
译者序
本文发表于 2016 年,作者为 Borg、Omega 和 Kubernetes 的主要开发: Brendan Burns 和 David Oppenheimer, 其他相关论文包括:
- 2015 《Large-scale cluster management at Google with Borg》
- 2016 《Borg, Omega, and Kubernetes:Lessons learned from three container management systems over a decade》
文章总结了云原生下的多种设计模式,能够对如何设计分布式系统有所启发。从本论文中你也可以看到容器管理系统 ( Kubernetes )、Service Mesh (Istio)、 监控系统 ( Prometheus ) 等诸多明星系统的影子,进而推测未来云原生领域的发展方向。
1 导言
在 1980 年代末和 1990 年代初,面向对象编程彻底改变了软件开发,普及了将应用构建为模块化组件集合的方法。 今天,我们在分布式系统开发中看到了类似的革命,基于容器化软件组件构建的微服务架构越来越受欢迎。 因为容器之间的隔离优势,容器 [15] [22] [1] [2] 特别适合作为分布式系统中的基本“对象”。 随着这种架构风格的成熟,我们看到了设计模式的出现,就跟面向对象程序所做的一个道理——以对象(或容器)的方式思考抽象掉代码的低级细节,最终揭示各种应用和算法共有的高级模式。
本文描述了我们在基于容器的分布式系统观察到的三种设计模式:容器管理的单容器模式、紧密协作容器的单节点模式和分布式算法的多节点模式。 与之前的面向对象模式一样,分布式计算的这些模式实现了最佳实践,简化了开发,让使用它们的系统更可靠。
2 分布式系统设计模式
在使用面向对象编程多年之后,设计模式出现并被记录了下来[3]。 这些模式编码和规范化了解决特别常见编程问题的一般方法。 这种编码进一步提高了编程的总体水平,因为它使经验不足的程序员更容易产出高质量的代码;同时,它促进了可重用库的发展,使代码更可靠,开发速度更快。
当今分布式系统工程的最新技术看起来更像是 1980 年代早期的编程时期,而不是面向对象开发的时期。 然而,从 MapReduce 模式 [4] 将 “大数据” 编程的力量带到广阔的领域和开发者群体的成功中可以清楚地看出,建立正确的模式集可以显着提高分布式系统编程的质量、速度和可达性。 但即使 MapReduce 的成功很大程度上也仅限于单一的编程语言,因为 Apache Hadoop [5] 生态系统主要是用 Java 编写的。 为分布式系统设计开发一套真正完备的模式需要一个非常通用的、语言中立的工具来表示系统的原子元素。
值得庆幸的是,过去两年 Linux 容器技术的采用率急剧上升。容器和容器镜像正是分布式系统模式开发所需的抽象。到目前为止,容器和容器图像仅通过作为一种更好、更可靠的方法从开发到生产交付软件,就获得了广泛的应用。通过紧密的封装,依赖自治,并提供原子部署标记(“成功”/“失败”),它们极大地提升了以前在数据中心或云中部署软件的最先进技术的水平。但容器有可能不止于此——我们相信它们注定会类似于面向对象的软件系统中的对象,将使分布式系统设计模式的发展成为可能。在下面的部分中,我们解释了为什么我们认为必然如此,并描述了我们看到的一些模式,这些模式将在未来几年中规范和指导分布式系统的工程。
3 单容器管理模式
与对象边界 ( boundary) 非常相似, 容器为定义接口提供了一个自然的边界 ( boundary) 。容器不仅可以通过此接口暴露应用特定的功能,还可以为管理系统暴露钩子 (hooks)。
传统的容器管理接口非常有限。容器有效地暴露三个动词:run() pause() 和 stop()。虽然此接口很有用,但更丰富的接口可以为系统开发和运维人员提供更多能力。鉴于几乎所有现代编程语言都普遍支持 HTTP Web 服务器,并且对 JSON 等数据格式的广泛支持,因此很容易定义一个基于 HTTP的管理 API,除了其主要功能之外,还可以通过让容器在特定端点 (endpoints) 托管 Web 服务器来“实现”其他功能。
在北向方面,容器可以公开一组丰富的应用信息,包括应用特定的监控指标(QPS、应用健康状况等)、开发者感兴趣的分析 (profiling) 信息(线程、堆栈、锁争用、网络消息统计信息) 等)、组件配置信息和组件日志。 作为此的实际例子,Kubernetes [6]、Aurora [7]、Marathon [8] 和其他容器管理系统允许用户通过特定的 HTTP 端点 ( endpoints )(例如 “/health”)定义健康检查。 对我们前面所描述的之外其他元素,北向 API 的标准化支持更为罕见。
在南向方面,容器接口提供了一个自然之选来定义生命周期,这使得编写受管理系统控制的软件组件变得更加容易。例如,集群管理系统通常会为任务分配“优先级”,即使集群超额订阅,高优先级任务也能保证运行。这种保证是通过驱逐已运行中的低优先级任务来实现的,低优先级任务将不得不等待资源可用再执行。驱逐可以通过简单地杀死优先级较低的任务来实现,但这会给开发人员带来不必要的负担,让他们应对代码中任意死亡的情况。相反,如果在应用和管理系统之间定义了一个规范的生命周期,遵从定义的契约以后,应用组件将变得更易于管理;同时,开发人员依赖契约以后,系统的开发变得更容易。例如,Kubernetes 使用 Docker 的“优雅删除”功能,通过 SIGTERM 信号警告容器它将被终止,然后在应用定义的时间窗口之后再发送 SIGKILL 信号。这允许应用完成运行中的操作、将状态刷新到磁盘等再干净地终止。可以想象扩展该机制以提供对状态序列化和恢复的支持,从而使有状态分布式系统的状态管理变得更加容易。
考虑一个更复杂生命周期的例子,Android Activity 模型 [9],它支持一系列回调(例如 onCreate()、onStart()、onStop() 等)和一个规范定义的系统如何触发回调的状态机。如果没有这个规范的生命周期,很难开发健壮、可靠的 Android 应用。 在基于容器的系统的上下文中,泛化为应用定义的在创建容器时、启动时、终止前等调用的钩子 (hooks)。另一个容器可能支持的南向 API 的例子是“复制 (replicate) 自己”(以横向扩容服务)。
4 单主机多容器应用模式
除了单个容器的接口之外,我们还看到了跨容器设计模式的出现。 我们先前确定了几种这样的模式 [10]。单节点模式由共同调度到单个主机上的共生容器组成。 容器管理系统支持将多个容器作为一个原子单元共同调度,抽象 Kubernetes 称为 “Pods”,Nomad [11] 称为“任务组”,这是启用我们在本节中描述的模式所必需的特性。
4.1 边车 (Sidecar) 模式
多容器部署的第一种也是最常见的模式是边车模式。 边车容器扩展并增强了主容器。 例如,主容器可能是一个 Web 服务器,它可能与一个“logsaver” 边车容器配对,后者从本地磁盘收集 Web 服务器的日志并将它们流式传输到集群存储系统。 图 1 是边车模式的示例。 另一个常见例子是 Web 服务器,它从本地磁盘内容提供服务,该内容由边车容器填充,该容器定期同步来自 git 存储库、内容管理系统或其他数据源的内容。 这两个例子在谷歌都很常见。 边车模式之所以是可能的,是因为同一台机器上的容器可以共享本地磁盘卷。
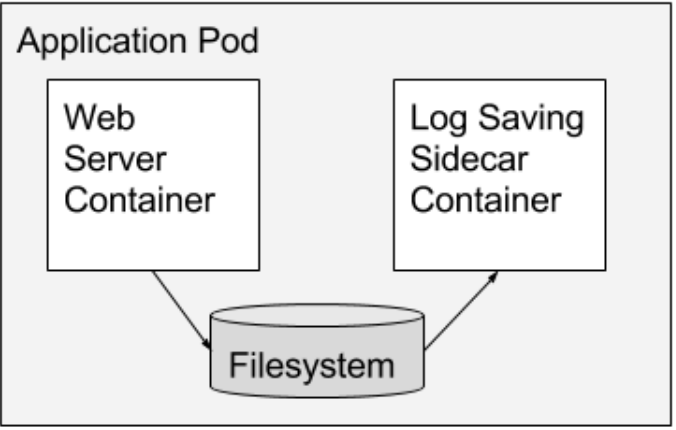
虽然总是可以将边车容器的功能构建到主容器中,但使用单独的容器有几个好处。
- 首先,容器是资源核算和分配的单位,例如,可以配置 Web 服务器容器的 cgroup [15],以便它为查询提供持续的低延迟响应,而 logsaver 容器配置为在Web 服务器不忙时利用空闲的 CPU 周期。
- 其次,容器是打包的单位,将服务和日志保存分离到不同的容器中,可以很容易地在两个独立的编程团队之间划分他们的开发责任,并允许他们独立测试,也可以一起测试。
- 第三,容器是重用的单元,因此边车容器可以与许多不同的“主要”容器配对(例如,log saver 容器可以与任何产生日志的组件一起使用)。
- 第四,容器提供了一个故障控制边界,使得整个系统可以优雅地降级(例如,即使 log saver 程序发生故障,Web 服务器也可以继续服务)。
- 最后,容器是部署单元,它允许对每个功能进行升级,并在必要时独立回滚。 (尽管应该注意的是,最后一个好处也有一个缺点——整个系统的测试矩阵必须考虑生产中可能出现的所有容器版本组合,这可能很大,因为容器集通常不能以原子方式升级。当然,虽然单体应用没有这个问题,但组件化系统在某些方面更容易测试,因为它们是由可以独立测试的较小单元构建的。)
请注意,这五个好处适用于所有我们在本文其余部分描述的容器模式。
4.2 特使 ( ambassador ) 模式
我们观察到的下一个模式是特使模式。 特使容器代理与主容器之间的通信。例如,开发人员可能会将使用 memcache 协议的应用与 twemproxy 特使配对。该应用认为它只是与本地主机上的单个内存缓存进行通信,但实际上 twemproxy 正在将请求分片到其他位置的集群中分布式安装的多个内存缓存节点。这种容器模式在三个方面简化了程序员的生活:
- 他们只需要以应用连接到本地主机上的单个服务器的方式来思考和编程
- 他们可以通过在本地机器上运行一个真正的内存缓存实例来独立测试应用,而不是特使。
- 他们可以将 twemproxy 特使与其他应用一起重用,这些应用甚至可以用不同的语言进行编码。
特使之所以是可能的,因为同一台机器上的容器共享相同的本地主机网络接口。图 2 展示了这种模式的例子。
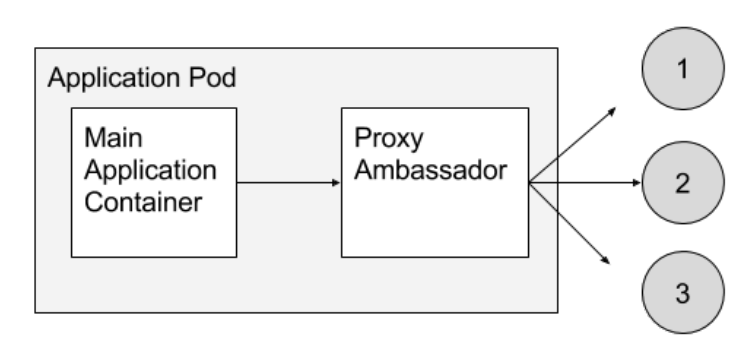
4.3 适配器模式
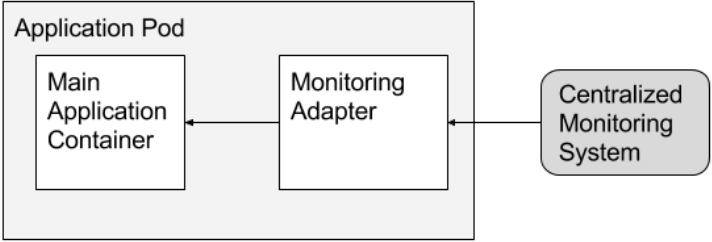
我们观察到的最后一个单节点模式是适配器模式。与向应用呈现简化的外部世界视图的特使模式相比,适配器向外部世界呈现简化、统一的应用视图。它们通过标准化跨多个容器的输出和接口来做到这一点。适配器模式的一个实际例子是,确保系统中所有容器具有相同监控接口的适配器。当今的应用使用多种方法导出其指标(例如 JMX、statsd 等)。但是,如果所有应用都呈现一致的监控接口,那么单个监控工具就更容易从一组异构应用中收集、聚合和呈现指标。在谷歌内部,我们通过编码约定实现了这一点,但这只有在您从头开始构建软件时才有可能。适配器模式使遗留和开源应用的异构世界,无需修改原始应用,就能够呈现统一的接口。主容器可以通过 localhost 或共享本地卷与适配器通信。如图 3 所示。请注意,虽然一些现有的监控解决方案能够与多种类型的后端进行通信,但它们在监控系统自身使用应用特定的代码,关注点分离 ( Separation of Concerns,SoC ) 是模糊的。
5 多节点应用模式
超越单台机器上的协作容器,模块化容器更容易构建协调一致的多节点、分布式应用。 接下来我们将描述其中的三种分布式系统模式。 与上一节中的模式一样,这些模式也需要系统支持 Pod 抽象。
5.1 领导者 ( Leader ) 选举模式
分布式系统中最常见的问题之一是领导者选举(例如 [20])。虽然复制通常用于在一个组件的多个相同实例之间共享负载,但复制的另一个更复杂的用途是应用需要将一个副本从一组副本中区分为“领导者”。如果领导者失败,其他副本可以快速取代领导者。一个系统甚至可以并行运行多个领导者选举,例如:确定多个分片中每个分片的领导者。许多库可以执行领导者选举。它们通常很难正确理解和使用,此外,它们受到特定的实现编程语言的限制。将领导选举库链接到应用的替代方案是使用领导者选举容器。每个领导者选举容器都与需要领导者选举的应用实例共同调度,一组领导者选举容器,可以在它们之间执行选举,并且它们可以通过 localhost 向每个需要领导者选举的应用容器提供简化的 HTTP API(例如 becomeLeader、renewLeadership 等)。这些领导者选举容器可以由该复杂领域的专家构建一次,然后应用开发人员可以重复使用随后的简化接口,而不管他们选择什么实现语言。这代表了软件工程中最好的抽象和封装。
5.2 工作队列模式
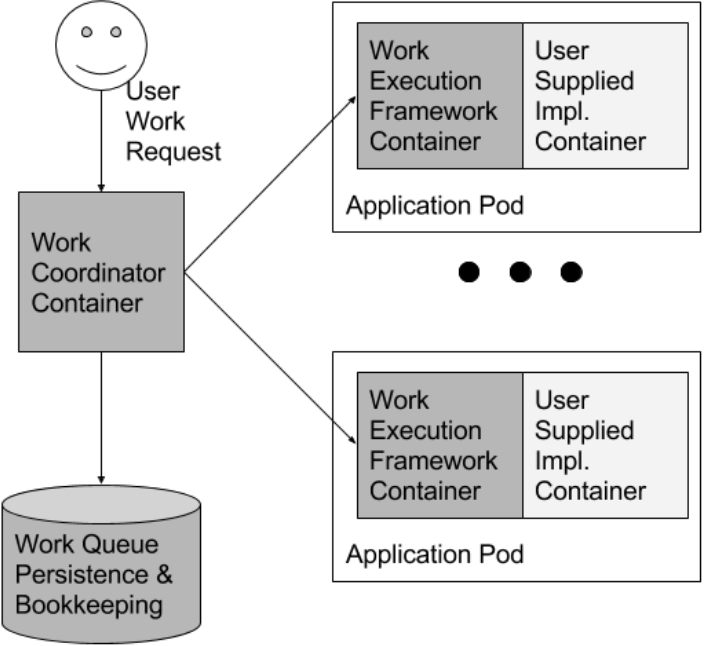
尽管工作队列(如领导者选举一样)是一个经过充分研究的主题,许多框架都实现了它们,但它们也是可以从面向容器的体系结构中受益的分布式系统模式的例子。在以前的系统中,框架将程序限制在单一语言环境中(例如 Celery for Python [13]。译注:异步任务队列),或者工作和二进制文件的分发交由实现者处理(例如 Condor [21]。译注:作业调度系统)。容器实现 run() 和 mount() 接口的可能性,使得实现通用工作队列框架变得相当简单,该框架可以利用打包了任意处理代码的容器和任意数据,构建一个完整的工作队列系统。开发人员只需构建一个容器,该容器可以在文件系统上接收输入数据文件,并将其转换为输出文件;这个容器将成为工作队列的一个阶段。开发完整工作队列所涉及的所有其他工作都可以由通用工作队列框架处理,无论何时需要类似的系统都可以重用该框架。用户代码集成到此共享工作队列框架中的方式如图 4 所示。
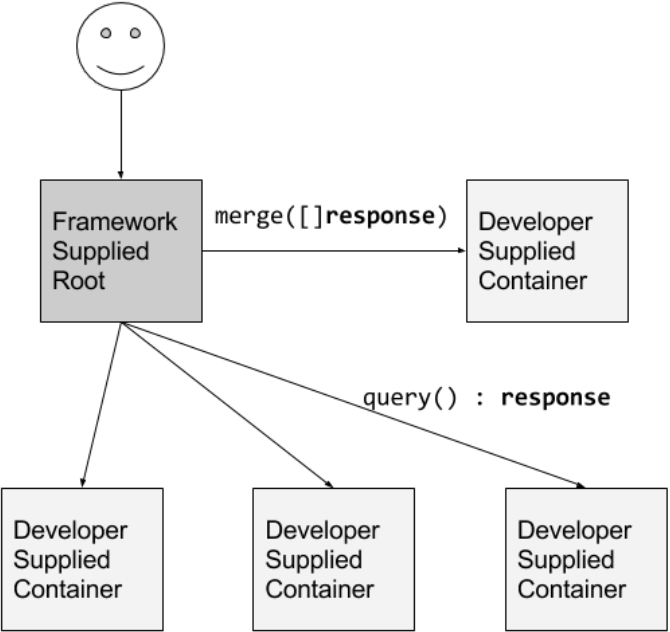
5.3 分散/汇聚模式
我们着重突出的最后一个分布式系统模式是分散/汇聚。 在这样的系统中,外部客户端向 “根” 或 “父” 节点发送初始请求。 此根节点将请求分散到大量服务器以并行执行计算。 每个分片返回部分数据,根节点将这些数据汇聚到原始请求的单个响应中。 这种模式在搜索引擎中很常见。 开发这样一个分布式系统涉及大量样板代码:分发请求、收集响应、与客户端交互等。大部分代码都是非常通用的,同样,就像在面向对象编程中一样,可以通过这样一种方式重构,即可以提供单个实现,只要它们实现特定的接口,就可以与任意容器一起使用。 特别地,为了实现分散/汇聚系统,用户需要提供两个容器。
- 一是实现叶子节点计算的容器; 该容器执行部分计算并返回相应的结果。
- 第二个容器是合并容器; 此容器获取所有叶容器的聚合输出,并将它们组装为单个响应。
通过提供实现这些相对简单的接口的容器,很容易看出用户如何实现任意深度的散布/汇聚系统(如果需要,除了根之外,还包括父级)。这样的系统如图 5 所示。
6 相关工作
面向服务的架构 (SOA) [16] 早于基于容器的分布式系统,并与其许多特征相通。 例如,两者都强调可重用的组件,这些组件具有通过网络进行通信的定义明确的接口。 另一方面,SOA 系统中的组件往往比我们描述的多容器模式粒度更大,耦合更松散。 此外,SOA 中的组件通常实现业务活动,而我们在这里关注的组件更类似于通用库,可以更轻松地构建分布式系统。 最近出现了术语 “微服务” 来描述我们在本文中讨论的组件类型。
网络组件的标准化管理接口的概念至少可以追溯到 SNMP [19]。 SNMP 主要侧重于管理硬件组件,尚未出现管理基于微服务/容器的系统的标准。 这并没有阻止众多容器管理系统的发展,包括 Aurora [7]、ECS [17]、Docker Swarm [18]、Kubernetes [6]、Marathon [8] 和 Nomad [11]。
我们在第 5 节中提到的所有分布式算法都有悠久的历史。 人们可以在 Github 中找到许多领导者选举实现,尽管它们似乎是作为库而不是独立组件构建的。 有许多流行的工作队列实现,包括 Celery [13] 和 Amazon SQS [14]。 分散-汇聚已被识别为一种企业集成模式 [12]。
7 结论
正如面向对象编程引出了面向对象的“设计模式”的出现和规范化一样,我们看到容器体系结构引出了基于容器的分布式系统的设计模式。在本文中,我们识别了我们看到的三种类型的模式:系统管理的单容器模式、紧密协作容器的单节点模式和分布式算法的多节点模式。在所有情况下,容器都提供了许多与面向对象系统中的对象相同的好处,例如可以很容易地在多个团队之间划分实现,并在新的上下文中重用组件。此外,它们还提供了一些分布式系统独有的好处,例如使组件能够独立升级、多种语言编写,以及使整个系统能够优雅地降级。就像几十年前面向对象编程一样,我们相信,容器模式集只会增长,并且在未来几年,通过实现分布式系统开发的标准化和规范化,它们将彻底改变分布式系统编程。
8 参考文献
[1] Docker Engine http://www.docker.com
[2] rkt: a security-minded standards-based container engine https://coreos.com/rkt/
[3] Erich Gamma, John Vlissides, Ralph Johnson, Richard Helm, Design Patterns: Elements of Reusable Object-Oriented Software, AddisonWesley, Massachusetts, 1994.
[4] Jeffrey Dean, Sanjay Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, Sixth Symposium on Operating System Design and Implementation, San Francisco, CA 2004.
[5] Apache Hadoop, http://hadoop.apache.org
[6] Kubernetes, http://kubernetes.io
[7] Apache Aurora, https://aurora.apache.org.
[8] Marathon: A cluster-wide init and control system for services, https://mesosphere.github.io/marathon/
[9] Managing the Activity Lifecycle, http://developer.android.com/training/basics/activitylifecycle/index.html
[10] Brendan Burns, The Distributed System ToolKit: Patterns for Composite Containers, http://blog.kubernetes.io/2015/06/the-distributedsystem-toolkit-patterns.html
[11] Nomad by Hashicorp, https://www.nomadproject.io/
[12] Gregor Hohpe, Enterprise Integration Patterns, Addison-Wesley, Massachusetts, 2004.
[13] Celery: Distributed Task Queue, http://www.celeryproject.org/
[14] Amazon Simple Queue Service, https://aws.amazon.com/sqs/
[15] https://www.kernel.org/doc/Documentation/cgroupv1/cgroups.txt
[16] Service Oriented Architecture, https://en.wikipedia.org/wiki/Serviceoriented architecture
[17] Amazon EC2 Container Service, https://aws.amazon.com/ecs/
[18] Docker Swarm https://docker.com/swarm
[19] J. Case, M. Fedor, M. Schoffstall, J. Davin, A Simple Network Management Protocol (SNMP), https://www.ietf.org/rfc/rfc1157.txt, 1990.
[20] R. G. Gallager, P. A. Humblet, P. M. Spira, A distributed algorithm for minimum-weight spanning trees, ACM Transactions on Programming Languages and Systems, January, 1983.
[21] M.J. Litzkow, M. Livny, M. W. Mutka, Condor: a hunter of idle workstations, IEEE Distributed Computing Systems, 1988.
[22] https://linuxcontainers.org/
来源:Design Patterns for Container-based Distributed Systems
本文翻译仅用于学习与技术交流,版权归原作者所有,如有侵权请联系删除。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/11-13-2022/design-patterns-for-container-based-distributed-systems-cn.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!