
Satadru Pan¹, Theano Stavrinos¹,², Yunqiao Zhang¹, Atul Sikaria¹, Pavel Zakharov¹, Abhinav Sharma¹, Shiva Shankar P¹, Mike Shuey¹, Richard Wareing¹, Monika Gangapuram¹, Guanglei Cao¹, Christian Preseau¹, Pratap Singh¹, Kestutis Patiejunas¹, JR Tipton¹, Ethan Katz-Bassett³, Wyatt Lloyd²
¹Facebook, Inc., ²普林斯顿大学, ³哥伦比亚大学
摘要
Tectonic 是 Facebook 的艾字节级分布式文件系统。Tectonic 将之前使用特定服务系统的庞大租户整合到通用的多租户文件系统实例中,并实现了与专用系统相当的性能。EB 级的整合实例相较于我们之前的方法,能够实现更好的资源利用率、更简单的服务以及更少的运维复杂度。本文描述了 Tectonic 的设计,解释了它如何实现可扩展性、支持多租户,并允许租户定制操作以优化多样化的工作负载。本文还分享了从设计、部署和运维 Tectonic 中获得的经验。
1 引言
Tectonic 是 Facebook 的分布式文件系统。它目前服务于大约十个租户,包括存储艾字节数据的 Blob 存储和数据仓库。在 Tectonic 之前,Facebook 的存储基础设施由众多规模较小、专用的存储系统组成。Blob 存储分散在 Haystack [11] 和 f4 [34] 中。数据仓库则分散在多个 HDFS 实例 [15] 中。
这种多系统方法运维复杂,需要开发、优化和管理许多不同的系统。它效率低下,导致资源被束缚在专用存储系统中,而这些资源本可以重新分配给存储工作负载的其他部分。
一个 Tectonic 集群可以扩展到艾字节规模,使得单个集群可以覆盖整个数据中心。Tectonic 集群的多艾字节容量使得在同一个集群上托管多个大型租户(如 Blob 存储和数据仓库)成为可能,每个租户反过来又支持数百个应用程序。作为一个艾字节级的多租户文件系统,与基于联邦的存储架构 [8, 17](其由较小的 PB 级集群组装而成)相比,Tectonic 提供了运维简便性和资源效率。
Tectonic 简化了运维,因为它是一个单一系统,可用于开发、优化和管理多样化的存储需求。它具有资源效率,因为它允许集群内所有租户之间共享资源。例如,Haystack 是专为新 Blob 设计的存储系统;它受限于硬盘每秒 IO 操作数(IOPS),但拥有富余的磁盘容量。f4 存储较旧的 Blob,受限于磁盘容量,但拥有富余的 IO 能力。通过整合和资源共享,Tectonic 需要更少的磁盘来支持相同的工作负载。
在构建 Tectonic 时,我们面临三个高层次挑战:扩展到艾字节规模、在租户之间提供性能隔离,以及支持租户特定的优化。艾字节级集群对于运维简便性和资源共享至关重要。性能隔离和租户特定优化则帮助 Tectonic 达到专用存储系统的性能水平。
为了扩展元数据,Tectonic 将文件系统元数据解耦为可独立扩展的层,类似于 ADLS [42]。与 ADLS 不同,Tectonic 对每个元数据层进行哈希分区(hash-partition),而不是使用范围分区(range partitioning)。哈希分区有效避免了元数据层的热点。结合 Tectonic 高度可扩展的数据块(chunk)存储层,解耦的元数据使 Tectonic 能够扩展到艾字节存储和数十亿文件。
Tectonic 通过为每个租户内具有相似流量模式和延迟要求的应用程序组解决隔离问题,从而简化了性能隔离。Tectonic 不是在数百个应用程序之间管理资源,而只在数十个流量组之间管理资源。
Tectonic 使用租户特定的优化来匹配专用存储系统的性能。这些优化通过客户端驱动的微服务架构实现,该架构包含一套丰富的客户端配置,用于控制租户如何与 Tectonic 交互。例如,数据仓库使用 Reed-Solomon (RS) 编码写入,以提高其大型写入的空间、IO 和网络效率。相比之下,Blob 存储使用复制的仲裁追加协议来最小化其小型写入的延迟,并在之后对它们进行 RS 编码以实现空间效率。
Tectonic 已在单租户集群中托管 Blob 存储和数据仓库数年,完全取代了 Haystack、f4 和 HDFS。多租户集群正在有计划地推出,以确保可靠性并避免性能回归。
采用 Tectonic 带来了许多运维和效率上的改进。将数据仓库从 HDFS 迁移到 Tectonic 使数据仓库集群数量减少了 10 倍,通过管理更少的集群简化了运维。将 Blob 存储和数据仓库整合到多租户集群中,帮助数据仓库利用 Blob 存储的富余 IO 能力来处理流量高峰。在提供与之前专用存储系统相当或更好性能的同时,Tectonic 实现了这些效率提升。
2 Facebook 之前的存储基础设施
在 Tectonic 之前,每个主要存储租户将其数据存储在一个或多个专用的存储系统中。我们在此重点关注两个大型租户:Blob 存储和数据仓库。我们讨论每个租户的性能需求、它们之前的存储系统以及为什么这些系统效率低下。
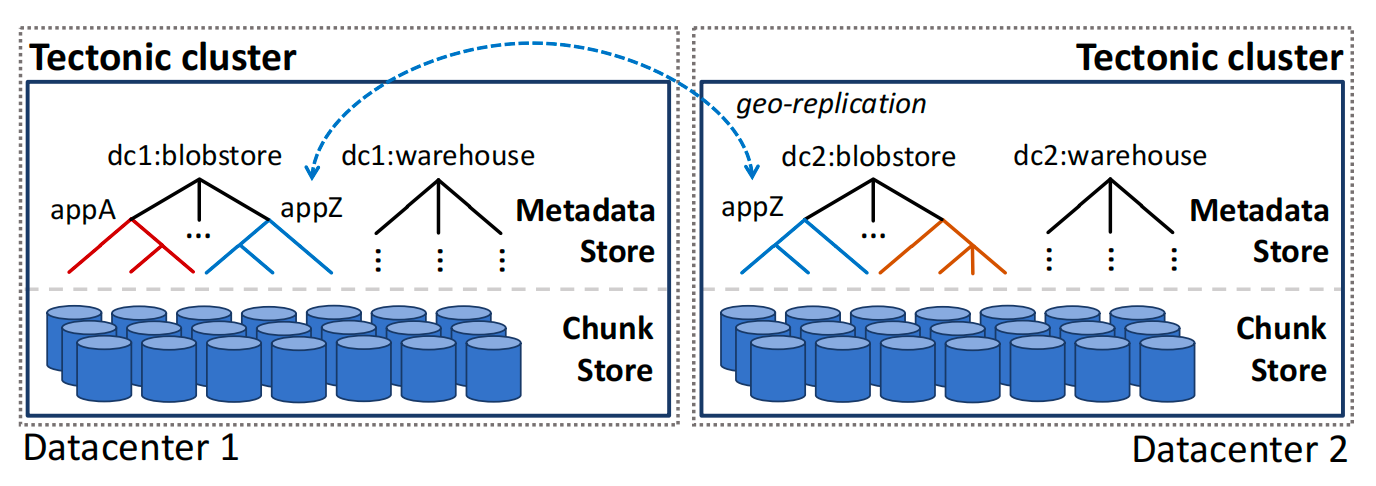
图 1:Tectonic 在数据中心内提供持久、容错的存储。每个租户拥有一个或多个独立的名称空间。租户实现跨地域复制(geo-replication)。
2.1 Blob 存储
Blob 存储用于存储并提供二进制大对象(BLOB)服务。这些对象可能来自 Facebook 应用程序的多媒体(照片、视频或消息附件),也可能来自内部应用程序的数据(核心转储、错误报告)。Blob 是不可变的(immutable)且不透明的(opaque)。它们的大小从几 KB 的小照片到几 MB 的高清视频片段不等 [34]。Blob 存储期望低延迟的读写,因为 Blob 通常是 Facebook 交互式应用程序的关键路径 [29]。
Haystack 和 f4。 在 Tectonic 之前,Blob 存储由两个专用系统组成:Haystack 和 f4。Haystack 处理访问频率高的“热” Blob [11]。它以复制形式存储数据,以实现持久性和快速读写。当 Haystack 中的 Blob 变旧且访问频率降低时,它们会被移动到“温” Blob 存储 f4 [34]。f4 以 RS 编码形式 [43] 存储数据,这种方式空间效率更高,但吞吐量较低,因为每个 Blob 只能直接从两个磁盘访问(而 Haystack 是三个)。f4 较低的吞吐量因其较低的请求率而被接受。
然而,将热 Blob 和温 Blob 分离导致了资源利用率低下,这个问题因硬件和 Blob 存储使用趋势而加剧。Haystack 理想的有效复制因子是 3.6 倍(即每个逻辑字节复制 3 份,加上 RAID-6 存储 [19] 带来的额外 1.2 倍开销)。但是,随着硬盘密度增加而每块硬盘的 IOPS 保持稳定,每 TB 存储容量的 IOPS 随时间推移而下降。
结果,Haystack 变得受 IOPS 限制;必须额外配置硬盘来处理热 Blob 的高 IOPS 负载。富余的磁盘容量导致 Haystack 的有效复制因子增加到 5.3 倍。相比之下,f4 的有效复制因子为 2.8 倍(在两个不同的数据中心使用 RS(10,4) 编码)。此外,Blob 存储转向了更短暂的多媒体,这些多媒体虽曾存储在 Haystack 中,但在移动到 f4 之前已被删除。结果,总 Blob 数据中越来越大的比例以 Haystack 的高有效复制因子存储。
最后,由于 Haystack 和 f4 是独立的系统,每个系统都束缚了无法与其他系统共享的资源。Haystack 过度配置存储以容纳峰值 IOPS,而 f4 则因存储大量访问频率较低的数据而拥有丰富的 IOPS。将 Blob 存储迁移到 Tectonic 回收了这些被束缚的资源,并实现了约 2.8 倍的有效复制因子。
2.2 数据仓库
数据仓库为数据分析提供存储。数据仓库应用程序存储诸如海量 Map-Reduce 表、社交图谱快照、AI 训练数据和模型等对象。包括 Presto [3]、Spark [10] 和 AI 训练流水线 [4] 在内的多个计算引擎访问这些数据,处理它们并存储派生数据。仓库数据被划分为数据集,用于存储不同产品组(如搜索、信息流、广告)的相关数据。
数据仓库存储优先考虑读写吞吐量而非延迟,因为数据仓库应用程序通常批量处理数据。数据仓库工作负载的读写操作通常比 Blob 存储更大,读取平均几 MB,写入平均几十 MB。
HDFS 用于数据仓库存储。 在 Tectonic 之前,数据仓库使用 Hadoop 分布式文件系统(HDFS)[15, 50]。然而,HDFS 集群规模有限,因为它使用单台机器存储和提供元数据。因此,我们每个数据中心需要数十个 HDFS 集群来存储分析数据。这在运维上效率低下;每个服务都必须了解数据在集群间的放置和移动。单个数据仓库数据集通常大到足以超过单个 HDFS 集群的容量。这使计算引擎逻辑复杂化,因为相关数据通常被分割在单独的集群中。
最后,将数据集分布在 HDFS 集群中产生了一个二维装箱问题。将数据集打包进集群必须遵守每个集群的容量约束和可用吞吐量。Tectonic 的艾字节规模消除了装箱和数据集分割问题。
3 架构与实现
本节描述 Tectonic 的架构和实现,重点关注 Tectonic 如何通过其可扩展的数据块和元数据存储实现艾字节级的单集群。
3.1 Tectonic:概览
集群是 Tectonic 的最高层部署单元。Tectonic 集群是数据中心本地的,提供持久存储,并能抵御主机、机架和电源域故障。租户可以在 Tectonic 之上构建跨地域复制以防范数据中心故障(图 1)。
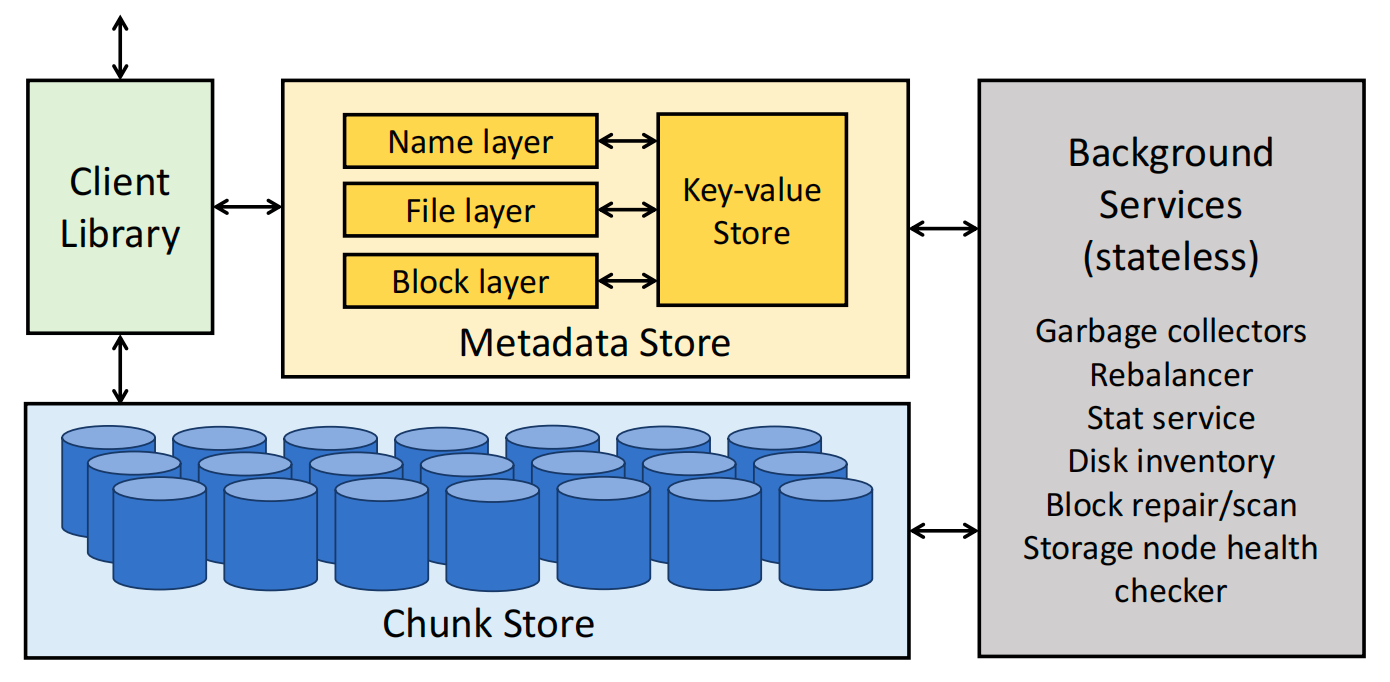
图 2:Tectonic 架构。箭头表示网络调用。Tectonic 在键值存储中存储文件系统元数据。除数据块存储和元数据存储外,所有组件都是无状态的。
一个 Tectonic 集群由存储节点(storage nodes)、元数据节点(metadata nodes)以及用于后台操作的无状态节点组成。客户端库协调对元数据和存储节点的远程过程调用(RPC)。Tectonic 集群可以非常庞大:单个集群可以满足单个数据中心内所有租户的存储需求。
Tectonic 集群是 多租户 的,在同一个存储架构上支持大约十个租户(§4)。租户是分布式系统,彼此之间永远不会共享数据;租户包括 Blob 存储和数据仓库。这些租户反过来服务于数百个 应用程序 ,包括信息流(Newsfeed)、搜索(Search)、广告(Ads)和内部服务,每个应用程序都有不同的流量模式和性能要求。
Tectonic 集群在相同的存储和元数据组件上支持任意数量、任意大小的 名称空间 ,即文件系统目录层次结构。集群中的每个租户通常拥有一个名称空间。名称空间的大小仅受集群大小的限制。
应用程序通过具有仅追加语义的分层文件系统 API 与 Tectonic 交互,类似于 HDFS [15]。与 HDFS 不同,Tectonic API 在运行时是可配置的,而不是在集群或租户级别预先配置。Tectonic 租户利用这种灵活性来匹配专用存储系统的性能(§4)。
Tectonic 组件。 图 2 显示了 Tectonic 的主要组件。Tectonic 集群的基础是数据块存储(§3.2),这是一组在硬盘上存储和访问数据块的存储节点。
在数据块存储之上是 元数据存储 (§3.3),它由一个可扩展的键值存储和无状态的元数据服务组成,这些服务在键值存储之上构建文件系统逻辑。它们的可扩展性使 Tectonic 能够存储艾字节的数据。
Tectonic 是一个客户端驱动的、基于微服务的系统,这种设计支持租户特定的优化。数据块存储和元数据存储各自运行独立的服务来处理数据和元数据的读写请求。这些服务由 客户端库 (§3.4)协调;该库将客户端的文件系统 API 调用转换为对数据块和元数据存储服务的 RPC。
最后,每个集群运行无状态的后台服务以维护集群的一致性和容错性(§3.5)。
3.2 数据块存储:艾字节级存储
数据块存储(Chunk Store)是一个用于数据块(chunk)的扁平、分布式对象存储,数据块是 Tectonic 中的数据存储单元。数据块构成块(blocks),块又构成 Tectonic 文件。
数据块存储有两个特性有助于 Tectonic 的可扩展性和支持多租户的能力。首先,数据块存储是扁平的(flat);存储的数据块数量随着存储节点数量线性增长。因此,数据块存储可以扩展到存储艾字节的数据。其次,它对更高层次的抽象(如块或文件)是无感知的(oblivious);这些抽象由客户端库使用元数据存储构建。将数据存储与文件系统抽象分离,简化了在一个存储集群上为多样化租户提供良好性能的问题(§5)。这种分离意味着对存储节点的读写操作可以针对租户的性能需求进行专门优化,而无需更改文件系统管理。
高效存储数据块。 单个数据块作为文件存储在集群的存储节点上,每个节点运行一个 XFS [26] 的本地实例。存储节点暴露核心 IO API 来获取(get)、放置(put)、追加(append)和删除(delete)数据块,以及列出(list)和扫描(scan)数据块的 API。存储节点负责确保其本地资源在 Tectonic 租户之间公平共享(§4)。
每个存储节点有 36 个硬盘用于存储数据块 [5]。每个节点还有一个 1TB SSD,用于存储 XFS 元数据和缓存热数据块。存储节点运行一个将本地 XFS 元数据存储在闪存上的 XFS 版本 [47]。这对于 Blob 存储特别有帮助,因为新的 Blob 是作为追加写入的,这会更新数据块大小。SSD 热数据块缓存由一个闪存耐久性感知的缓存库管理 [13]。
块作为持久存储单元。 在 Tectonic 中,块是一个逻辑单元,向上层隐藏了原始数据存储和持久性的复杂性。在上层看来,块是一个字节数组。实际上,块由数据块构成,这些数据块共同提供块的持久性。
Tectonic 提供按块的持久性,允许租户调整存储容量、容错性和性能之间的权衡。块使用 Reed-Solomon(RS)编码 [43] 或复制来实现持久性。对于 RS(r,k) 编码,块数据被分割成 r 个相等的数据块(可能通过填充数据),并从数据块生成 k 个奇偶校验数据块(parity chunks)。对于复制,数据块与块大小相同,并创建多个副本。一个块中的数据块存储在不同的故障域(例如,不同的机架)中以实现容错。后台服务修复损坏或丢失的数据块以维持持久性(§3.5)。
3.3 元数据存储:命名艾字节数据
Tectonic 的元数据存储(Metadata Store)存储文件系统层次结构以及块到数据块的映射。为了操作简便性和可扩展性,元数据存储对文件系统元数据进行细粒度分区。文件系统元数据首先被 解耦 ,意味着名称(naming)、文件(file)和块(block)层在逻辑上是分离的。然后每一层再进行哈希分区(表 1)。正如我们在本节所述,可扩展性和负载均衡在这种设计中是自然获得的。通过对元数据操作的精心处理,尽管元数据分区很细粒度,文件系统的一致性得以保留。
| 层 (Layer) | 键 (Key) | 值 (Value) | 共享依据 (Shared by) | 映射 (Mapping) |
|---|---|---|---|---|
| Name | (dir_id, subdirname) (dir_id, filename) |
subdir_info, subdir_id file_info, file_id |
dir_id dir_id |
dir → list of subdirs (expanded) dir → list of files (expanded) |
| File | (file_id, blk_id) | blk_info | file_id | file → list of blocks (expanded) |
| Block | blk_id (disk_id, blk_id) |
list<disk_id> chunk_info |
blk_id blk_id |
block → list of disks (i.e., chunks) disk → list of blocks (expanded) |
表 1:Tectonic 的分层元数据模式。目录名(dirname)和文件名(filename)是应用程序暴露的字符串。dir_id、file_id 和 block_id 是内部对象引用。大多数映射是展开的,以便高效更新。
将元数据存储在键值存储中,实现可扩展性和操作简便性。 Tectonic 将文件系统元数据存储委托给 ZippyDB [6] —— 一个具有线性一致性、容错性的分片键值存储。键值存储以分片粒度管理数据:所有操作都限定在一个分片内,分片是复制的单元。键值存储节点内部运行 RocksDB [23] —— 一个基于 SSD 的单节点键值存储,用于存储分片副本。分片使用 Paxos [30] 进行复制以实现容错。任何副本都可以服务读取请求,但必须由主副本提供强一致的读取服务。键值存储不提供跨分片事务,这限制了某些文件系统元数据操作。
分片的大小被设定,每个元数据节点可以托管多个分片。这允许在节点故障时并行地将分片重新分配到新节点,从而减少恢复时间。它还允许细粒度的负载均衡;键值存储会透明地移动分片以控制每个节点上的负载。
文件系统元数据层。 表 1 显示了文件系统元数据层、它们映射的内容以及如何分片。名称层(Name layer)将每个目录映射到其子目录和/或文件。文件层(File layer)将文件对象映射到块列表。块层(Block layer)将每个块映射到磁盘(即数据块)位置列表。块层还包含磁盘到块(即记录某磁盘存储了哪些块的数据块)的反向索引,用于维护操作。名称层、文件层和块层分别按目录 ID、文件 ID 和块 ID 进行哈希分区。
如表 1 所示,名称层和文件层以及磁盘到块列表的映射是 展开 的。映射到列表的键通过以下方式展开:将列表中每个条目存储为独立键,并添加原键作为前缀。例如,如果目录 d1 包含文件 foo 和 bar,我们在 d1 的名称层分片(Name shard)中存储两个键 (d1, foo) 和 (d1, bar)。展开机制允许修改键的内容,而无需先读取整个列表再重新写入。在映射可能非常庞大的文件系统中(例如,目录可能包含数百万文件),展开机制显著减少了某些元数据操作(如文件创建和删除)的开销。展开键的内容通过键前缀扫描列出。
细粒度元数据分区以避免热点。 在文件系统中,目录操作经常在元数据存储中引起热点。这对数据仓库工作负载尤为明显:其相关数据按目录分组存储;短时间内可能密集读取同一目录下的多个文件,从而引发对目录的重复访问。
Tectonic 的分层元数据方法通过将搜索和列出目录内容(名称层)与读取文件数据(文件和块层)分离开来,自然地避免了目录和其他层的热点。这与 ADLS 分离元数据层的方法类似 [42]。然而,ADLS 使用范围分区元数据层,而 Tectonic 使用哈希分区(元数据)层。范围分区倾向于将相关数据(例如目录层次结构的子树)放在同一个分片上,如果不仔细分片,元数据层容易产生热点。
我们发现哈希分区能有效地负载均衡元数据操作。例如,在名称层,单个目录的直接目录列表始终存储在一个分片中。但同一目录的两个子目录的列表很可能位于不同的分片上。在块层,块定位信息被哈希到各个分片,与块的目录或文件无关。Tectonic 中大约三分之二的元数据操作由块层处理,但哈希分区确保此流量在块层分片之间均匀分布。
缓存已封存(sealed)对象元数据以减少读取负载。 元数据分片的可用吞吐量有限,因此为了减少读取负载,Tectonic 允许块、文件和目录被 封存 。目录封存不递归应用,它只阻止在目录的直接层级添加对象。已封存的文件系统对象的内容无法更改;它们的元数据可以在元数据节点和客户端缓存而不会影响一致性。例外是块到数据块的映射;数据块可以在磁盘之间迁移,使块层缓存失效。陈旧的块层缓存可以在读取期间检测到,从而触发缓存刷新。
提供一致的元数据操作。 Tectonic 依赖键值存储的强一致操作和分片内原子读 - 改 - 写事务来实现同目录内的强一致操作。更具体地说,Tectonic 保证数据操作(例如,追加、读取)、涉及单个对象的文件和目录操作(例如,创建、列表)以及源路径和目标路径位于同一个父目录下的移动操作具有写后读一致性。一个目录中的文件位于该目录的分片中(表 1),因此像文件创建、删除和在父目录内的移动等元数据操作是一致的。
键值存储不支持一致的跨分片事务,因此 Tectonic 提供非原子的跨目录移动操作。将目录移动到不同分片上的另一个父目录是一个两阶段过程。首先,我们从新的父目录创建一个链接(link),然后从之前的父目录删除该链接。被移动的目录保留一个指向其父目录的回溯指针(backpointer)以检测挂起的移动。这确保一次只有一个移动操作对一个目录是活动的。同样地,跨目录的文件移动通常需要复制文件内容,然后从源目录中删除原文件。复制步骤会创建一个新的文件对象,该对象直接关联源文件的底层数据块,从而避免实际的数据移动。
译者注:
阶段一:
1、检查回溯指针,如果
bp.state = stable,继续;如果bp.state = moving,说明已有挂起的 move,拒绝;
2、CAS 更新bp.state = moving, bp.parent_id=Parent2
3、在新父目录 Parent2 下创建新链接阶段二:
1、更新
bp.state = stable
2、删除旧父目录 Parent1 的链接崩溃恢复:
1、如果崩溃后
bp.state = moving,则检查 Parent2 是否已有新链接:
- 有 → 执行阶段二,收尾
- 无 → 回滚,CAS 更新
bp.state = stable, bp.parent_id = Parent1,保持在 Parent1
2、如果崩溃后bp.state = stable, bp.parent_id = Parent2,但 Parent1 链接还没删掉,则清理多余的旧链接
在没有跨分片事务的情况下,对同一文件进行的多分片元数据操作必须仔细实现以避免竞态条件。这种竞态条件的一个例子是:当目录 d 中名为 f1 的文件被重命名为 f2 时。同时,创建一个同名的新文件,其中创建操作会覆盖同名的现有文件。括号中列出了每个步骤的元数据层和分片查找键(shard(x))。
文件重命名操作包含以下步骤:
- R1: 获取 f1 的文件 ID fid(Name, shard(d))
- R2: 添加 f2 作为 fid 的拥有者(File, shard(fid))
- R3: 在一个原子事务中创建映射 f2 → fid 并删除 f1 → fid(Name, shard(d))
译者注:
为什么 R3 不涉及跨分片?
目录项 (filename → fileID) 映射都存放在 Name 层,并且分片的方式是按目录来分片,即
shard(d)。 也就是说,同一个目录d下的所有文件名映射(f1 → fid、f2 → fid等),都会被存在同一个 shard。所以可以在 一个分片内事务中完成这两个更新,而无需跨分片协调
文件覆盖创建流程包含以下步骤:
- C1: 创建新文件 ID fid_new(File, shard(fid_new))
- C2: 映射 f1 → fid_new;删除 f1 → fid(Name, shard(d))
交错执行事务中的步骤可能导致文件系统处于不一致状态。若步骤 C1 和 C2 在 R1 之后、R3 之前执行,则 R3 操作将擦除由创建操作生成的新映射。重命名步骤 R3 通过分片内事务确保 f1 指向的文件对象自 R1 步骤后未被修改。
译者注:
如果 R3 的 “删除 f1→fid”是不带条件的“删 key=f1”(或没有校验 value 仍是
fid),它会把 刚刚由 C2 建立的f1 → fid_new也一并删掉。于是出现违背语义的坏结局:
- Name:
f2 → fid(被写入了),**f1不存在**(被误删),- File:有
fid_new这个新文件,但 没有任何名字指向它(成为悬挂对象/垃圾),- 等价于把“覆盖创建”的结果给抹掉了——典型的 丢失更新(lost update)。
为什么会发生?
- R1 在 读到旧现实(
f1 → fid)后,并没有把该现实“锁住”。- C2 在 同一个 Name 分片内把现实改成了
f1 → fid_new。- R3 晚到了,如果它没有基于“R1 看到的版本”做校验,而是直接执行“创建
f2并删除f1”,就会错误地删除了 C2 的新映射。
3.4 客户端库
Tectonic 客户端库协调数据块和元数据存储服务,向应用程序暴露文件系统抽象,这使应用程序能够按操作控制如何配置读写。此外,客户端库在数据块粒度上执行读写操作,这是 Tectonic 中最精细的粒度。这使得客户端库几乎可以自由地以对应用程序最有效的方式执行操作,这些应用程序可能有不同的工作负载或偏好不同的权衡(§5)。
客户端库复制或 RS 编码数据,并将数据块直接写入数据块存储。它为应用程序从数据块存储读取并重建数据块。客户端库查询元数据存储以定位数据块,并为文件系统操作更新元数据存储。
单写入者语义实现简单、可优化的写入。 Tectonic 通过允许每个文件只有一个写入者来简化客户端库的协调。单写入者语义避免了从多个写入者序列化对文件写入的复杂性。客户端库可以改为并行地直接写入存储节点,允许它并行复制数据块并进行对冲写入(§5)。需要多写入者语义的租户可以在 Tectonic 之上构建序列化语义。
Tectonic 通过为每个文件设置一个写入令牌(write token)来强制执行单写入者语义。每当写入者想要向文件添加一个块时,它必须包含一个匹配的令牌才能使元数据写入成功。当一个进程打开文件进行追加时,令牌被添加到文件元数据中,后续写入必须包含此令牌才能更新文件元数据。如果第二个进程尝试打开该文件,它将生成一个新令牌并覆盖第一个进程的令牌,成为该文件新的、也是唯一的写入者。新写入者的客户端库将在打开文件调用中封存前一个写入者打开的任何块。
3.5 后台服务
后台服务维护元数据层之间的一致性,通过修复丢失的数据来维持持久性,在存储节点之间重新均衡数据,处理机架下线,并发布有关文件系统使用情况的统计信息。后台服务分层类似于元数据存储,并且它们一次操作一个分片。图 2 列出了重要的后台服务。
每个元数据层之间的垃圾收集服务(garbage collector)清理(可接受的)元数据不一致性。元数据不一致可能源于失败的多步骤客户端库操作。惰性对象删除是一种实时延迟优化,它在删除时标记已删除对象而不实际移除它们,也会导致不一致。
再均衡服务(rebalancer)和修复服务(repair service)协同工作来重新定位或删除数据块。再均衡器识别需要移动的数据块以响应硬件故障、增加存储容量和机架下线等事件。修复服务通过为系统中的每个磁盘协调数据块列表与磁盘到块的映射来处理实际的数据移动。为了水平扩展,修复服务在块层分片、单磁盘维度工作,该机制依托磁盘到块的反向索引映射实现(表 1)。
大规模下的副本集。 副本集是为同一个块提供冗余的磁盘组合(例如,一个 RS(10,4) 编码块的副本集由 14 个磁盘组成)[20]。副本集过多会在磁盘故障意外激增时带来数据不可用的风险。另一方面,副本集过少会导致当一个磁盘故障时,对等磁盘的重建负载很高,因为它们共享许多数据块。
块层和再均衡器服务共同尝试维持一个固定的副本集数量,以平衡不可用性和重建负载。它们各自在内存中保留大约一百份集群磁盘的确定性分布拓扑。块层在同一分布拓扑中选取连续磁盘形成副本组。执行写入操作时,块层根据块 ID 的对应分布拓扑,向客户端库提供目标副本组。再均衡服务则致力于将数据块的分片保留在其分布拓扑指定的副本组中。需注意的是,副本组机制采用尽力而为原则,因为集群中的磁盘成员持续动态变化。
4 多租户
在租户从单独的、专用的存储系统迁移到整合的文件系统时,为其提供可比的性能面临两个挑战。首先,租户必须共享资源,同时为每个租户提供其公平份额,即至少与其在单租户系统中相同的资源。其次,租户应该能够像在专用系统中一样优化性能。本节描述 Tectonic 如何通过保持操作简便性的简洁设计来支持资源共享。第 5 节描述 Tectonic 的租户特定优化如何使租户获得与专用存储系统相当的性能。
4.1 有效共享资源
作为 Facebook 上多样化租户的共享文件系统,Tectonic 需要有效地管理资源。具体来说,Tectonic 需要在租户之间提供近似(加权)公平的资源共享和租户之间的性能隔离,同时在应用程序之间弹性地转移资源以维持高资源利用率。Tectonic 还需要区分延迟敏感的请求,以避免它们被大型请求阻塞。
资源类型。 Tectonic 区分两种类型的资源:非临时性(non-ephemeral)和临时性(ephemeral)。存储容量是 非临时性 资源。它变化缓慢且可预测。最重要的是,一旦分配给租户,就不能再给另一个租户。存储容量在租户粒度上进行管理。每个租户获得预定义的容量配额,具有严格的隔离性,即分配给不同租户的空间没有自动弹性。租户之间的存储容量重新配置是手动完成的。重新配置不会导致停机,因此在紧急容量紧张的情况下可以立即进行。租户负责在其应用程序之间分配和跟踪存储容量。
临时性 资源是指需求会瞬息变化、并且其分配能够实时调整的资源。存储 IOPS 容量和元数据查询容量是两种临时性资源。由于临时性资源需求变化迅速,这些资源需要更细粒度的实时自动化管理,以确保它们被公平共享、租户彼此隔离,并且资源利用率高。在本节的剩余部分,我们将描述 Tectonic 如何有效地共享临时性资源。
在租户内部和租户之间分配临时性资源。 临时性资源共享在 Tectonic 中具有挑战性,因为不仅租户是多样化的,而且每个租户服务于许多具有不同流量模式和性能要求的应用程序。例如,Blob 存储包括来自 Facebook 用户的生产流量和后台垃圾回收流量。在租户粒度管理临时性资源过于粗糙,无法考虑租户内多样化的工作负载和性能要求。另一方面,由于 Tectonic 服务于数百个应用程序,在应用程序粒度管理资源过于复杂且消耗大量资源。
因此,临时性资源在每个租户内部以应用程序组的粒度进行管理。这些应用程序组称为 流量组(TrafficGroups) ,减少了资源共享问题的基数,降低了管理多租户的开销。同一流量组中的应用程序具有相似的资源和延迟要求。例如,一个流量组可能用于生成后台流量的应用程序,而另一个用于生成生产流量的应用程序。Tectonic 每个集群支持大约 50 个流量组。每个租户可能有不同数量的流量组。租户负责为其每个应用程序选择合适的流量组。每个流量组又被分配一个 流量等级(TrafficClass) 。流量组的流量等级指示其延迟要求,并决定哪些请求应获得富余资源。流量等级分为黄金(Gold)、白银(Silver)和青铜(Bronze),分别对应延迟敏感、正常和后台应用程序。富余资源根据流量等级优先级在租户内分配。
Tectonic 使用租户和流量组以及流量等级的概念来确保隔离性和高资源利用率。也就是说,租户被分配其公平份额的资源;在每个租户内部,资源按流量组和流量等级分配。每个租户获得集群临时性资源的保证配额,该配额在其租户的流量组之间细分。每个流量组获得其保证的资源配额,这提供了租户之间以及流量组之间的隔离。
租户内部的任何临时性资源富余按其流量等级降序优先分配给其自身的流量组。任何剩余的富余按流量等级降序分配给其他租户的流量组。这确保了富余资源首先由同一租户的流量组使用,然后再分配给其他租户。当一个流量组使用另一个流量组的资源时,由此产生的流量获得两个流量组中较低的流量等级。这确保了不同等级的流量比例不会基于资源分配而改变,从而确保节点能够满足流量等级的延迟特性。
强制执行全局资源共享。 客户端库使用速率限制器(rate limiter)来实现上述弹性。速率限制器使用高性能、近实时的分布式计数器来跟踪每个租户和流量组在过去小时间窗口内对每个被跟踪资源的需求。速率限制器实现了一个改进的漏桶算法。传入的请求增加桶的需求计数器。然后,客户端库在自己的流量组、同一租户的其他流量组以及最后其他租户中检查富余容量,遵守流量等级优先级。如果客户端找到富余容量,请求被发送到后端。否则,根据请求的超时设置,请求被延迟或拒绝。在客户端节流请求,可以在客户端发出可能被浪费的请求之前施加反压。
强制执行本地资源共享。 客户端的速率限制器确保近似的全局公平共享和隔离。元数据和存储节点也需要管理资源以避免本地热点。节点通过加权轮询调度器提供公平共享和隔离,如果一个流量组将要超过其资源配额,则临时跳过其轮次。此外,存储节点需要确保小型 IO 请求(例如,Blob 存储操作)不会因为与大型、突发的 IO 请求(例如,数据仓库操作)共置而遭遇更高的延迟。黄金流量等级请求若在存储节点上被阻塞在较低优先级请求之后,则可能无法达到其延迟目标。
存储节点使用三种优化来确保黄金流量等级请求的低延迟。首先,WRR 调度器提供一种贪婪优化策略,在让位给较高流量类别的请求后仍有足够时间完成自身操作时,系统会允许其主动让位。这一机制可避免高等级请求被低等级请求阻塞。其次,我们对每块磁盘并发处理的非黄金级 IO 请求数量实施限制。当存在挂起的黄金级请求且非黄金级请求并发数已达上限时,系统将阻止新的非黄金流量请求开始调度。这确保磁盘不会在仍有 Blob 存储请求等待时,持续处理大型数据仓库 IO 操作。最后,针对磁盘自身可能重新排列 IO 请求序列(例如优先处理后续的非黄金级请求而搁置先到的黄金级请求)的情况,当某磁盘上的黄金级请求等待时间超过设定阈值时,Tectonic 会停止向该磁盘调度非黄金级请求。三项技术协同作用,即使面对大规模大型 IO 请求的场景,也能有效维持小型 IO 请求的延迟特征。
4.2 多租户访问控制
Tectonic 遵循常见的安全原则,确保所有通信和依赖项都是安全的。Tectonic 还提供租户之间的粗粒度访问控制(防止一个租户访问另一个租户的数据)和租户内部的细粒度访问控制。由于客户端库直接与每一层通信,必须在 Tectonic 的每一层强制执行访问控制。由于访问控制位于每次读取和写入的关键路径上,因此它必须是轻量级的。
Tectonic 使用基于令牌的授权机制,该机制包含可以使用令牌访问哪些资源的信息 [31]。授权服务(authorization service)授权顶级客户端请求(例如,打开文件),为文件系统中的下一层生成授权令牌;后续每一层同样授权下一层。令牌的有效负载描述了授予访问权限的资源,从而实现细粒度的访问控制。每一层完全在内存中验证令牌和有效负载中指示的资源;验证可以在几十微秒内完成。将令牌传递搭载在现有协议上减少了访问控制的开销。
5 租户特定优化
Tectonic 在同一个共享文件系统中支持大约十个租户,每个租户都有特定的性能需求和工作负载特征。两种机制允许租户特定的优化。首先,客户端几乎完全控制如何配置应用程序与 Tectonic 的交互;客户端库在数据块级别操作数据,这是可能的最精细粒度(§3.4)。这种客户端库驱动的设计使 Tectonic 能够根据应用程序的性能需求执行操作。
其次,客户端在每次调用时强制执行配置。许多其他文件系统将配置固化在系统中,或应用于整个文件或名称空间。例如,HDFS 按目录配置持久性 [7],而 Tectonic 按块写入配置持久性。每次调用的配置得益于元数据存储的可扩展性:元数据存储可以轻松处理这种方法增加的元数据。接下来我们描述数据仓库和 Blob 存储如何利用每次调用的配置实现高效写入。
5.1 数据仓库写入优化
数据仓库工作负载的一个常见模式是写入一次数据,稍后会被多次读取。对于这些工作负载,文件只有在创建者关闭文件后才对读者可见。然后文件在其生命周期内是不可变的。由于文件只有在完全写入后才被读取,应用程序优先考虑较低的文件写入时间而非较低的追加延迟。
全块、RS 编码的异步写入,提高空间、IO 和网络效率。 Tectonic 利用一次写入多次读取模式来提高 IO 和网络效率,同时最小化总文件写入时间。这种模式中不存在部分文件读取,允许应用程序将写入缓冲达到块大小。应用程序然后在内存中对块进行 RS 编码,并将数据块写入存储节点。长期数据通常使用 RS(9,6) 编码;短期数据,例如 Map-Reduce 洗牌(shuffles),通常使用 RS(3,3) 编码。
写入 RS 编码的全块比复制节省存储空间、网络带宽和磁盘 IO。存储和带宽更低,因为写入的总数据量更少。磁盘 IO 更低,因为磁盘使用更高效。在 RS(9,6) 中写入块需要向 15 个磁盘写入数据块,因此需要更多的 IOPS,但每次写入都很小,并且写入的数据总量远小于复制。这导致磁盘 IO 更高效,因为块大小足够大,使得全块写入的瓶颈是磁盘带宽而非 IOPS。
一次写入多次读取模式还允许应用程序异步并行写入文件的块,这显著减少了文件写入延迟。一旦文件的块被写入,文件元数据会一次性更新。这种策略没有不一致的风险,因为文件只有在完全写入后才可见。
对冲仲裁组写入改善尾部延迟。 对于全块写入,Tectonic 使用一种仲裁组写入的变体,该变体在不增加额外 IO 的情况下减少尾部延迟。Tectonic 不是将数据块写入负载发送到额外的节点,而是首先发送预留请求,然后将数据块写入最先接受预留的节点。预留步骤类似于对冲策略 [22],但其避免了向以下两类节点传输数据:因资源不足无法接收请求的节点,或请求者已超出在该节点资源份额的节点(§4)。
译者注:
“对冲”概念来源于金融领域,即通过投资多种资产来降低风险。在计算机系统中,“对冲”的基本思想是:为了降低延迟和避免个别节点性能不佳的影响,客户端主动将同一个请求同时发送给多个服务器(或副本),然后采用最先返回的那个结果,并取消其他未完成的请求。
这是一种 用额外的资源(网络带宽、服务器计算资源)来换取更低延迟和更高可靠性 的策略。
例如,要写入一个 RS(9,6) 编码的块,客户端库向不同故障域中的 19 个存储节点发送预留请求,比写入所需多 4 个。客户端库将数据和奇偶校验块写入最先响应的 15 个存储节点。一旦 15 个节点中有 14 个(即仲裁数)返回成功,它就向客户端确认写入成功。如果第 15 个写入失败,相应的数据块将在离线时修复。
当集群负载很高时,对冲步骤更有效。图 3a 显示,在一个吞吐量利用率为 80% 的测试集群中,RS(9,6) 编码的 72MB 全块写入的 99 分位延迟(99th percentile latency)提高了约 20%。
5.2 Blob 存储优化
Blob 存储对文件系统具有挑战性,因为需要索引的对象数量巨大。Facebook 存储数万亿个 Blob。Tectonic 通过将许多 Blob 一起存储到日志结构文件(log-structured files)中来管理 Blob 存储元数据的大小,其中新的 Blob 追加在文件末尾。Blob 通过一个从 Blob ID 到其在文件中位置的映射进行定位。
Blob 存储同样位于许多用户请求的关键路径上,因此需要实现低延迟访问。Blob 通常比 Tectonic 块小得多(§2.1)。因此,为实现低延迟,Blob 存储采用小的、复制的部分块追加写入的方式存储新的 Blob。部分块追加写入需要具有写后读一致性,以便 Blob 在上传成功后可以立即读取。但需要注意的是,复制的数据会比全块 RS 编码的数据使用更多的磁盘空间。
一致的部分块追加写入实现低延迟。 Tectonic 使用 部分块仲裁组追加写入 来实现持久、低延迟、一致的 Blob 写入。在仲裁组追加写入中,客户端库在存储节点子集成功将数据写入磁盘后确认写入,例如三副本复制中两个节点成功即可。由于块很快会被重新编码,且 Blob 存储会将第二个副本写入另一个数据中心,仲裁组写入导致的持久性短暂降低是可接受的。
部分块仲裁组追加写入的挑战在于,滞后的追加操作可能导致副本数据块出现大小不一致的情况。Tectonic 通过精细控制块追加权限以及可见时机来维护一致性。块只能由创建该块的写入者执行追加操作。当追加操作完成后,Tectonic 会先将追加后的块大小和校验和提交到块元数据,然后确认部分块仲裁组追加写入完成。
这种由单一追加者维持的操作顺序确保了一致性。如果块元数据报告块大小为 S,则该块此前所有字节均已被写入至少两个存储节点。读者能够访问该块中偏移量 S 之前的数据。同理,任何已向应用程序返回确认的写入操作,其元数据必然已完成更新,从而确保后续读取操作的可见性。图 3b 和 3c 表明 Tectonic 的 Blob 存储读写延迟与 Haystack 相当,验证了 Tectonic 的通用性没有显著的性能成本。
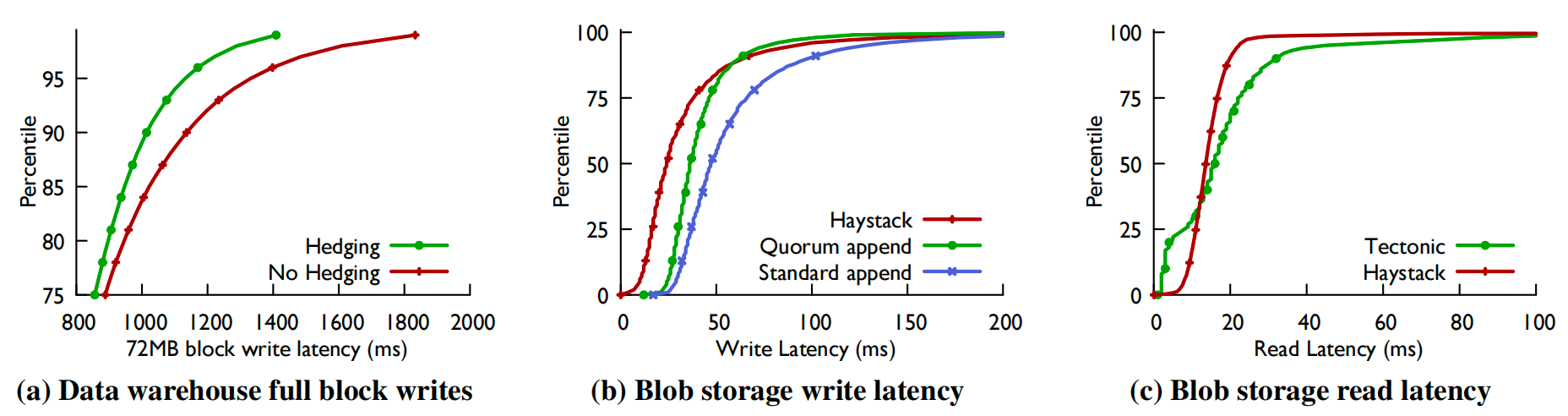
图 3:Tectonic 中的尾部延迟优化。(a) 显示了在负载约 80% 的测试集群中,对冲仲裁组写入(72MB 块)对数据仓库尾部延迟的改善。(b) 和 (c) 显示了 Tectonic Blob 存储的写入延迟(带和不带仲裁组追加写入)以及读取延迟与 Haystack 的比较。
重新编码块以提高存储效率。 直接对小的部分块追加写入进行 RS 编码会导致 IO 效率低下。小型磁盘写入受 IOPS 限制,而 RS 编码会产生更多的 IO 操作(例如,使用 RS(10,4) 需要 14 次 IO,而不是 3 次)。客户端库不是每次追加写入后都执行 RS 编码,而是在块封闭后一次性将副本形式的数据重新编码为 RS(10,4) 格式。与实时 RS 编码相比,重新编码是 IO 高效的,仅需在 14 个目标存储节点上各执行一次大容量 IO 操作。这种由 Tectonic 客户端库驱动设计实现的优化方案,成功融合了两方面优势:既通过快速高效的复制机制处理小型写入,又能及时转换为空间效率更优的 RS 编码格式。
6 Tectonic 在生产环境
本节展示 Tectonic 在艾字节规模下的运行情况,证明存储整合的效益,并讨论 Tectonic 如何处理元数据热点。它还讨论了设计 Tectonic 时的权衡和经验教训。
6.1 艾字节级多租户集群
生产环境的 Tectonic 集群在艾字节规模下运行。表 2 给出了一个代表性多租户集群的统计数据。本节的所有结果均针对此集群。1250PB 的已使用存储(约占集群当时容量的 70%)包含 107 亿个文件和 150 亿个块。
| 容量 | 已用字节 | 文件数 | 块数 | 存储节点 |
|---|---|---|---|---|
| 1590 PB | 1250 PB | 10.7 B | 15 B | 4208 |
表 2:多租户 Tectonic 生产集群的统计数据。文件和块数单位为十亿。
6.2 存储整合的效率提升
表 2 中的集群托管了两个租户:Blob 存储和数据仓库。Blob 存储约占该集群已用空间的 49%,数据仓库约占 51%。图 4a 和 4b 展示了该集群在三天内处理存储负载的情况。图 4a 显示了集群该时间段内的总 IOPS,图 4b 显示了其总磁盘带宽。数据仓库工作负载因超大规模作业触发而存在显著且规律的负载峰值。相比之下,Blob 存储的流量模式则呈现平滑且可预测的特性。
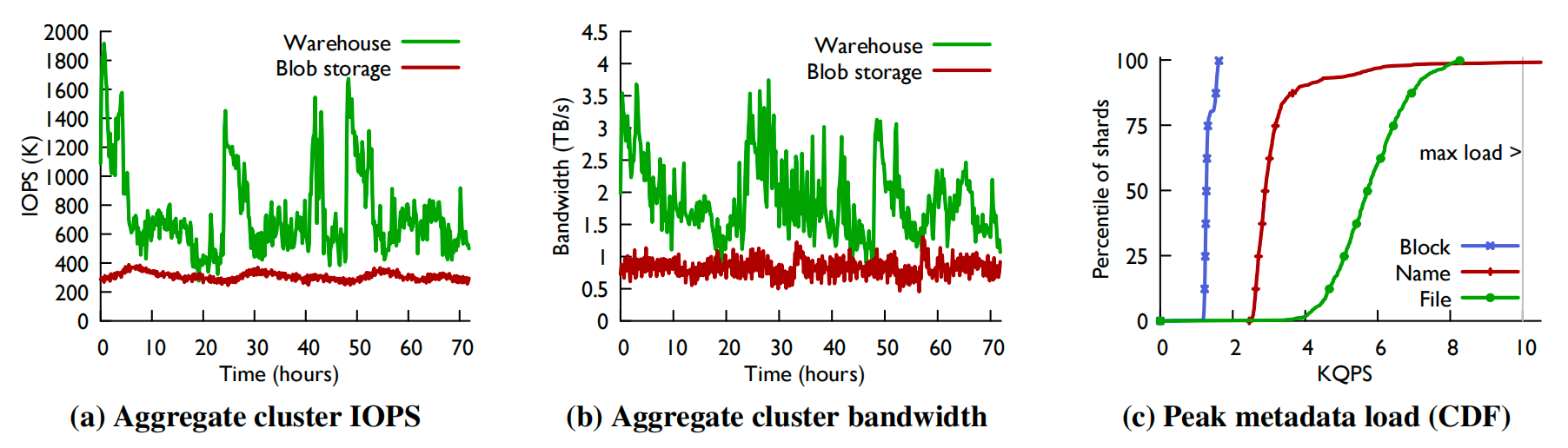
图 4:代表性生产集群在三天内的 IO 和元数据负载。(a) 和 (b) 显示了 Blob 存储和数据仓库流量模式的差异,并展示了 Tectonic 在 3 天内成功处理存储 IOPS 和带宽峰值的情况。两个租户在该集群中占据几乎相同的空间。(c) 是该集群元数据分片在三天内峰值元数据负载的累积分布函数(CDF)。每个分片能处理的最大负载是 10K QPS(灰线)。Tectonic 可以处理文件层和块层的所有元数据操作。它可以立即处理几乎所有的名称层操作;剩余的操作在重试时处理。
共享富余 IOPS 容量。 集群通过整合 Blob 存储所释放的富余 IOPS 容量,处理数据仓库产生的存储负载峰值。Blob 存储请求通常很小且受 IOPS 限制,而数据仓库请求通常很大且受带宽限制。因此,无论是 IOPS 还是带宽都不能公平地衡量磁盘 IO 使用情况。处理存储操作时的瓶颈资源是 磁盘时间(disk time) ,它衡量特定磁盘处于忙碌状态的频率。要处理存储负载峰值,Tectonic 必须具备足够的空闲磁盘时间来应对峰值。例如,若某磁盘在 1 秒内执行 10 次 IO 操作,每次耗时 50 毫秒(寻址 + 读取),则该磁盘在 1000 毫秒中有 500 毫秒处于忙碌状态。我们采用磁盘时间作为公平衡量不同类型请求资源占用的标准。
在该代表性生产集群中,表 3 显示了数据仓库和 Blob 存储在三个每日峰值期间的标准化磁盘时间需求,以及两者若独立运行时各自的磁盘时间供给量。我们按集群中已用空间对应的总磁盘时间进行标准化。每日峰值与图 4a 和 4b 中三个流量高峰日相对应。在所有三个峰值时段,数据仓库的需求都超过了其独立供给量,若独立运行则需要超额配置磁盘资源。为了满足三天期间的数据仓库峰值需求,集群需要约 17% 的磁盘超额配置。另一方面,Blob 存储拥有富余的磁盘时间,若独立运行这些资源将会闲置。将这两个租户整合到一个 Tectonic 集群中,使得 Blob 存储的富余磁盘时间得以有效利用,从而支撑数据仓库的存储负载峰值。
| 数据仓库 | Blob 存储 | 合计 | |
|---|---|---|---|
| 供给量 | 0.51 | 0.49 | 1.00 |
| 峰值 1 | 0.60 | 0.12 | 0.72 |
| 峰值 2 | 0.54 | 0.14 | 0.68 |
| 峰值 3 | 0.57 | 0.11 | 0.68 |
表 3:Tectonic 整合数据仓库和 Blob 存储,允许数据仓库利用原本被 Blob 存储闲置的富余磁盘时间来处理大型负载峰值。该图显示了在代表性集群的三个每日峰值期间,磁盘时间需求与供给量的标准化值。
6.3 元数据热点
元数据存储的负载峰值可能导致元数据分片出现热点。处理元数据操作的瓶颈资源是每秒查询数(QPS)。要应对负载峰值,元数据存储必须确保每个分片都能满足 QPS 需求。在生产环境中,每个分片最多可处理 10K QPS。该限制由当前元数据节点资源的隔离机制所设定。图 4c 显示了集群中元数据分片在名称层、文件层和块层的 QPS 分布情况,其中文件层与块层的所有分片均低于此限值。
在这三天期间,约 1% 的名称层分片因承载极高热度的目录而触及 QPS 上限。少量未处理的元数据请求会在退避延迟后自动重试。这种退避机制使元数据节点能清除大部分初始峰值流量,并成功处理重试请求。这种机制,加上所有其他分片都低于其最大值,使得 Tectonic 能够成功处理来自数据仓库的元数据负载的大幅峰值。
分片间的负载分布在名称层、文件层和块层之间存在差异。越高层级的分片间 QPS 分布差异越大,因为它会将租户的更多操作集中处理。例如,特定目录下所有目录到文件的查找操作都由同一个分片处理。若采用类似 ADLS [42] 的范围分区方案,则会将租户更多操作集中到同一分片,导致更剧烈的负载峰值。数据仓库作业经常读取多个名称相似的目录,若采用目录范围分区将引发极端负载峰值。这些作业同时会读取目录中的大量文件,从而在名称层引发负载激增。若对文件层实施范围分区,会将同一目录下的文件集中在相同分片,由于每个作业在文件层的操作量远超名称层,这将导致更严重的负载峰值。Tectonic 采用的哈希分区策略减少了这种集中性,使得系统能用比范围分区更少的节点处理元数据负载峰值。
Tectonic 还通过与数据仓库协同设计来减少元数据热点。例如,计算引擎通常采用编排器(orchestrator)列出目录中的文件并将文件分发给工作节点,由工作节点并行打开并处理这些文件。在 Tectonic 中,这种模式会向单个目录分片发送大量近乎同时到达的文件打开请求(§3.3),从而引发热点问题。为避免这种反模式,Tectonic 的 list-files API 在返回目录内文件名的同时会同步返回文件 ID。计算引擎协调器(orchestrator)将文件 ID 和名称发送给工作节点后,工作节点可直接通过文件 ID 打开文件,无需再次查询目录分片。
6.4 简便性与性能的权衡
Tectonic 的设计通常优先考虑简便性(simplicity)而非效率(efficiency)。我们讨论两个我们选择增加复杂性以换取性能提升的实例。
管理重建负载。 RS 编码的数据可以 连续 存储,即一个块被分割成数据块,每个数据块连续写入存储节点;也可以条带化存储,即一个数据块被分割成更小的数据块,以轮询方式分布在存储节点上 [51]。因为 Tectonic 使用连续 RS 编码,并且大多数读取小于一个数据块大小,所以通常是 直接 读取:无需 RS 重建,仅需单次磁盘 IO。重建读取所需的 IO 次数是直接读取的 10 倍(对于 RS(10,4) 编码)。虽然重建读取很常见,但难以预测其具体占比——硬件故障和节点过载都可能触发重建。我们认识到,若不加以控制,这种资源需求的剧烈波动可能引发级联故障,进而影响系统可用性与性能。
若某些存储节点过载,直接读取会失败并触发重建读取。这将增加系统其余部分的负载,进而引发更多重建读取,形成恶性循环。这种级联重建现象被称为 重建风暴 。一种简单的解决方案是采用条带式 RS 编码(所有读取都需要重建),这样可避免重建风暴,因为发生故障时读取所需的 IO 次数不会改变。但该方案会使正常情况下的读取操作成本大幅增加。我们通过将重建读取限制在总读取量的 10% 以内来预防重建风暴。这个重建比例通常足以应对生产集群中的磁盘、主机和机架故障。虽然需要付出一定的调优复杂度作为代价,但我们避免了磁盘资源的过度配置。
高效访问数据中心内及跨数据中心的数据。Tectonic 允许客户端直接访问存储节点;另一种替代方案可能使用前端代理来中介所有客户端对存储的访问。虽然向客户端开放客户端库会引入复杂性(因为库中的缺陷会转化为应用程序二进制文件中的缺陷),但直接客户端访问存储节点的网络和硬件资源效率远高于代理设计,可避免每秒数 TB 数据产生的额外网络跳数。
遗憾的是,直接访问存储节点的模式难以适配远程请求(即客户端与 Tectonic 集群地理距离较远的情况)。额外的网络开销会使协调往返通信的效率变得极其低下。为解决这个问题,Tectonic 对远程数据访问采用与本地数据访问不同的处理方式:远程请求会被转发至与存储节点处于同一数据中心的无状态代理。
6.5 权衡与妥协
迁移至 Tectonic 并非没有代价和妥协。本小节将阐述 Tectonic 在灵活性或性能上不如 Facebook 原有基础设施的若干领域,并分析采用哈希分区元数据存储带来的影响。
元数据延迟增加的影响。 迁移至 Tectonic 导致数据仓库应用程序面临更高的元数据延迟。HDFS 的元数据操作基于内存且单个节点存储整个名称空间的元数据,而 Tectonic 将元数据存储在分片式键值存储实例中,并采用分层元数据架构(§3.3)。这意味着 Tectonic 的元数据操作可能需要一次或多次网络调用(例如文件打开操作需与名称层和文件层交互)。鉴于元数据延迟的增加,数据仓库必须调整其对特定元数据操作的处理方式。例如,计算引擎在完成计算后需要按顺序逐个重命名文件集:在 HDFS 中每个重命名操作都很快,但在 Tectonic 中,计算引擎通过并行化此步骤来抵消单个重命名操作产生的额外延迟。
哈希分区元数据的应对方案。 由于 Tectonic 目录采用哈希分片机制,递归列出目录需要查询多个分片。实际上,Tectonic 不提供递归列表 API,租户需通过在客户端封装多次独立列表调用来实现该功能。因此与 HDFS 不同,Tectonic 无法提供 du(目录空间使用量查询)功能来获取目录的聚合空间使用情况。作为替代方案,Tectonic 会定期聚合每个目录的使用统计信息,这些数据可能存在滞后性。
6.6 设计与部署经验
实现高可扩展性是一个通过微服务架构实现的迭代过程。为满足日益增长的可扩展性需求,Tectonic 的多个组件经历了多次迭代升级。例如,数据块存储的最初版本采用块分组机制来减少元数据:将具有相同冗余方案的多个块分组,通过 RS 编码作为一个单元存储它们的数据块,每个块分组映射到一组存储节点。尽管这是显著减少元数据的常用技术 [37,53],但对于我们的生产环境而言过于僵化——当仅 5% 的存储节点不可用时,80% 的块分组会变得不可写入。该设计还阻碍了诸如对冲仲裁组写入和仲裁组追加等优化措施的实施(§5)。
此外,我们最初的元数据存储架构未分离名称层与文件层,客户端需要访问相同的分片来执行目录查找和文件块列表操作。这种设计因元数据热点导致服务不可用,促使我们进一步实施元数据分层。
Tectonic 的演进历程表明,尝试新设计对于逼近性能目标具有重要意义。我们的开发经验也证明了基于微服务的架构对实验的价值:我们可以对组件进行透明化迭代,而不会影响系统其他部分。
内存数据损坏在大规模系统中极为常见。以 Tectonic 的规模而言,每日有数千台机器读写海量数据,内存数据损坏已成为常规现象——其他大型系统也观测到此类现象 [12, 27]。我们通过强制实施进程内部及跨进程的校验和(checksum)检查来解决该问题。
对于数据 D 及其校验和 CD,若需执行内存转换 F 使得 D′ = F(D),则需为 D ′生成校验和 CD′。验证 D′ 时,必须通过 F 的逆向函数 G 将 D′ 转换回 D,并比对 CG(D′) 与 CD。虽然逆向函数 G 的计算成本可能很高(例如 RS 编码或加密的逆向运算),但为保障数据完整性,Tectonic 仍选择承担此开销。
所有涉及数据移动、复制或转换的 API 边界都必须进行改造以包含校验和信息。客户端写入时需随数据一并向客户端库传递校验和,且 Tectonic 不仅需要在跨进程边界(如客户端库与存储节点之间)传递校验和,还需在进程内部(如数据转换后)保持校验和传递。通过验证转换过程的完整性,可有效防止存储节点故障后数据损坏传播至重建的数据块。
6.7 不使用 Tectonic 的服务
Facebook 内部部分服务未采用 Tectonic 进行数据存储。引导服务(例如,必须保持零依赖的软件二进制包部署系统)无法使用 Tectonic,因为该存储系统依赖于众多其他服务(例如,键值存储、配置管理系统、部署管理系统)。图存储系统 [16] 同样未采用 Tectonic,因为 Tectonic 尚未针对键值存储工作负载进行优化——这类负载往往需要 SSD 存储提供的低延迟。
更多服务选择通过主要租户(例如,Blob 存储或数据仓库)间接使用 Tectonic,这源于 Tectonic “ 关注点分离 “ 的核心设计理念。其内部采用独立软件分层架构,每层仅专注存储系统的核心职责子集(例如,存储节点只需处理数据块层面逻辑,无需感知块或文件概念)。这一理念也体现在 Tectonic 与存储基础设施的协同方式中。例如,Tectonic 专注于数据中心内部的容错机制,它不防范数据中心故障。跨地域复制是一个单独的问题,Tectonic 将其委托给其大型租户,这些租户解决该问题以为应用程序提供透明且易于使用的共享存储。租户同时需要自主处理容量管理、存储部署及多数据中心数据再平衡。对于小型应用而言,直接对接 Tectonic 所需实现的复杂功能无异于重新实现租户已经实现的功能。——因此,它们选择通过租户使用 Tectonic。
7 相关工作
Tectonic 借鉴了现有系统和文献中的技术,展示了如何将它们组合成一个新颖的系统,实现支持共享存储架构上多样化工作负载的艾字节级单集群。
采用单一元数据节点的分布式文件系统:HDFS [15]、GFS [24] 及其他类似系统 [38, 40, 44] 受限于元数据节点性能,每个实例或集群的存储容量为数十 PB,而 Tectonic 每个集群为艾字节。
通过联邦名称空间扩展容量:联邦式 HDFS [8] 和 Windows Azure 存储系统(WAS)[17] 将多个较小的存储集群(各含单一元数据节点)组合成更大的集群。例如,联邦 HDFS 集群虽共享存储节点,但仍维护多个独立的单名称节点名称空间。这类联邦系统仍存在数据集装箱管理的运维复杂性(§2),且在实例间迁移或共享数据时(如实现负载均衡或扩容),仍需跨名称空间执行资源密集型数据拷贝操作 [33, 46, 54]。
基于哈希的数据定位实现元数据可扩展性:Ceph [53] 与 FDS [36] 消除了集中式元数据管理,转而采用对象 ID 哈希定位数据。但此类系统的故障处理机制存在可扩展性瓶颈。集群规模越大故障越频繁,需要频繁更新哈希到位置的映射,该映射必须传播到所有节点。Yahoo 的云对象存储系统 [41] 联邦多个 Ceph 实例以隔离故障影响。此外,由于 Ceph 缺乏受控数据迁移能力 [52],其硬件扩容与节点下线流程异常复杂。Tectonic 采用显式数据块 - 存储节点映射机制,可实现精确受控的数据迁移。
通过分离式/分片式元数据提升可扩展性:与 Tectonic 类似,ADLS [42] 和 HopsFS [35] 通过将元数据解耦并分层存储于独立的分片化存储库来提高文件系统容量。Tectonic 采用目录哈希分区策略,而 ADLS 与 HopsFS 则将部分关联目录元数据存于相同分片,导致目录树相关区域的元数据物理共存。哈希分区策略帮助 Tectonic 避免目录树局部热点问题。ADLS 采用 WAS 的联邦架构 [17] 实现块存储,相比之下 Tectonic 的块存储采用扁平化架构。
与 Tectonic 类似,Colossus [28, 32] 同样提供集群级范围艾字节级存储服务,其客户端库直接访问存储节点。但 Colossus 采用具备全局一致性的 Spanner 数据库 [21] 存储文件系统元数据,而 Tectonic 的元数据构建于分片键值存储之上,该方案仅保障分片内的强一致性,且不支持跨分片操作。实践证明这些限制并未造成实际影响。
Blob 和对象存储。 相较于分布式文件系统,Blob 及对象存储系统 [14, 18, 36, 37] 更易于扩展,因其无需维护需要保持一致性的层次化目录树或名称空间。但绝大多数数据仓库工作负载恰恰需要层次化名称空间支持。
其他大规模存储系统。 Lustre [1] 与 GPFS [45] 针对高吞吐量并行访问进行优化。Lustre 因元数据节点数量限制而影响扩展性;GPFS 虽然符合 POSIX 标准,但会为我们的应用场景引入不必要的元数据管理开销。HBase [9] 作为基于 HDFS 的键值存储系统,但其 HDFS 集群未与数据仓库工作负载共享。由于 AWS [2] 设计细节未公开,我们无法进行直接对比。
多租户技术实现。 Tectonic 的多租户技术与文件系统及租户协同设计,其目标并非实现最优公平共享。相较于文献记载的其他系统,这种设计更易于实现性能隔离。其他系统通常采用更复杂的资源管理技术来适应租户结构和资源使用策略的变化,或实现租户间最优公平资源分配 [25, 48, 49]。
需说明的是,Tectonic 系统的部分技术细节曾以 “Warm Storage” 为名在技术讲座中披露 [39, 47]。
8 结论
本文介绍了 Facebook 分布式文件系统 Tectonic。单一 Tectonic 实例即可支撑 Facebook 数据中心内所有主要存储租户,显著提升资源利用率并降低运维复杂度。其哈希分片式解耦元数据架构与扁平化数据块存储设计,支持艾字节级数据寻址与存储。通过基数降低的资源管理机制,系统既能高效公平地分配资源,又可利用富余资源实现高利用率。依托客户端驱动的租户定制优化,Tectonic 在性能表现上达到甚至超越了此前专用存储系统。
致谢。 诚挚感谢指导委员会成员 Peter Macko 以及 FAST 项目委员会的匿名评审专家,他们详尽的指导意见令本研究获益良多。同时感谢 Nar Ganapathy、Mihir Gorecha、Morteza Ghandehari、Bertan Ari、John Doty 等 Facebook 同事对本项目的贡献。感谢 Jason Flinn 与 Qi Huang 对论文改进提出的建议。Theano Stavrinos 在普林斯顿大学期间曾获美国国家科学基金资助 CNS-1910390 的支持。
参考文献
[1] Lustre Wiki. https://wiki.lustre.org/images/6/64/LustreArchitecture-v4.pdf, 2017.
[2] AWS Documentation. https://docs.aws.amazon.com/, 2020.
[3] Presto. https://prestodb.io/, 2020.
[4] Aditya Kalro. Facebook’s FBLearner Platform with Aditya Kalro. https://twimlai.com/twiml-talk-197-facebooks-fblearner-platform-with-aditya-kalro/, 2018.
[5] J. Adrian. Introducing Bryce Canyon: Our next-generation storage platform. https://tinyurl.com/yccx2x7v, 2017.
[6] M. Annamalai. ZippyDB - A Distributed key value store. https://www.youtube.com/embed/ZRP7z0HnClc, 2015.
[7] Apache Software Foundation. HDFS Erasure Coding. https://hadoop.apache.org/docs/r3.1.1/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html, 2018.
[8] Apache Software Foundation. HDFS Federation. https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/Federation.html, 2019.
[9] Apache Software Foundation. Apache HBase. https://hbase.apache.org/, 2020.
[10] Apache Software Foundation. Apache Spark. https://spark.apache.org/, 2020.
[11] D. Beaver, S. Kumar, H. C. Li, J. Sobel, and P. Vajgel. Finding a Needle in Haystack: Facebook’s Photo Storage. In Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI’10), Vancouver, BC, Canada, 2010. USENIX Association.
[12] D. Behrens, M. Serafini, F. P. Junqueira, S. Arnautov, and C. Fetzer. Scalable error isolation for distributed systems. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI’15), Oakland, CA, USA, 2015. USENIX Association.
[13] B. Berg, D. S. Berger, S. McAllister, I. Grosof, J. Gunasekar, Sathya Lu, M. Uhlar, J. Carrig, N. Beckmann, M. Harchol-Balter, and G. R. Ganger. The CacheLib Caching Engine: Design and Experiences at Scale. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI’20), Online, 2020. USENIX Association.
[14] A. Bigian. Blobstore: Twitter’s in-house photo storage system. https://blog.twitter.com/engineering/en_us/a/2012/blobstore-twitter-s-in-house-photo-storage-system.html, 2012.
[15] D. Borthakur. HDFS Architecture Guide. https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html, 2019.
[16] N. Bronson, Z. Amsden, G. Cabrera, P. Chakka, P. Dimov, H. Ding, J. Ferris, A. Giardullo, S. Kulkarni, H. Li, M. Marchukov, D. Petrov, L. Puzar, Y. J. Song, and V. Venkataramani. TAO: Facebook’s Distributed Data Store for the Social Graph. In Proceedings of the 2013 USENIX Annual Technical Conference. USENIX, 2013.
[17] B. Calder, J. Wang, A. Ogus, N. Nilakantan, A. Skjolsvold, S. McKelvie, Y. Xu, S. Srivastav, J. Wu, H. Simitci, J. Haridas, C. Uddaraju, H. Khatri, A. Edwards, V. Bedekar, S. Mainali, R. Abbasi, A. Agarwal, M. F. u. Haq, M. I. u. Haq, D. Bhardwaj, S. Dayanand, A. Adusumilli, M. McNett, S. Sankaran, K. Manivannan, and L. Rigas. Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency. In Proceedings of the 23rd ACM Symposium on Operating Systems Principles (SOSP’11), Cascais, Portugal, 2011. Association for Computing Machinery (ACM).
[18] J. Chen, C. Douglas, M. Mutsuzaki, P. Quaid, R. Ramakrishnan, S. Rao, and R. Sears. Walnut: a unified cloud object store. 2012.
[19] P. M. Chen, E. K. Lee, G. A. Gibson, R. H. Katz, and D. A. Patterson. RAID: High-performance, reliable secondary storage. ACM Computing Surveys (CSUR), 26(2):145–185, 1994.
[20] A. Cidon, S. Rumble, R. Stutsman, S. Katti, J. Ousterhout, and M. Rosenblum. Copysets: Reducing the Frequency of Data Loss in Cloud Storage. In Proceedings of the 2013 USENIX Annual Technical Conference (USENIX ATC’13), San Jose, CA, USA, 2013. USENIX Association.
[21] J. C. Corbett, J. Dean, M. Epstein, A. Fikes, C. Frost, J. J. Furman, S. Ghemawat, A. Gubarev, C. Heiser, P. Hochschild, W. Hsieh, S. Kanthak, E. Kogan, H. Li, A. Lloyd, S. Melnik, D. Mwaura, D. Nagle, S. Quinlan, R. Rao, L. Rolig, Y. Saito, M. Szymaniak, C. Taylor, R. Wang, and D. Woodford. Spanner: Google’s globally distributed database. ACM Trans. Comput. Syst., 31(3), Aug. 2013. ISSN 0734-2071. doi: 10.1145/2491245. URL https://doi.org/10.1145/2491245.
[22] J. Dean and L. A. Barroso. The tail at scale. Commun. ACM, 56(2):74–80, Feb. 2013. ISSN 0001-0782. doi: 10.1145/2408776.2408794. URL http://doi.acm.org/10.1145/2408776.2408794.
[23] Facebook Open Source. RocksDB. https://rocksdb.org/, 2020.
[24] S. Ghemawat, H. Gobioff, and S.-T. Leung. The Google File System. In Proceedings of the 19th ACM Symposium on Operating Systems Principles (SOSP’03), Bolton Landing, NY, USA, 2003. Association for Computing Machinery (ACM).
[25] R. Gracia-Tinedo, J. Sampé, E. Zamora, M. Sánchez-Artigas, P. García-López, Y. Moatti, and E. Rom. Crystal: Software-defined storage for multi-tenant object stores. In Proceedings of the 15th USENIX Conference on File and Storage Technologies (FAST’17), Santa Clara, CA, USA, 2017. USENIX Association.
[26] X. F. Group. The XFS Linux wiki. https://xfs.wiki.kernel.org/, 2018.
[27] A. Gupta, F. Yang, J. Govig, A. Kirsch, K. Chan, K. Lai, S. Wu, S. Dhoot, A. Kumar, A. Agiwal, S. Bhansali, M. Hong, J. Cameron, M. Siddiqi, D. Jones, J. Shute, A. Gubarev, S. Venkataraman, and D. Agrawal. Mesa: Geo-replicated, near real-time, scalable data warehousing. In Proceedings of the 40th International Conference on Very Large Data Bases (VLDB’14), Hangzhou, China, 2014. VLDB Endowment.
[28] D. Hildebrand and D. Serenyi. A peek behind the VM at the Google Storage infrastructure. https://www.youtube.com/watch?v=q4WC_6SzBz4, 2020.
[29] Q. Huang, P. Ang, P. Knowles, T. Nykiel, I. Tverdokhlib, A. Yajurvedi, P. Dapolito IV, X. Yan, M. Bykov, C. Liang, M. Talwar, A. Mathur, S. Kulkarni, M. Burke, and W. Lloyd. SVE: Distributed video processing at Facebook scale. In Proceedings of the 26th ACM Symposium on Operating Systems Principles (SOSP’17), Shanghai, China, 2017. Association for Computing Machinery (ACM).
[30] L. Leslie. The part-time parliament. ACM Transactions on Computer Systems, 16(2):133–169, 1998.
[31] K. Lewi, C. Rain, S. A. Weis, Y. Lee, H. Xiong, and B. Yang. Scaling backend authentication at facebook. IACR Cryptol. ePrint Arch., 2018:413, 2018. URL https://eprint.iacr.org/2018/413.
[32] M. K. McKusick and S. Quinlan. GFS: Evolution on Fast-forward. Queue, 7(7):10:10–10:20, Aug. 2009. ISSN 1542-7730. doi: 10.1145/1594204.1594206. URL http://doi.acm.org/10.1145/1594204.1594206.
[33] P. A. Misra, I. n. Goiri, J. Kace, and R. Bianchini. Scaling Distributed File Systems in Resource-Harvesting Datacenters. In Proceedings of the 2017 USENIX Annual Technical Conference (USENIX ATC’17), Santa Clara, CA, USA, 2017. USENIX Association.
[34] S. Muralidhar, W. Lloyd, S. Roy, C. Hill, E. Lin, W. Liu, S. Pan, S. Shankar, V. Sivakumar, L. Tang, and S. Kumar. f4: Facebook’s Warm BLOB Storage System. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI’14), Broomfield, CO, USA, 2014. USENIX Association.
[35] S. Niazi, M. Ismail, S. Haridi, J. Dowling, S. Grohsschmiedt, and M. Ronström. HopsFS: Scaling hierarchical file system metadata using NewSQL databases. In Proceedings of the 15th USENIX Conference on File and Storage Technologies (FAST’17), Santa Clara, CA, USA, 2017. USENIX Association.
[36] E. B. Nightingale, J. Elson, J. Fan, O. Hofmann, J. Howell, and Y. Suzue. Flat Datacenter Storage. In Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI’12), Hollywood, CA, USA, 2012. USENIX Association.
[37] S. A. Noghabi, S. Subramanian, P. Narayanan, S. Narayanan, G. Holla, M. Zadeh, T. Li, I. Gupta, and R. H. Campbell. Ambry: Linkedin’s scalable geo-distributed object store. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD’16), San Francisco, California, USA, 2016. Association for Computing Machinery (ACM).
[38] M. Ovsiannikov, S. Rus, D. Reeves, P. Sutter, S. Rao, and J. Kelly. The Quantcast File System. In Proceedings of the 39th International Conference on Very Large Data Bases (VLDB’13), Riva del Garda, Italy, 2013. VLDB Endowment.
[39] K. Patiejunas and A. Jaiswal. Facebook’s disaggregated storage and compute for Map/Reduce. https://atscaleconference.com/videos/facebooks-disaggregated-storage-and-compute-for-mapreduce/, 2016.
[40] A. J. Peters and L. Janyst. Exabyte scale storage at CERN. Journal of Physics: Conference Series, 331(5):052015, dec 2011. doi: 10.1088/1742-6596/331/5/052015. URL https://doi.org/10.1088/1742-6596/331/5/052015.
[41] N. P.P.S, S. Samal, and S. Nanniyur. Yahoo Cloud Object Store - Object Storage at Exabyte Scale. https://yahooeng.tumblr.com/post/116391291701/yahoo-cloud-object-store-object-storage-at, 2015.
[42] R. Ramakrishnan, B. Sridharan, J. R. Douceur, P. Kasturi, B. Krishnamachari-Sampath, K. Krishnamoorthy, P. Li, M. Manu, S. Michaylov, R. Ramos, N. Sharman, Z. Xu, Y. Barakat, C. Douglas, R. Draves, S. S. Naidu, S. Shastry, A. Sikaria, S. Sun, and R. Venkatesan. Azure Data Lake Store: a hyperscale distributed file service for big data analytics. In Proceedings of the 2017 International Conference on Management of Data (SIGMOD’17), Chicago, IL, USA, 2017. Association for Computing Machinery (ACM).
[43] I. S. Reed and G. Solomon. Polynomial codes over certain finite fields. Journal of the Society for Industrial and Applied Mathematics, 8(2):300–304, 1960.
[44] Rousseau, Hervé, Chan Kwok Cheong, Belinda, Contescu, Cristian, Espinal Curull, Xavier, Iven, Jan, Gonzalez Labrador, Hugo, Lamanna, Massimo, Lo Presti, Giuseppe, Mascetti, Luca, Moscicki, Jakub, and van der Ster, Dan. Providing large-scale disk storage at cern. EPJ Web Conf., 214:04033, 2019. doi: 10.1051/epjconf/201921404033. URL https://doi.org/10.1051/epjconf/201921404033.
[45] F. Schmuck and R. Haskin. GPFS: A Shared-Disk File System for Large Computing Clusters. In Proceedings of the 1st USENIX Conference on File and Storage Technologies (FAST’02), Monterey, CA, USA, 2002. USENIX Association.
[46] R. Shah. Enabling HDFS Federation Having 1B File System Objects. https://tech.ebayinc.com/engineering/enabling-hdfs-federation-having-1b-file-system-objects/, 2020.
[47] S. Shamasunder. Hybrid XFS—Using SSDs to Supercharge HDDs at Facebook. https://www.usenix.org/conference/srecon19asia/presentation/shamasunder, 2019.
[48] D. Shue, M. J. Freedman, and A. Shaikh. Performance isolation and fairness for multi-tenant cloud storage. In Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI’12), Hollywood, CA, USA, 2012. USENIX Association.
[49] A. K. Singh, X. Cui, B. Cassell, B. Wong, and K. Daudjee. Microfuge: A middleware approach to providing performance isolation in cloud storage systems. In Proceedings of the 34th IEEE International Conference on Distributed Computing Systems (ICDCS’14), Madrid, Spain, 2014. IEEE Computer Society.
[50] A. Thusoo, Z. Shao, S. Anthony, D. Borthakur, N. Jain, J. Sarma, R. Murthy, and H. Liu. Data warehousing and analytics infrastructure at facebook. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (SIGMOD’10), Indianapolis, IN, USA, 2010. Association for Computing Machinery (ACM).
[51] A. Wang. Introduction to HDFS Erasure Coding in Apache Hadoop. https://blog.cloudera.com/introduction-to-hdfs-erasure-coding-in-apache-hadoop/, 2015.
[52] L. Wang, Y. Zhang, J. Xu, and G. Xue. MAPX: Controlled Data Migration in the Expansion of Decentralized Object-Based Storage Systems. In Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST’20), Santa Clara, CA, USA, 2020. USENIX Association.
[53] S. A. Weil, S. A. Brandt, E. L. Miller, D. D. Long, and C. Maltzahn. Ceph: A scalable, high-performance distributed file system. In Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI’06), Seattle, WA, USA, 2006. USENIX Association.
[54] A. Zhang and W. Yan. Scaling Uber’s Apache Hadoop Distributed File System for Growth. https://eng.uber.com/scaling-hdfs/, 2018.
原文链接:Facebook’s Tectonic Filesystem: Efficiency from Exascale
本文为中文翻译,仅用于学习与分享,版权归原作者所有。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/08-26-2025/facebook-tectonic-filesystem.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!