
在众多应用中,缓存都是标配,使用缓存都能获得非常巨大的性能提升。然而却少有人能把缓存用好,使用缓存的服务,随着需求的迭代都会不可避免的陷入一种怪圈:
业务侧
- 为了优化接口性能增加缓存
- 同一接口复杂度高、性能差、缺少可维护性,无法开发新需求
运维侧
- 提高存储和查询容量应对使用压力
- 成本压力倒逼业务再次优化,提高缓存使用率
在反复的折腾之下,系统难以维护,最终不得不走向整体“重构”。
举个例子
以微博为例,当打开微博时,页面主要数据构成有:分类列表(左侧);微博列表(中间);个人信息;关注、粉丝、微博数(最右侧)。
按照一般的后台设计准则,假设页面所需的数据拆解如下: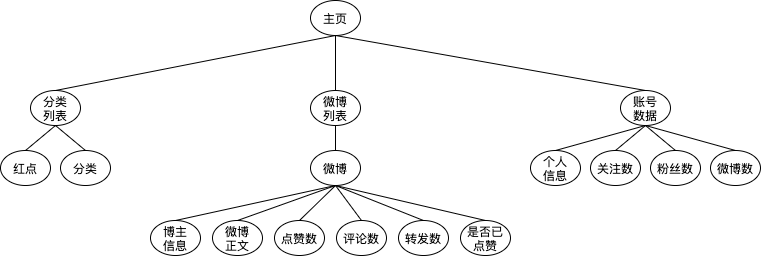
需要重点说明几点:
- 微博不等于微博正文
微博指微博ID,微博正文指微博的内容。
- 微博列表也是一种数据
微博列表代表的是微博ID的集合
在《如何设计RPC接口》 中我们提到过一个观点:所有的数据都等于 ID + Content,同时 ID 又可以以集合的形式存在。
假设查询微博列表是一个单独的API接口,各种数据在系统中的表达分别为:post(微博)、profile(个人信息)、stat(点赞、评论等计数、点赞)。那么通常的实现是:
SELECT ... FROM post LEFT JOIN profile LEFT JOIN stat ...两张大表直接进行关联。如果扛不住,就添加缓存,将查询结果缓存。
那么,在开发过程中是否真的无法逃出这一怪圈?答案当然是否定的,本文的目的就是承接 《系统设计之概念与关系》、《如何设计RPC接口》 ,谈谈如何设计,才能让数据落地到缓存。
结构化缓存
具体来看怎么做的,实际上可以将以上查询进行拆分:
SELECT * FROM post WHERE ...
SELECT * FROM profile WHERE id in (...)
SELECT * FROM stat WHERE id in (...)很多人看到这里会直摇头,这不就直接会导致一次API调用,会直接导致 N 次数据库查询。那你怎么能这样拆分呢?
事实上并非如此,由于缓存的存在,后两个数据库查询都会命中应用缓存,最终只会有一次简单查询到数据库。考虑最差的情况应用缓存没有命中,后两个数据库查询也会极大概率命中数据的缓存。同时,随着业务的迭代,可以放心使用组合模式,不断组合其他数据,而不用担心复杂度的高度。再次,考虑 KOL 的微博访问量大,可以沿着结构树不断向上添加缓存(例如:在微博列表层添加缓存)。最后,如果分布式缓存压力太大,还可以组合本地缓存使用。
最重要的是,以上提到的所有优化点,都可以使用组合模式实现,而不用大幅度调整代码,避免陷入开发、优化、重构的怪圈。
再看拆分前,由于使用SQL关联操作,会在业务的发展过程中不断面临挑战:
- 关联查询可能导致大范围的扫表,频繁磁盘IO,性能差
- 缓存命中率低
- 业务迭代,额外查询其他数据,复杂度不断叠加
总结
在本文末尾,再次总结提及的几个关键观点:
- 数据查询有且仅有三种模式
- 根据条件,分页查询 ID 列表
- 根据 ID 查询内容
- 根据 ID 列表批量查询内容
- 所有的结构仅仅存在两种关系
- 并列(兄弟)关系
- 父子关系
- 结构化和组合模式是应对复杂性有效方法
缓存不过是一种形式的复杂性
当然此种实现并非没有代价。显然,如果数据的访问频率很低,极少的结果才会命中缓存,那么效果就微乎其微。而梳理数据关系、结构,以及按照拆分的形式实现代码,将花费不少的时间,在讲究快速开发、先撑住再优化的今天,很容易让开发者采取非此即彼的决策。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/02-18-2021/high-concurrency-cache-design.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!