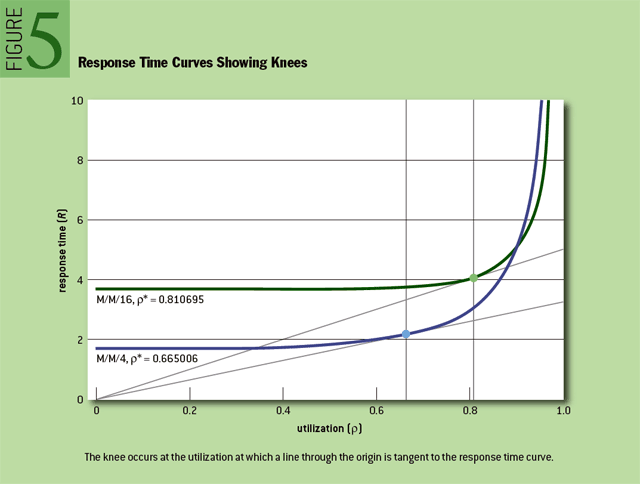
M/M/m 拐点的另一个好特性是,只需要知道一个参数的值就可以计算它。这个参数是并行的、同质的、独立的处理通道数。处理通道是一种资源,需要共享单个队列。例如,收费站中的收费亭或 SMP(对称多处理器)计算机中的 CPU。
术语 M/M/m 中的斜体小写 m 是系统被建模的处理通道数。任意系统的 M/M/m 拐点值很难计算,但我已经在 table 5 中为你做了这项工作,table 5 显示了一些常见处理通道数的拐点值。(此时,你可能想知道 M/M/m 排队模型名称中的其他两个 M 代表什么。它们与传入请求的时间和处理时间的随机性的假设有关。有关信息请参阅 Kendall’s Notation,或参阅 Optimizing Oracle Performance[11] 获得更多有关详细信息。)
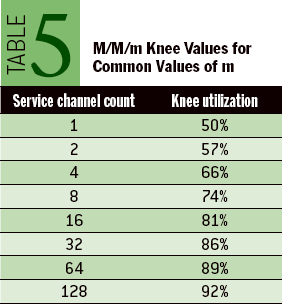
为什么拐点如此重要?对于随机处理请求的系统,允许资源负载持续超过临界值会导致响应时间和吞吐量随负载的微小变化而剧烈波动。因此,在随机请求到达的系统中,管理负载以使其不会超过拐点值是至关重要的。
拐点的相关性
拐点的概念到底是否真的如此重要?正如我告诉过你的,毕竟 M/M/m 模型假设了一个荒谬的乌托邦想法,即你所考虑的系统可以完美地扩展。我知道你在想什么:不可能。
M/M/m 给我们的知识是,即使你的系统能够完美地扩展,一旦你的平均负载超过 table 1 中的拐点值,你仍然会遇到大量的性能问题。你的系统不如 M/M/m 模型中的理论系统好。因此,与 table 1 中的值相比,系统拐点的利用率值将更小。(”值” 和 “拐点”是复数形式,因为你可以用一个模型来建模CPU,另一个模型来建模磁盘,另一个模型来建模I/O控制器,依此类推。)
回顾一下:
- 系统中的每种资源都有一个拐点。
- 每种资源的拐点小于或等于 table 1 中的拐点值。系统扩展性越不完善,拐点值就越小(越差)。
- 在随机请求到达的系统上,如果允许系统中任何资源的利用率持续超过该资源的临界值,那么性能就会出现问题。
- 因此,管理负载非常重要,这样资源利用率就不会超过拐点值。
容量规划
理解拐点容量规划可以降低很多复杂性。是这样的:
- 给定资源的目标容量,是指可以在高峰时期可以轻松地运行任务,而不会使利用率超过拐点。
- 如果保持利用率低于拐点,系统行为大致线性-没有大的抛物线型的意外。
- 但是,如果系统运行的任意资源超出其拐点利用率值,就会出现性能问题(无论你是否意识到)。
- 如果遇到性能问题,那么不需要花费时间在数学模型上;你需要花费时间重新调整负载、消除负载或增加容量来解决这些问题。
这就是容量规划如何融入性能管理过程的。
随机到达
你可能已经注意到我多次使用 随机到达 这个词。它为什么重要?
有些系统有一些你当前不具备的特性:完全确定的作业调度。虽然如今很少见,有些系统配置为成允许服务请求以完全自动化的方式进入系统,比如说,以每秒一个任务的速度。我的意思不是说平均每秒一个任务(例如,一秒钟两个任务,下一个任务零);我是说以均匀的速率每秒一个任务,就像在装配线上机器人把汽车零件送入箱子一样。
如果到达系统的行为完全是确定性的,意味着你确切地知道下一个服务请求何时到来,那么你可以使用超过其拐点利用率的资源利用率,而不必造成性能问题。对于确定性到达的系统,目标是使资源利用率达到100%,不用将太多的工作负载塞进系统,导致请求开始排队。
拐点值在 随机到达 的系统上如此重要的原因是请求趋向于聚集,并导致利用率出现暂时的峰值。这些峰值需要足够的备份容量来消化,如此用户就不必在每次峰值出现时都忍受明显的排队延迟(排队延迟导致响应时间的明显波动)。
对于一个给定的资源,使用率出现临时的峰值超过拐点不会有问题,只要不超过太长时间。多少秒太长了?我认为(但还没有试图证明)至少应该确保峰值持续时间不超过8秒。(如果你听说过“八秒规则”[2],你就会认出这个数字。)答案是肯定的,如果你不能达到基于百分位的响应时间承诺,或对用户的吞吐量承诺,那么你的峰值时间就太长了。
一致性延迟
你的系统不具备理论上完美可扩展性。尽管我从来没有专门研究过你的系统,我敢打赌不管你在想什么计算机应用系统,它都不符合 M/M/m “理论上完美可扩展性” 的假设。一致性延迟是可以用来模拟缺陷的因素[5]。它是一个任务访问共享资源用于通信和协调的持续时间。与响应时间、服务时间和队列延迟一样,一致性延迟是以每次任务执行的时间来度量的,如每次单击的秒数。
我不会描述一个用于预测一致性延迟的数学模型,但好消息是,如果性能剖析你的软件任务执行,你将在它发生时看到它。在 Oracle,以下延时事件就是一致性延迟的示例:
- 入队
- 缓冲区忙等待
- 锁存器释放
你不能用 M/M/m 来建模一致性延迟,因为 M/M/m 假设所有 m 个处理通道都是并行的、同质的和独立的。这意味着该模型假设,在FIFO队列中排队等待足够长的时间后,在之前排队的所有请求都已退出队列得到处理,那么将轮到为你提供服务。然而,一致性延迟并不是这样工作的。
例十。设想一个 HTML 数据表单中,一个标签为 “Update” 的按钮执行一个 SQL update 语句,另一个标签为 “Save” 的按钮执行一个 SQL commit 语句。如此构建的应用几乎可以肯定导致糟糕的性能。实际上,如此设计导致此情况很有可能出现,用户可点击 “Update” 查看他的日历,意识到“哦,我还没吃午餐”,然后去吃两个小时的午餐,然后在当天下午晚些时候才点击 “Save”。
对于系统中希望更新同一行的其他任务的影响将是毁灭性的。每个任务都必须等待行上的锁(或者,在某些系统上更糟的是:行所在的页锁),直到持有锁的用户决定继续,并单击 “Save”,或者直到数据库管理员终止用户会话,对于以为自己已更新一行的人,当然会有不好的副作用。
在这种情况下,任务等待释放锁的时间与系统的繁忙程度无关。它取决于存在于系统之外的各种资源利用率的随机因素。这就是为什么不能用 M/M/m 建模,也是为什么永远不能假设在一个单元测试类型的环境中,执行的性能测试就足以决定向生产系统中增加新代码是否可行。
性能测试
本文所有关于排队延迟和一致性延迟的讨论都导致了一个非常困难的问题:如何能够对一个新的应用进行足够的测试,以确信不会因性能问题而破坏生产实施?
你可以建模。你可以测试[1]。但是,你做的任何事都不会是完美的。创建模型和测试以在实际遇到生产问题之前预见到所有的生产问题是非常困难的。
有些人使用显见无用的观察以证明完全不进行测试是合理的。别陷在那种心态里。以下几点是肯定的:
- 如果在生产前就想办法解决问题,会发现比根本不去尝试多得多的问题。
- 在预生产测试中,你永远无法发现所有问题。这就是为什么你需要一个可靠和有效的方法来解决在你的预生产测试过程中泄露的问题。
适当的测试数量是介于“无测试”和“完全生产仿真”之间的某个点。对飞机制造商来说,正确的测试量可能比销售棒球帽公司的测试量要多。但不要完全跳过性能测试。至少,性能测试计划会使你成为一个更称职的诊断专家(和更清晰的思考者),当时间到了,你将改进不可避免地出现在生产活动中的性能问题。
测量
人们能感知到吞吐量和响应时间。吞吐量通常很容易测量,响应时间则要困难得多。(请记住,吞吐量和响应时间不是倒数关系。)用秒表来计时最终用户的操作可能并不困难,可能很难得到您真正需要的东西,即,深入细节了解为什么给定的响应时间如此之大的细节。
不幸的是,人们倾向于测量容易测量的东西,而不一定是他们应该测量的东西。这是个问题。不是你所需要的,但很容易获得,并且似乎与你需要数据相关的测量称为替代测量。包括子程序调用计数的示例和子程序调用执行持续时间的示例。
我很惭愧,自己的母语没有比这样说更好的表达了,但是这里有一个通俗易懂的现代方式来表达我对替代测量的看法:替代测量很糟糕。
不幸的是,在这里,糟糕并不意味着永远不起效。如果替代测量永远不能奏效,实际上会更好。那就没人会用了。问题是替代测量有时起作用。这激发了人们的信心,即他们所使用的措施应该一直有效,然而并非如此。替代测量有两个大问题。
- 当系统不正常时,它们告诉你系统正常。这就是统计学家所说的I型错误,假阳性。
- 它们告诉你,有些事情是有问题的,而事实并非如此。这是第二类错误,假阴性。
我看到每一种错误都浪费了人们很多年的时间。当需要评估一个真实系统的细节时,您的成功取决于系统允许您获得的测量结果的好坏。我有幸在 Oracle 市场部门工作,在那里,我们这个领域的核心软件供应商积极参与,使以正确的方式测量系统成为可能。让应用软件开发人员使用 Oracle 提供的工具是另一回事,但至少产品中有这些功能。
性能是一种特性
性能是一种软件应用的特性,就像意识到一个字符串 “Case 1234” 可以自动超链接到 跟踪系统中 case 1234 一样方便。(FogBugz,我喜欢使用的软件)性能,和其他特性一样,并不是一蹴而就的,它必须经过设计和构建。性能出色,需要你思考、研究、编写额外的代码、测试、维护它。
然而,与许多其他特性一样,当你还在编写、研究、设计和创建应用时,你无法确切地知道性能怎样。对于许多应用(可以说,对于绝大多数应用),性能是完全未知的,直到软件开发生命周期的生产阶段。剩下的是:由于你不知道你的应用在生产中的性能如何,所以你需要编写方便在生产环境中轻松地改进性能问题的应用。
正如 David Garvin 告诉我们的,管理容易测量的东西要容易得多[3]。编写一个易于在生产中改进的应用,首先要编写一个在生产中易于测量的应用。
通常,当我提到生产性能测量的概念时,人们会陷入一种担心性能仪器的测量入侵效应的状态。他们立即进入数据收集妥协的模式,只留下替代测量。有额外的代码路径来测量时间的软件,不是会比没有额外代码路径的软件慢吗?
我喜欢曾经听到过汤姆·凯特对这个问题的回答[7]。他估计 Oracle 广泛的性能测试工具的测量入侵影响小于等于 -10%(其中小于等于意味着或更好,如 -20%,-30%,等等)。他接着向一位气恼的提问者解释说, Oracle 公司凭借从其性能检测代码中获得的知识,产品现在至少快了10%,比测量设施引入的 “开销” 都要多。
我认为供应商往往会花太多的时间去考虑如何使他们的测量代码路径高效,而不首先弄清楚如何使其有效。它完全符合 Knuth 在1974年写的 “过早优化是万恶之源” 的观点[6]。将性能测量集成到产品中的软件设计师更有可能创建快速的应用,更重要的是,随着时间的推移,应用将变得更快。
Q:关于拐点的公开辩论
在本文中,我将介绍拐点的性能曲线、相关性以及应用。然而,是否值得尝试定义拐点的概念,这是一个至少可以追溯到20年前的争论话题。
有一个重要的历史看法,我所描述的拐点实际上并没有真正意义。1988年,斯蒂芬·萨姆森认为,至少对于 M/M/1 排队系统,性能曲线中不会出现“拐点”。“选择一个指导性数字并不容易,但经验法则的制定者是正确的。在大多数情况下,没有一个膝盖,无论我们多么希望找到一个。”,萨姆森写道[3a]。
正如我在1999年写的[2a],整个问题让我想起了青蛙和沸水的寓言。故事说,如果你把一只青蛙扔进一只开水的锅里,它就会逃跑。但是如果你把一只青蛙放进一盆凉水里慢慢加热,青蛙就会耐心地坐在原地直到被煮死。
利用率,就像沸水一样,显然存在一个“死亡区”,在这个范围内,你无法支撑随机到达式系统的运行。但死亡区的边界在哪里?如果你试图实现一种过程化的方法来管理利用率,你需要知道。
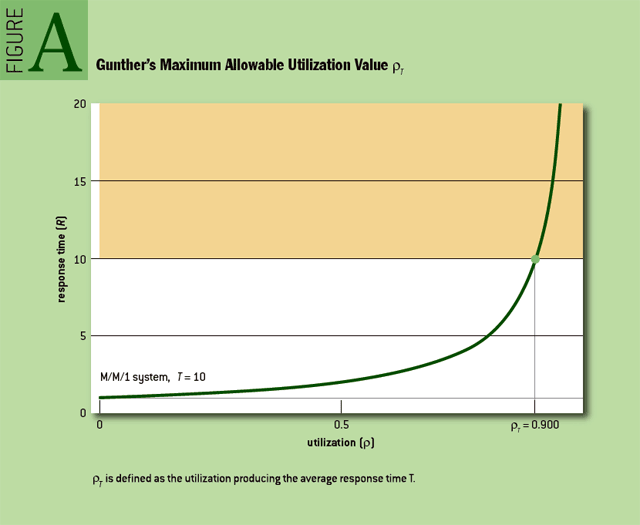
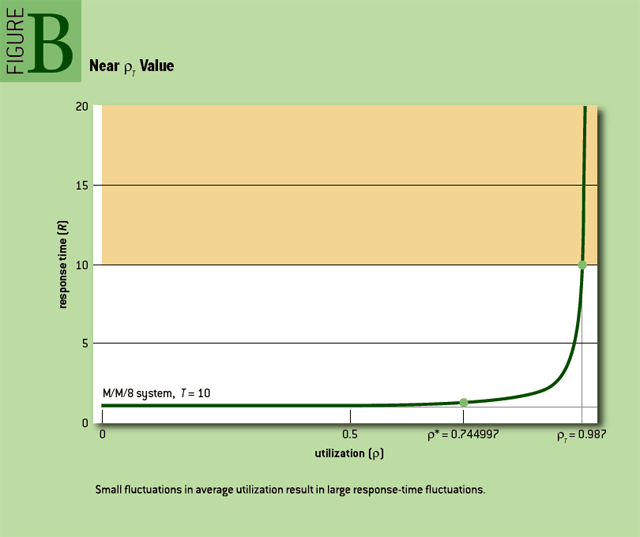
我的朋友尼尔·冈瑟私下里和我争论过,首先,在没有功能中断的情况下,“拐点”这个词在这里完全用错了。第二,他断言对于 M/M/1 系统,边界值为0.5是浪费性的低,应该能够以比这更高的利用率成功运行这样一个系统。最后,他认为,任何此类特殊利用率值都应明确定义为平均响应时间超过平均响应时间容忍度的利用率值(Figure A)。因此,冈瑟认为,任何有用的不可超过的利用率值,只能从人类偏好的调查中得出,而不是从数学中得出。(有关他的论点,请参阅 此处。)
我在这个论点中看到的问题如 Figure B 所示。假设你对平均响应时间的容忍度是T,如此产生了ρT的最大容许利用率值。请注意,即使在ρT附近的平均利用率出现微小波动,也会导致平均响应时间的巨大波动。
我相信你的客户感受到的是差异,而不是平均值。也许他们说他们会接受T以内的平均响应时间,但当一分钟内平均利用率变化1%会导致平均响应时间增加10倍时,人类不会容忍系统的性能问题。
我确实理解这样一种观点,即我在本文中列出的拐点值低于许多人认为可以安全地超过的利用率值,特别是对于低阶系统,如 M/M/1。但是,重要的是要避免以平均利用率值使用资源,因为利用率的小波动会导致响应时间的过大波动。
话虽如此,我还没有一个很好的定义来定义过大波动。也许,就像响应时间容忍度一样,不同的人对波动的容忍度也不同。但也许有一个波动容忍系数,适用于所有用户的合理普遍性。例如,Apdex应用性能指数标准,假定用户变得“沮丧”的响应时间 F,通常是其态度从“满意”转变为勉强“容忍”的响应时间 T 的四倍[1a]。
拐点,不管你如何定义它,或者最终如何称呼它,它是我在本文正文前面描述的容量规划过程的一个重要参数,我相信它是计算机系统工作负载管理的日常过程的一个重要参数。
我会继续研究。
References
1a. Apdex; http://www.apdex.org.
2a. Millsap, C. 1999. Performance management: myths and facts; http://method-r.com.
3a. Samson, S. 1988. MVS performance legends. In Computer Measurement Group Conference Proceedings: 148-159.
References
- CMG (Computer Measurement Group, a network of professionals who study these problems very, very seriously); http://www.cmg.org.
- Eight-second rule; http://en.wikipedia.org/wiki/Network_performance#8-second_rule.
- Garvin, D. 1993. Building a learning organization. Harvard Business Review (July).
- General Electric Company. What is Six Sigma? The roadmap to customer impact. http://www.ge.com/sixsigma/SixSigma.pdf.
- Gunther, N. 1993. Universal Law of Computational Scalability; http://en.wikipedia.org/wiki/Neil_J.\_Gunther#Universal_Law_of_Computational_Scalability.
- Knuth, D. 1974. Structured programming with Go To statements. ACM Computing Surveys 6(4): 268.
- Kyte, T. 2009. A couple of links and an advert…; http://tkyte.blogspot.com/2009/02/couple-of-links-and-advert.html.
- Millsap, C. 2009. My whole system is slow. Now what? http://carymillsap.blogspot.com/2009/12/my-whole-system-is-slow-now-what.html.
- Millsap, C. 2009. On the importance of diagnosing before resolving. http://carymillsap.blogspot.com/2009/09/on-importance-of-diagnosing-before.html.
- Millsap, C. 2009. Performance optimization with Global Entry. Or not? http://carymillsap.blogspot.com/2009/11/performance-optimization-with-global.html.
- Millsap, C., Holt, J. 2003. Optimizing Oracle Performance. Sebastopol, CA: O’Reilly.
- Oak Table Network; http://www.oaktable.net.
原文链接:Thinking Clearly about Performance
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/10-27-2020/thinking-clearly-about-performance-cn-part-two.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!