
一、引言
本文基于 RocksDB v8.8.1 代码与文档,从代码层面分析 RocksDB 的空间管理机制。默认使用 leveled compaction,SstFileManager 已启用且设置了 max_allowed_space_ > 0(否则其“硬限制”与 compaction_buffer_size_ 的常规检查不生效),除特别说明外,默认单 DB 实例,且主要讨论 db_paths[0] / cf_paths[0] 路径。
当空间不足时,RocksDB 会拒绝新的 Compaction 任务以避免磁盘写满。Flush 不做事前空间检查,第一次 Flush 仍会执行;但如果 Flush 完成后触发 SpaceLimit/NoSpace 等硬错误,DB 会进入 stopped 状态,后续 Flush(错误恢复 Flush 除外)会被跳过。这仍可能导致 L0 文件堆积,最终触发 Write Stall,写入延迟急剧上升甚至完全停止。这会形成恶性循环:无法执行 Compaction 就无法回收空间,空间越少就越难执行 Compaction,直到服务完全不可用。一个典型的陷阱是”删除数据后空间不减反增”:删除操作只是写入 Tombstone 标记,真正的空间回收要等 Compaction 完成。如果此时空间已经紧张,Compaction 被拒绝,删除操作反而会占用更多空间。
LSM-Tree 的设计特性决定了 Compaction 过程中原文件和新文件必须同时存在,峰值空间可达输入数据的两倍。RocksDB 通过预留缓冲区机制来应对这一问题,确保关键操作(如 WAL 写入和 Flush)在空间紧张时仍有足够空间可用。
二、RocksDB 的四种磁盘数据类型
RocksDB 在磁盘上会产生四种类型的文件,它们各自独立管理,这正是空间管理复杂性的根源。
SST 文件是 RocksDB 存储实际数据的地方,由 Flush 和 Compaction 产生。SstFileManager 可以对其跟踪到的 SST/Blob 文件施加硬限制。坏消息是,Compaction 的峰值空间需求使得这个”硬限制”并不能简单地等于磁盘容量。
WAL 文件(Write-Ahead Log)记录每次写入操作,用于故障恢复。WAL 的限制是”软”的:当达到 max_total_wal_size 阈值时,RocksDB 会触发 Flush 来清理 WAL,但在 Flush 完成之前,WAL 可能继续增长。高写入压力下,WAL 实际大小可能显著超过配置值。
LOG 文件是 RocksDB 的运行日志,记录各种操作信息。LOG 通过 max_log_file_size(单文件大小)和 keep_log_file_num(保留数量)控制,总量上限约为两者的乘积。这只是轮转机制,不是硬限制。
MANIFEST 文件记录数据库的元数据和版本信息,通常较小,但在频繁变更的场景下也可能累积。
理解这四种文件的关键在于:它们由不同的组件独立管理,互不感知。SST 空间紧张时,不会自动减少 WAL 或 LOG 的配额。这意味着,即使精确控制了 SST 的空间,WAL 或 LOG 的意外增长仍可能导致磁盘写满。
三、各类型文件的空间控制机制
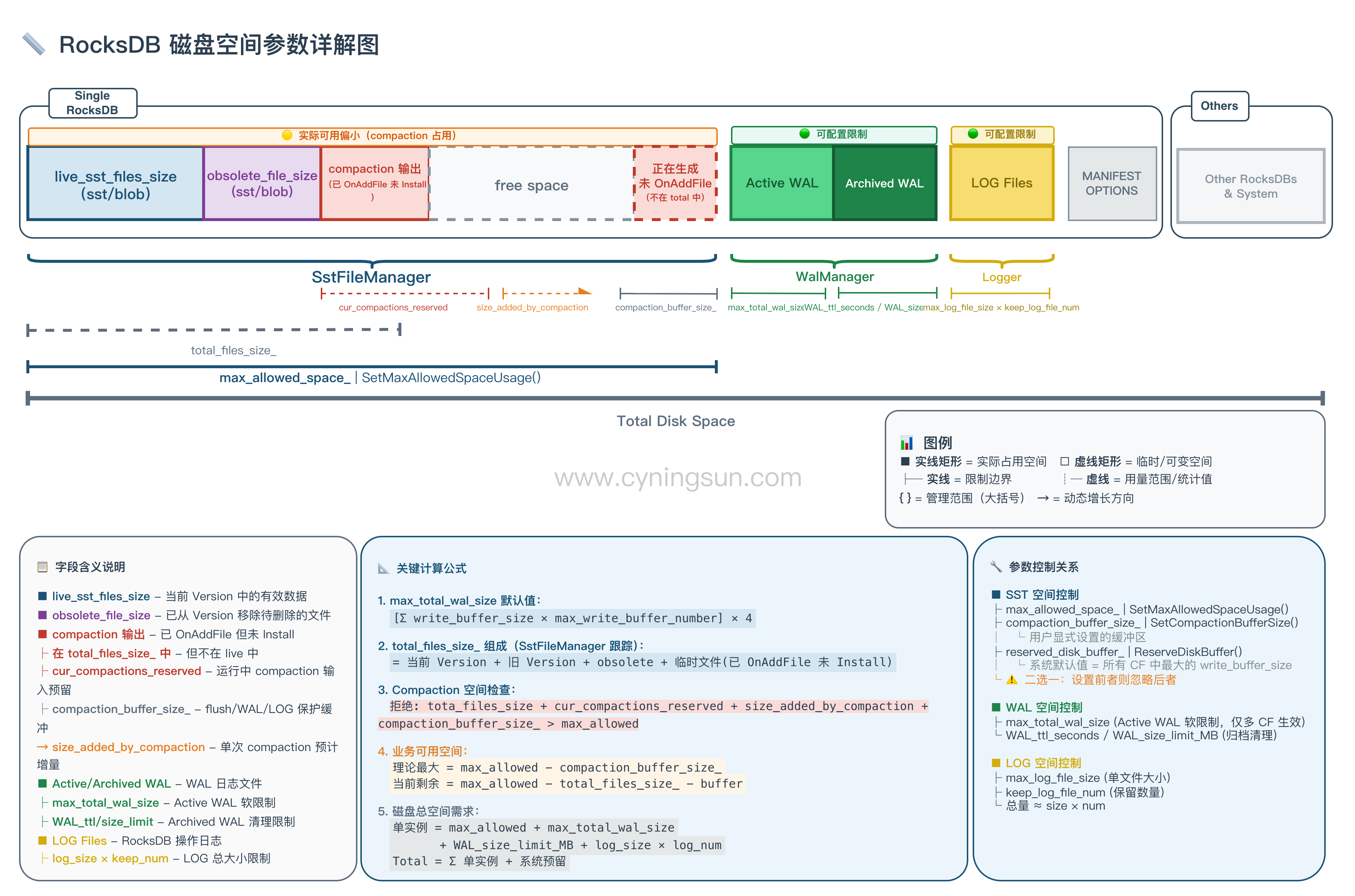
3.1 SST 文件:SstFileManager 的硬限制
SST 文件的空间控制是 RocksDB 中最完善的部分。SstFileManager 通过 max_allowed_space_ 设置其跟踪文件(SST/Blob)的总量上限。当前实现中,Flush/Compaction 输出上报与 Open 扫描主要覆盖 db_paths[0]/cf_paths[0](path_id=0),多路径场景需特别注意统计口径。
写入过程的空间检查分为四个阶段:
- 写入阶段:用户写入时不检查
max_allowed_space,数据直接写入 MemTable 和 WAL - Flush 阶段:MemTable Flush 成 SST 后,调用
IsMaxAllowedSpaceReached()检查total_files_size_ >= max_allowed_space_,如果超限则设置BGError为Status::SpaceLimit - 后续写入:触发错误的当前写请求(如 WAL append 失败)会直接失败;后续写入是否在
PreprocessWrite()阶段被拒绝,取决于 DB 是否已进入 stopped 状态 - 后续 Flush:若错误严重级别达到 HardError(默认
paranoid_checks=true时,Flush 路径的SpaceLimit/NoSpace会映射为 HardError),is_db_stopped_会被置为true,普通 Flush 在IsBGWorkStopped()为 true 时会被跳过(错误恢复 Flush 除外)
bool SstFileManagerImpl::IsMaxAllowedSpaceReached() {
MutexLock l(&mu_);
if (max_allowed_space_ <= 0) {
return false;
}
return total_files_size_ >= max_allowed_space_;
}这种异步检查机制意味着,当空间真正不足时,可能已经有部分数据写入了 MemTable 和 WAL;当前请求可能先失败,而后续写入是否被入口直接拒绝取决于 DB 是否已 stopped。
相比 Flush 的事后异步检查,Compaction 采用的是事前同步检查:在 Compaction 任务开始执行前,会调用 EnoughRoomForCompaction() 预先验证是否有足够空间完成整个操作,如果空间不足则直接拒绝该 Compaction 任务。从代码可以看出,Flush 必须尽可能执行(即使可能导致空间超限),而 Compaction 可以延后甚至取消。核心检查逻辑如下:
// file/sst_file_manager_impl.cc:148-205
bool SstFileManagerImpl::EnoughRoomForCompaction(
ColumnFamilyData* cfd, const std::vector<CompactionInputFiles>& inputs,
const Status& bg_error) {
MutexLock l(&mu_);
uint64_t size_added_by_compaction = 0;
// First check if we even have the space to do the compaction
for (size_t i = 0; i < inputs.size(); i++) {
for (size_t j = 0; j < inputs[i].size(); j++) {
FileMetaData* filemeta = inputs[i][j];
size_added_by_compaction += filemeta->fd.GetFileSize();
}
}
// Update cur_compactions_reserved_size_ so concurrent compaction
// don't max out space
size_t needed_headroom = cur_compactions_reserved_size_ +
size_added_by_compaction + compaction_buffer_size_;
if (max_allowed_space_ != 0 &&
(needed_headroom + total_files_size_ > max_allowed_space_)) {
return false;
}
// Implement more aggressive checks only if this DB instance has already
// seen a NoSpace() error. ...
if (bg_error.IsNoSpace() && CheckFreeSpace()) {
// ... 获取文件路径 fn ...
uint64_t free_space = 0;
Status s = fs_->GetFreeSpace(fn, IOOptions(), &free_space, nullptr);
s.PermitUncheckedError(); // TODO: Check the status
// ... If user didn't specify any compaction buffer, add reserved_disk_buffer_
if (compaction_buffer_size_ == 0) {
needed_headroom += reserved_disk_buffer_;
}
if (free_space < needed_headroom + size_added_by_compaction) {
// ... 日志记录 ...
return false;
}
}
cur_compactions_reserved_size_ += size_added_by_compaction;
// Take a snapshot of cur_compactions_reserved_size_ for when we encounter
// a NoSpace error.
free_space_trigger_ = cur_compactions_reserved_size_;
return true;
}理解上述检查逻辑的关键在于明确 total_files_size_ 的统计口径。SstFileManager 的 total_files_size_ 是 tracked_files_ 的求和,由 OnAddFile/OnDeleteFile 驱动,因此它统计的是”被 SstFileManager 注册过”的文件,而不是”某个 Version 视角下的全部文件”。通常会覆盖:当前 Version 使用中的 SST/Blob、旧 Version 被 Iterator/Snapshot 持有的文件、尚未物理删除的 obsolete 文件、以及已 OnAddFile 但尚未安装到 Version 的临时输出文件;它不包含正在生成但尚未 OnAddFile 的文件。
需要特别注意两点。第一,DB::Open 只会扫描 db_paths[0] 和各 Column Family 的 cf_paths[0] 来注册现有 SST/Blob 文件,可能包含不在 MANIFEST 中的孤立文件。第二,Compaction 输出仅在 path_id == 0 时才会上报给 SstFileManager,因此多路径场景下 total_files_size_ 与真实磁盘占用可能存在系统性偏差。
与之对比,rocksdb.live-sst-files-size 是 Column Family current Version 视角,仅统计 live SST;rocksdb.total-sst-files-size 是该 Column Family 所有 Version 去重后的 SST 总和。它们与 SstFileManager 的 total_files_size_ 在对象范围和路径范围上都不同,因此不宜简单用 total_files_size_ - live_sst_files_size 推断 obsolete SST 大小。
对于可回收空间的精确监控,SST 部分建议直接使用 rocksdb.obsolete-sst-files-size;Blob 部分 RocksDB 未提供对应的 obsolete 指标,rocksdb.total-blob-file-size - rocksdb.live-blob-file-size 更接近”非 current-version blob 规模”,不等价于”待删除 blob 空间”。若启用 BlobDB,应结合 live-blob-file-size / total-blob-file-size 观察整体空间使用情况。
上述代码中 compaction_buffer_size_ 和 reserved_disk_buffer_ 的具体作用和触发条件,详见 §3.4。
当且仅当配置了 max_allowed_space_ > 0 时,业务可用空间可以从两个视角理解。从配置规划角度,业务理论最大可用空间约为 max_allowed_space_ - compaction_buffer_size_。从运行时监控角度,当前实际剩余空间约为 max_allowed_space_ - total_files_size_ - compaction_buffer_size_,反映了在 SstFileManager 统计口径下,扣除已使用空间与保护缓冲区后还能写入的数据规模。
3.2 WAL 文件:软限制与生命周期
WAL 的空间控制涉及三个参数:max_total_wal_size 控制活跃 WAL 的总大小,超过时触发 Flush;WAL_ttl_seconds 和 WAL_size_limit_MB 控制归档 WAL 的清理策略。需要注意 max_total_wal_size 主要用于多 Column Family 场景触发 Flush;单 Column Family 场景下,WAL 大小更多受 MemTable/Flush 节奏影响。
如果不显式设置 max_total_wal_size,RocksDB 会使用默认值:
默认值 = [Σ write_buffer_size × max_write_buffer_number] × 4需要注意的是,WAL 的限制是”软”的——超过阈值时触发 Flush,而非阻止写入。在 Flush 完成之前,WAL 仍会继续增长,高写入压力下可能显著超过配置值。
WAL 写入失败的严重后果:
与 SST 文件不同,WAL 写入失败会让当前写请求立即失败。当系统磁盘空间耗尽,WriteToWAL() 返回 IOStatus::NoSpace() 时,会触发以下处理流程:
// db/db_impl/db_impl_write.cc:756-761
if (!io_s.ok()) {
// Check WriteToWAL status
IOStatusCheck(io_s); // 立即设置 BGError
}
// ... else 分支省略 ...
// db/db_impl/db_impl_write.cc:1117-1131
void DBImpl::IOStatusCheck(const IOStatus& io_status) {
// Is setting bg_error_ enough here? This will at least stop
// compaction and fail any further writes.
if ((immutable_db_options_.paranoid_checks && !io_status.ok() &&
!io_status.IsBusy() && !io_status.IsIncomplete()) ||
io_status.IsIOFenced()) {
mutex_.Lock();
// Maybe change the return status to void?
error_handler_.SetBGError(io_status, BackgroundErrorReason::kWriteCallback);
mutex_.Unlock();
} else {
// Force writable file to be continue writable.
logs_.back().writer->file()->reset_seen_error();
}
}当 IOStatusCheck() 将错误上报给 ErrorHandler 且错误严重级别升级到 HardError 时,DB 会进入 stopped,后续写入会在 PreprocessWrite() 入口返回该后台错误。若 paranoid_checks=false,则同样的 WAL 错误不一定会触发这一停库路径。
3.3 LOG 文件
LOG 文件通过 max_log_file_size(单文件大小)和 keep_log_file_num(保留数量)控制,总量约为两者的乘积。这只是轮转机制,不是硬限制。
3.4 CompactionBufferSize:主要的跨系统保护
核心问题:SST、WAL、LOG 由不同组件独立管理、互不感知。当 SST 空间紧张时,不会自动为 WAL、LOG、MANIFEST 等文件预留空间。如 §3.1 所述,Flush 无事前检查、仅事后检查,Compaction 同时存在事前和事后检查。这意味着 Compaction 可能因空间不足被拒绝,但 Flush 和 WAL 写入仍需继续执行——如果此时没有预留空间,可能导致磁盘写满。
解决方案:compaction_buffer_size_ 是 RocksDB 的主要跨系统保护旋钮。需要注意,它在 SstFileManager 常规空间检查中稳定生效的前提是 max_allowed_space_ > 0。在该前提下,它会在 SST 空间检查时预留一块缓冲区,给以下文件和场景留出余量:WAL 文件(包括 Active 和 Archived)、LOG 文件(RocksDB 操作日志)、MANIFEST 文件(数据库元数据)、Flush 过程中正在生成但尚未调用 OnAddFile 的 SST 文件、Compaction 过程中正在生成但尚未调用 OnAddFile 的输出 SST 文件。
实现细节:compaction_buffer_size_ 是用户显式设置的保护缓冲区大小,在正常检查中会直接参与 needed_headroom 计算。reserved_disk_buffer_ 由 ReserveDiskBuffer() 累加:单 DB 实例时通常等于该实例所有 Column Family 的最大 write_buffer_size;若多个 DB 共享同一个 SstFileManager,则会叠加多个实例的预留值。它只在满足全部条件时才会额外加入检查:当前 bg_error 为 IOError::NoSpace(SpaceLimit 不满足)、SstFileManager 内部错误严重级别为 kSoftError、且 compaction_buffer_size_ 为 0。
四、影响磁盘空间的操作分析
4.1 常规操作的空间影响
写入操作会立即增加 WAL 大小,同时 LOG 记录操作日志。数据先写入内存中的 MemTable,此时不占用 SST 空间。
删除操作不会立即释放空间,而是写入 Tombstone 标记,反而会短暂增加空间占用。真正的空间回收要等 Compaction 将 Tombstone 与原数据合并后才能完成。
Flush 操作将 MemTable 持久化为 SST 文件。Flush 完成后,当所有引用该 WAL 的 Column Family 都已 flush 时,该 WAL 变为 obsolete,可被清理(如果配置了 WAL_ttl_seconds 或 WAL_size_limit_MB 则先归档,否则直接删除)。
4.2 高风险操作详解
DB::Open() 在特定配置下可能触发大规模层级重整。最典型的场景是启用 level_compaction_dynamic_level_bytes 后首次打开数据库:RocksDB 会自动执行 Trivial Move 来调整层级结构。Trivial Move 本身只是元数据操作(VersionEdit),不复制 SST 文件,磁盘空间不会因此变化。但层级重整后,大量文件被移动到底层,随后触发的底层 Compaction 才是真正的空间风险所在(见 §4.4)。
// db/db_impl/db_impl_open.cc:582-641
// 当启用 level_compaction_dynamic_level_bytes=true 时
// DB 打开时会自动进行 trivial move,完全不检查 max_compaction_bytes
for (int from_level = to_level; from_level >= 0; --from_level) {
const std::vector<FileMetaData*>& level_files =
cfd->current()->storage_info()->LevelFiles(from_level);
if (level_files.empty() || from_level == 0) {
continue;
}
// ... assert 省略 ...
// Trivial move files from `from_level` to `to_level`
if (from_level < to_level) {
VersionEdit edit;
edit.SetColumnFamily(cfd->GetID());
for (const FileMetaData* f : level_files) {
edit.DeleteFile(from_level, f->fd.GetNumber());
edit.AddFile(to_level, f->fd.GetNumber(), f->fd.GetPathId(),
f->fd.GetFileSize(), f->smallest, f->largest,
/* ... 其他元数据参数 ... */);
}
recovery_ctx->UpdateVersionEdits(cfd, edit);
}
--to_level;
}CompactRange() 在 Leveled Compaction 下,input_level > 0 时文件选择阶段受 max_compaction_bytes 约束;但 input_level == 0 时不受此限制(L0 文件可重叠,必须全部选入)。尽管单次 compaction 有大小限制,全范围压缩 CompactRange(nullptr, nullptr) 会逐层执行多次 compaction,整体仍可能导致大量数据参与,峰值空间占用可达原始数据的两倍(输入文件 + 输出文件同时存在)。
CompactFiles() 允许用户直接指定参与压缩的文件列表,绕过了 RocksDB 的自动选择逻辑。如果选择的文件集合过大,同样可能导致严重的空间问题。
IngestExternalFile() 导入外部 SST 文件时,内部会构造用于范围冲突管理的”等价 Compaction”对象,该对象使用 LLONG_MAX(并非真实重写任务本身)。真正的空间风险在于:外部文件若相互重叠会落入 L0,随后触发的大型自动压缩可能带来峰值空间压力。
4.3 自动 Compaction 的空间控制
自动 Compaction 相对可控,主要受 max_compaction_bytes 约束。这个参数的默认值是 target_file_size_base * 25 = 1.6GB,目的是控制单次 Compaction 的资源消耗(临时磁盘空间、I/O 带宽、执行时间)。在 Compaction 选择阶段,计算”Ln 层选中的文件大小 + Ln+1 层中与之重叠的文件大小”,总和超过 max_compaction_bytes 就停止扩展更多文件。在 Trivial Move 场景下,还会检查”移动到 Ln+1 的文件大小 + Ln+2 层重叠文件大小”是否超过 max_compaction_bytes,防止后续 Ln+1 → Ln+2 的 Compaction 过大。
但该限制并非硬性的:为了保证 Clean Cut(文件边界对齐),可能必须包含额外文件;某些情况下为了数据一致性,必须将特定文件纳入同一次 Compaction。因此 max_compaction_bytes 更像是”尽量遵守”的软约束。
4.4 底层 Compaction 的特殊性
最底层 Compaction 通常没有更低层可作为祖父层(Grandparent),因此”基于祖父层重叠边界的切分优化”在这里不适用。但输出文件仍受 max_output_file_size 和输出切分逻辑约束,并非完全无边界。
该特性会与 DB::Open() 的 Trivial Move 形成风险叠加:启用 level_compaction_dynamic_level_bytes 后,Open 阶段的 Trivial Move 不检查 max_compaction_bytes,可能把大量文件下沉到底层,随后底层 Compaction 一次处理的数据规模变大,峰值空间可能接近翻倍。
五、空间相关的监控指标
RocksDB 提供了以下与空间管理直接相关的内部指标:
// 1. Live SST Files Size(当前 Version 中的有效数据)
db->GetProperty("rocksdb.live-sst-files-size", &live_size);
// 说明:仅包含 current_ Version 中所有层级的文件,不包含 obsolete 和临时文件
// 2. Total SST Files Size(该 Column Family 所有 Version 中的 SST 文件)
db->GetProperty("rocksdb.total-sst-files-size", &total_size);
// 说明:遍历该 Column Family 的所有 Version(含被 Iterator/Snapshot 持有的旧 Version),去重求和
// 注意:这不等于 SstFileManager 的 total_files_size_(后者还包含 obsolete 文件和
// 已 OnAddFile 但尚未 Install 的临时文件,正常情况下差距很小)
// 3. Pending Compaction Bytes(等待 compaction 的字节数)
db->GetProperty("rocksdb.estimate-pending-compaction-bytes", &pending_bytes);
// 说明:Level Compaction 下,需要重写的数据量估算
// 4. L0 Files Count(L0 层文件数量)
db->GetProperty("rocksdb.num-files-at-level0", &l0_files);
// 说明:L0 积压是空间不足的典型表现
// 当 compaction 被取消时,L0 文件会持续堆积
// 5. Compaction Cancelled(累计取消的 compaction 次数)
uint64_t cancelled = statistics->getTickerCount(COMPACTION_CANCELLED);
// 触发条件:EnoughRoomForCompaction() 返回 false
// 这是最直接的"磁盘空间不足"信号
// 6. Obsolete SST Files Size(已 obsolete 但尚未删除的 SST)
db->GetProperty("rocksdb.obsolete-sst-files-size", &obsolete_sst_bytes);
// 说明:这是待删 SST 的直接观测指标(全 DB 口径)六、总结
compaction_buffer_size_ 是空间管理的核心保护机制之一。当 compaction_buffer_size_ 为 0 时,正常检查不会有额外缓冲区保护(reserved_disk_buffer_ 仅在 bg_error 为 IOError::NoSpace 且 SstFileManager 内部错误为 kSoftError 时才会生效)。
RocksDB 的空间管理有以下关键特征:
- SstFileManager 提供的是”按其跟踪范围”的硬限制:通过
max_allowed_space_控制跟踪到的 SST/Blob 文件。风险:路径覆盖差异与 WAL/LOG 的意外增长仍可能导致磁盘写满。 - Flush 和 Compaction 的空间检查策略不同:Flush 无事前检查且在事后超限时可能停库并跳过后续普通 Flush;Compaction 同时存在事前(
EnoughRoomForCompaction())和事后(输出后IsMaxAllowedSpaceReached())检查。影响:L0 易堆积并触发 Write Stall。 - 四种文件类型独立管理、互不感知:
compaction_buffer_size_是主要的跨系统保护旋钮,但在max_allowed_space_ > 0的常规检查路径下才稳定生效。风险:配置为 0 或过小会导致 WAL/LOG/MANIFEST 保护不足。 - 手动操作(CompactRange/CompactFiles/IngestExternalFile)的空间约束弱于自动 Compaction。风险:全范围压缩或大文件集合可能导致峰值空间接近翻倍,需谨慎使用。
- 底层 Compaction 不适用祖父层边界优化:与 DB::Open 的 Trivial Move 叠加时风险最大。影响:启用
level_compaction_dynamic_level_bytes后首次打开可能触发大规模底层 Compaction,峰值空间需求显著增加。
附录:运维经验与配置参考
以下内容基于运维经验和假设场景,非 RocksDB 代码内置逻辑,仅供参考。
A. 生产环境利用率分析
通过合理设置 compaction_buffer_size_ 等参数,只允许利用预留的空间进行 Compaction,业务数据理论上可以占到 max_allowed_space_ 的 90% 以上(详见 §C 配置示例)。
然而,生产环境的实际利用率会更低:
- 扩容水位:如果采用小的逻辑隔离集群而非大的共享集群,通常在 70~80% 时触发扩容告警(业界常见做法),预留充足的时间进行数据迁移,避免接近上限
- 主从复制:主从断连需要全量同步时,从节点必须同时保留旧数据和新数据,空间需求翻倍。除非重新新建从节点替代的旧从节点(增加运维负担),或者使用 RAFT/Paxos 等 3 副本方案(可安全丢弃旧数据),否则双副本架构下
max_allowed_space_可能只能设为磁盘容量的 50%
以 1TB 专用数据盘为例,格式化为 ext4 后空间约 940GB。配置 max_allowed_space_ = 900GB(含 30GB 的 compaction_buffer,在 900GB 内预留):
- 无主从复制场景:业务实际可用约 610~700GB
- 主从复制场景:
max_allowed_space_需限制到 450GB,业务实际可用约 280~320GB
从平台产品角度看使用率更低:上述计算基于扩容水位(70~80%),但实际运维中,业务不会持续保持在高水位并频繁扩容。触发扩容告警后,增加容量会使使用率大幅下降,平台的平均磁盘使用率往往只有 **40-60%**(经验估算)。以 1TB 磁盘为例,按前文无主从复制场景的 610~700GB 可用空间和 40-60% 平均水位计算,长期平均业务数据量约 250~420GB。
此外,如果采用小的逻辑隔离集群而非大的共享集群,还会产生集群外碎片问题:集群规格通常是固定的(如 100GB、200GB、500GB 等档位),用户实际数据可能只需 80GB,却不得不购买 100GB 规格,造成约 20% 的容量浪费。大共享集群可以更灵活地分配资源,但隔离性较差。这是平台产品设计中的经典权衡。
B. CompactionBufferSize 参考公式
// 参考公式(非 RocksDB 内置逻辑,需根据实际场景调整):
// WAL 峰值 + LOG 峰值 + 安全边际
compaction_buffer_size ≈ max_total_wal_size + (WAL_size_limit_MB / 1024)
+ (max_log_file_size × keep_log_file_num / GB)
+ safety_marginC. 配置示例(1TB 专用数据盘)
假设有一块 1TB 的专用数据盘(系统使用独立磁盘),格式化为 ext4 文件系统,该如何配置 RocksDB,能存储多少业务数据?
1TB 原始磁盘格式化为 ext4 后(默认参数),扣除保留块(5%)、元数据(1%)等开销约 60GB,普通用户实际可用约 940GB。以此为基础配置 RocksDB:
配置方案(无主从复制):
// 1. SST 空间控制
auto sfm = NewSstFileManager(env);
sfm->SetMaxAllowedSpaceUsage(900ULL * 1024 * 1024 * 1024); // 900GB(SST 硬限制)
sfm->SetCompactionBufferSize(30ULL * 1024 * 1024 * 1024); // 30GB(在 900GB 内预留)
// 2. WAL 空间控制(考虑主从复制场景)
options.max_total_wal_size = 512ULL * 1024 * 1024; // 512MB Active WAL(主从延迟/断连容忍)
options.WAL_ttl_seconds = 21600; // 6 小时 TTL(避免从节点短期断连需要全量同步)
options.WAL_size_limit_MB = 16384; // 16GB Archived 限制(对应 6 小时产生量)
// 3. LOG 空间控制
options.max_log_file_size = 512 * 1024 * 1024; // 512MB/文件
options.keep_log_file_num = 8; // 保留 8 个
options.info_log_level = WARN_LEVEL; // 生产环境建议空间分配详解:
| 项目 | 大小 | 说明 |
|---|---|---|
| 文件系统可用 | 940GB | 1024GB - 约 60GB(保留块 5% + 元数据 1%) |
max_allowed_space_ |
900GB | SST 文件硬限制(含 compaction 临时文件) |
├─ compaction_buffer |
30GB | 在 900GB 内预留(防止 SST 占满) |
| ├─ 业务实际可用 | ≤870GB | 900GB - 30GB 缓冲 |
| WAL 配置空间 | 16.5GB | Active 512MB + Archived 16GB(文件系统层面) |
| LOG 配置空间 | 4GB | 512MB × 8 ≈ 4GB(文件系统层面) |
文件系统余量(max_allowed_space_ 之外) |
40GB | 940 - 900(应对配置误差与突发开销) |
上表中的 40GB 是 “max_allowed_space_ 之外的余量” 口径,不是扣除 WAL/LOG 后的实时可用值;WAL/LOG 与临时文件的安全性依赖 compaction_buffer_size_ 和该余量共同兜底。
业务可用空间为 max_allowed_space_(900GB)中扣除空间检查时强制预留 compaction_buffer(30GB),业务理论可用约 870GB(= 900 - 30)。但考虑 70-80% 扩容水位,实际可用约 610~700GB。
D. 空间不足时的降级策略
当监控到以下信号时,说明空间管理出现问题,需要主动干预:
COMPACTION_CANCELLED持续增长:空间不足导致 compaction 被频繁取消(最关键信号)rocksdb.estimate-pending-compaction-bytes持续增大:等待 compaction 的数据量不断积压rocksdb.num-files-at-level0超阈值:L0 文件堆积,可能触发 write stallrocksdb.obsolete-sst-files-size持续增大:过期 SST 积压,无法及时删除
降级策略优先级:
立即清理 obsolete files
// 重启 DB(会强制全量扫描并清理 obsolete 文件) // 若之前禁用过文件删除,先恢复(真实可调用 API) db->EnableFileDeletions(/*force=*/false);临时调整参数
// 增加 compaction 线程数(加快空间回收) db->SetDBOptions({{"max_background_jobs", "6"}}); // 默认为 2 // 提高 write stall/stop 阈值(延缓写入阻塞,争取更多时间回收空间) db->SetOptions({ {"level0_slowdown_writes_trigger", "30"}, // 默认 20 {"level0_stop_writes_trigger", "40"}, // 默认 36 {"soft_pending_compaction_bytes_limit", "128GB"}, // 默认 64GB {"hard_pending_compaction_bytes_limit", "256GB"} // 默认 256GB });紧急扩容
- 如果以上措施无效,说明配置严重不足,需要紧急扩容
E. 提升空间利用率的方案
综合前文分析,传统架构下存储层长期平均使用率较低。以 §C 的 1TB 配置示例为例,无主从复制场景下业务可用约 610~700GB,按 70-80% 扩容水位的平均值估算,长期水位约 35-40%。提升利用率有以下方向:
- 共享大集群:多租户共享总空间,无需每个租户单独预留集群容量和 Compaction 空间,利用率可显著提升(经验估算 **65%~75%**)。主要面临的问题:隔离性差,资源争抢风险。
- 存算分离:SST 文件存储在远程存储(S3/OSS),本地磁盘仅存 WAL/LOG。本地磁盘无需预留 Compaction 临时文件空间,远程存储按需弹性扩展,无扩容水位损耗,利用率可进一步提升(经验估算 **75%~85%**)。主要面临的问题:读写延迟增加(需通过缓存优化)。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/03-27-2026/rocksdb-space-mgr.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!