

积木可以帮助儿童培养创造力和空间想象力,也可以被用来帮助人们理解系统稳定性的概念。
在系统稳定性中,积木可以被视为一个模型,代表系统的组成部分。每个组成部分都会相互影响,从而影响整个系统的稳定性。就像在积木塔中,每个积木都要与其它积木相互连接,以确保整个积木塔的稳定性。如果其中一个积木被移动或摇晃,可能会导致整个积木塔崩塌。
脆弱性来源
一个系统的脆弱性取决于其在面对外部压力或内部故障时能否维持其功能或性能,影响系统脆弱的因素包括:
- 单点故障:如果一个系统的某个关键部件出现故障,整个系统可能会受到影响。如果系统没有设计良好的冗余机制或备用部件,就可能会导致系统崩溃。
- 缺乏弹性:系统的弹性是指它在受到压力或负载变化时能否适应和调整。如果系统缺乏弹性,就可能会因为某个部分的失效或超负荷而崩溃。
当资源使用率都处在低位,或者请求量保持在处理能力之下,流量再大无非面多加水,水多加面;当机器全新或在保,硬件故障频率保持在低位;环境宽松,会有一种错觉:怎么做都是对的。当需要缩容提升资源使用率,请求延迟毛刺让你无从下手;当每季度数台机器硬件故障,让你疯狂救火;就会倒逼产品在可用性方面下硬功夫。
接下来的部分以 Redis 架构来说明,技术决策是如何影响系统可用性的
请求扇出
在 Codis 架构下,所有的数据按照 Key 对数据进行分片,每个分片提供一部分数据的访问能力。每个 Cmd 无论 Key 数量多少,都只能请求一个分片。整体架构如下:
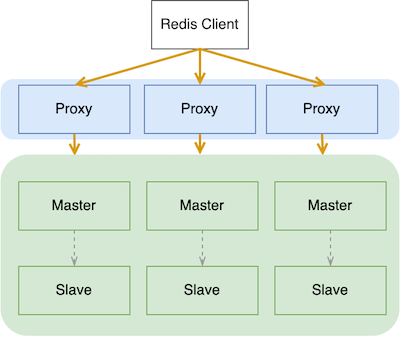
实际情况是,用户的一次请求所需要的数据,可能会存储在多个分片内,譬如:搜索结果页。
为了满足类似需要,国内云厂商的 Redis 提供了跨分片请求的功能,以降低复杂度、吸引用户。当一个 MGET 的多 Key 请求发送到 Proxy 之后,由 Proxy 实现多个分片的命令拆分、聚合运算。整体架构如下:
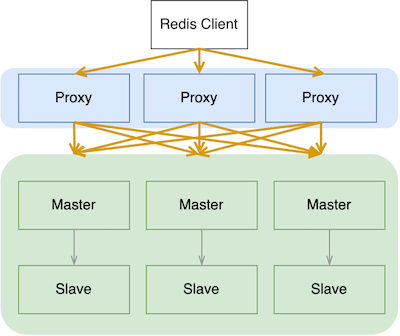
单点故障
客户收获了自由,可以放飞自我。不用考虑请求跨多少分片,一次性 MGET 数百 Key 稀松平常;云厂商吸引了用户,财报靓丽。
突然有一天,有一个分片的机器降频了,处理能力大幅下降,请求量超过了分片处理能力;紧接着请求在 Proxy 大量堆积,一个分片开始超时报错;再接着业务发起大量重试,其他分片也因为重试导致带来的额外压力而积压。最终整个集群雪崩,业务整体崩溃。
聪明的朋友可能会有疑问:一个分片失败,只重试失败的分片不就可以了,为何还要重试其他已经成功的分片?
你抓住了重点,Proxy 能否支持部分失败呢?
答案是:可以。
Redis 刚开始是没有集群模式的,即使是 Redis Cluster 也是不支持跨 Slot 请求的,因此每次请求都只有两种结果:成功、失败。
完美支持“部分失败”需要依赖 RESP 协议、SDK、业务代码的支持,如此一来整体使用复杂度与自行分片请求已所差无几。
RESP:
RESP Arrays are sent using the following format:
- A `*` character as the first byte, followed by the number of elements in the array as a decimal number, followed by CRLF.
- An additional RESP type for every element of the Array.SDK:
// https://github.com/redis/go-redis
func (r *Reader) readSlice(line []byte) ([]interface{}, error) {
n, err := replyLen(line)
if err != nil {
return nil, err
}
val := make([]interface{}, n)
for i := 0; i < len(val); i++ {
v, err := r.ReadReply()
if err != nil {
if err == Nil {
val[i] = nil
continue
}
// 正确处理
if err, ok := err.(RedisError); ok {
val[i] = err
continue
}
return nil, err
}
val[i] = v
}
return val, nil
}业务代码:
// 定义要查询的key数组
keys := []string{"key1", "key2", "key3"}
// 使用MGET命令获取多个key对应的value值
values, err := client.MGet(keys...).Result()
if err != nil {
return fmt.Errorf("redis request failed:%s", v)
}
// 输出结果
for _, val := range values {
strVal, ok := v.(string) // 结果类型判断,避免类型强转导致 Panic
if !ok {
return fmt.Errorf("invalid redis response type:%s", v)
}
fmt.Printf("key:%s, value:%v\n", keys[i], strVal)
}
// 手动重试失败的 Key ...扇出数量
在扇出的情况下,不同类型的 RPC 请求对于服务的影响巨大。Unary RPC 需要等待所有扇出请求全部返回,重组完毕才能一次性返回给主调方。
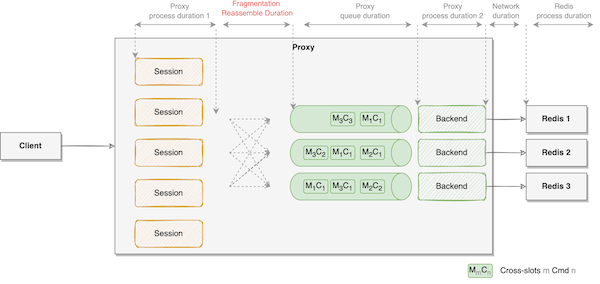
当 Proxy 接收的请求数没有变化的前提下,不同大小的 Key 数量,最终会得到不一样的扇出数。切分和重组并非是无代价的,都需要额外的计算资源,导致 Proxy 的 CPU 使用率尖峰;Proxy 请求的整体响应耗时就取决于耗时最长的扇出请求,而该扇出请求的耗时又受 Key 数量的影响。以 MGET 1000 个 Key 为例,可能会切分成:
1)1000 个 Slots,每 Cmd 1 个 Key,并发请求 1000 个 Slots 的Redis 节点
2)1 个 Slot,该 Cmd 1000 个 Key
3)10 个 Slots,每 Cmd 100 个 Key,并发请求 1 个 Redis 节点,Redis 顺序执行
首先,情况 1)的概率最大:
Redis Cluster 的固定槽位数量 “16384”,1000 有着数量级上的差距,因此在不使用 Hashtag 的情况下基本是分布在不同的 Slots。 扇出暴增,将导致 Proxy 网络IO和内存的使用量急剧增加。
其次,情况 2)请求的 Key 最终落到同一 Slot。在正常的业务情况下,每次请求的 Key 数量一般会符合正态分布,请求的数量一般分布在一定的区间。
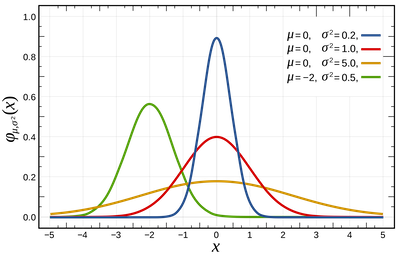
假设请求 Key 数量的中位数为 75 个 Key,Key 数量可能会有如下分布:
- 10% 的请求为 1~50 个 Key;
- 80% 的请求为 50~100 个 Key;
- 9% 的请求为 100~200 个 Key;
- 1% 的请求为 200~1000 个 Key;
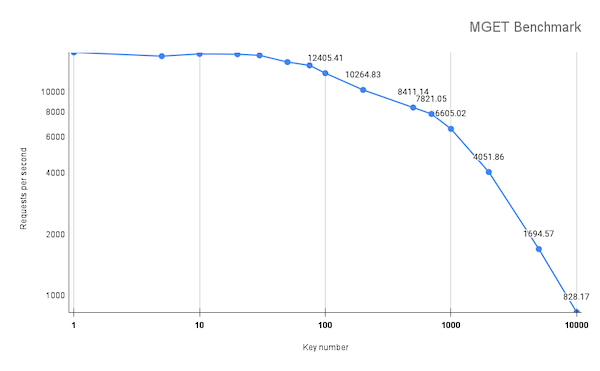
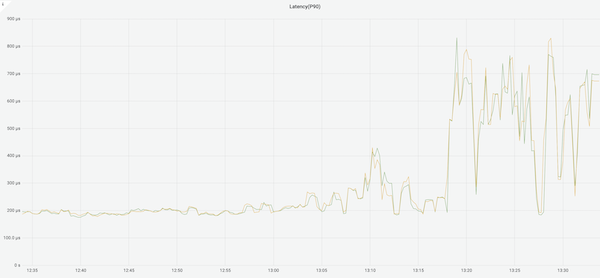
Redis 服务器在处理 1% 的请求时就会出现阻塞,从而影响其他 99% 的请求延迟。整体效果如下:
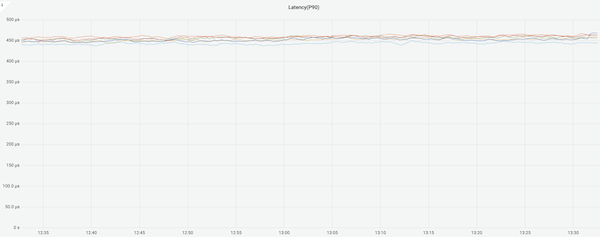
根据具体情况,选择合适的批量操作方式(比如分批次获取)以及使用 Redis 的 pipelining 技术等,就可以避免阻塞得到更稳定的服务:
总结
针对 Redis 的场景,Redis 官方博客提供了一些建议,包括:
- 认真考虑 Key 空间。Key 是否有共同的特征,可以以智能的方式(按用户、按操作、按时间等)切分负载。使用 hashtag 将 Key 巧妙地分配到哈希槽。
- 评估 MULTI/EXEC 事务。看看您是否真的需要事务,或者管道是否可以。 不要忘记考虑多键命令以及它们是否可以被多个命令替换。
针对所有场景,一次用户请求响应的过程,其实就是数据读取、计算、展示的过程。请求精细划分,可以把计算从在线转移到离线;从读取转移到写入,一次计算,次次读取。简单来说,怎么存就决定了怎么取。
读取的数据确定、展示的样式确定,计算的复杂度不会消失不见。如果只是将计算从业务系统,转移到基础架构(从北向服务转移到南向服务);从无状态服务转移到有状态服务。实现方案简单了,系统也脆弱了。
万事皆有缘由,世事岂无因果。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/03-12-2023/why-is-the-system-so-fragile.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!