
siying Dong¹, Mark Callaghan¹, Leonidas Galanis¹, Dhruba Borthakur¹, Tony Savor¹ and Michael Stumm²
¹Facebook, 1 Hacker Way, Menlo Park, CA USA 94025
{siying.d, mcallaghan, lgalanis, dhruba, tsavor}@fb.com
²多伦多大学电气与计算机工程系,加拿大 M8X 2A6
stumm@eecg.toronto.edu
摘要
RocksDB 是 Facebook 开发的一种嵌入式、高性能、持久化的键值存储引擎。当前在开发和配置 RocksDB 时的主要关注点是优先考虑资源效率,而不是优先考虑更标准的性能指标(如响应延迟和吞吐量),只要后者保持在可接受的范围内。特别是,在确保读写延迟满足目标工作负载的服务级别要求的同时,优化空间效率。这一选择的动机在于,在 Facebook 典型的生产工作负载下使用闪存 SSD 时,存储空间通常是最主要的瓶颈。RocksDB 使用日志结构合并树(log-structured merge trees)来获得显著的空间效率和更好的写入吞吐量,同时实现可接受的读取性能。
本文描述了 RocksDB 用于减少存储使用量的方法。讨论了如何权衡存储效率与 CPU 开销,以及读写放大。基于对使用 RocksDB 作为嵌入式存储引擎的 MySQL 进行的实验评估(使用 TPC-C 和 LinkBench 基准测试)以及从生产数据库获取的测量结果,表明 RocksDB 使用的存储空间不到 InnoDB 的一半,但性能良好,并且在许多情况下甚至优于基于 B 树的 InnoDB 存储引擎。据我们所知,这是基于日志结构合并树的存储引擎,首次在运行大规模 OLTP 工作负载时,展现出具有竞争力的性能。
1. 引言
资源效率是 Facebook 存储系统战略的首要目标。性能必须足以满足 Facebook 服务的需求,但效率应尽可能高以实现规模化。
Facebook 拥有世界上最大的 MySQL 部署之一,存储着数十 PB 的在线数据。Facebook MySQL 实例的底层存储引擎正越来越多地从 InnoDB 切换到 MyRocks,而后者基于 Facebook 的 RocksDB。切换的主要动机是 MyRocks 使用的存储空间是 InnoDB 所需的一半,并且具有更高的平均事务吞吐量,而读取延迟仅略微增加。
RocksDB 是一个嵌入式、高性能、持久化的键值存储系统 [1],由 Facebook 在从 Google 的 LevelDB [2, 3] 分叉代码后开发。¹ RocksDB 于 2013 年开源 [5]。MyRocks 是将 RocksDB 集成为 MySQL 的存储引擎。通过 MyRocks,可以使用 RocksDB 作为后端存储,同时仍能受益于 MySQL 的所有功能。
¹ 一篇 Facebook 博客文章列出了 RocksDB 和 LevelDB 之间的许多关键区别 [4]。
RocksDB 在 Facebook 内外的应用并不仅仅局限于 MySQL。在 Facebook 内部,RocksDB 被用作 Laser(一个高查询吞吐量、低延迟的键值存储服务 [6])、ZippyDB(一个具有 Paxos 式复制的分布式键值存储 [6])、Dragon(一个存储社交图谱索引的系统 [7])以及 Stylus(一个流处理引擎 [6])等系统的存储引擎。在 Facebook 外部,MongoDB [8] 和 Sherpa(雅虎最大的分布式数据存储 [9])都将 RocksDB 用作其存储引擎之一。此外,RocksDB 还被 LinkedIn 用于存储用户活动 [10],被 Netflix 用于缓存应用数据 [11],等等。
在 Facebook 使用 RocksDB 的主要目标是在确保所有重要服务级别要求(包括目标事务延迟)得以满足的同时,最有效地利用硬件资源。我们专注于效率而非性能,在数据库社区中可以说颇为独特,因为数据库系统通常使用每分钟事务数(例如 tpmC)或响应时间延迟等性能指标进行比较。我们对效率的关注并不意味着认为性能不重要,而是指一旦性能目标达成,就会优化效率。我们的方案部分是由 Facebook 的数据存储需求(可能与其他组织不同)驱动的:
- SSD 越来越多地用于存储持久化数据,并且是 RocksDB 的主要目标;
- Facebook 在其数据中心主要采用基于商用硬件的无共享架构 [12],数据分布在大量简单的节点上,每个节点配备 1-2 个 SSD;
- 需要存储的数据量巨大;
- 在许多(但非全部)场景下,由于广泛采用了基于内存的大规模缓存,其读写比率相对较低,大约为 2:1。
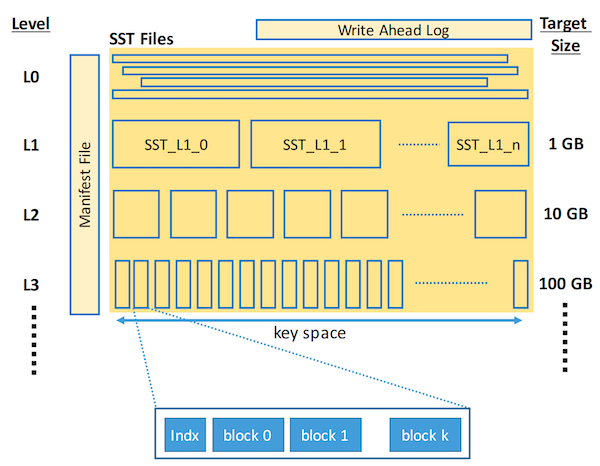
图 1:SST 文件组织。 每个层级维护一组 SST 文件。每个 SST 文件由未对齐的 16KB 块组成,并带有一个索引块来标识 SST 内的其他块。Level 0 的处理方式不同,其 SST 文件具有重叠的键范围,而其他层级的 SST 文件具有非重叠的键范围。一个清单文件(manifest file)维护所有 SST 文件及其键范围的列表以辅助查找。
最小化空间放大对于高效利用硬件至关重要,因为在上文描述的环境中,存储空间是瓶颈。在 Facebook 典型的生产 MySQL 环境中,使用 InnoDB 时,SSD 在高峰时段处理的读取/秒和写入/秒远低于硬件所能支持的水平。InnoDB 下的吞吐量水平低,并非因为 SSD 或处理节点存在任何瓶颈——例如,CPU 利用率保持在 40% 以下——而是因为每个节点的查询率低。每个节点的查询率低,是因为必须存储(并可访问)的数据量如此之大,必须将其分片到许多节点上才能容纳,而节点越多,每个节点的查询就越少。
如果 SSD 可以存储两倍的数据,那么预计存储节点效率将翻倍,因为 SSD 可以轻松处理 IOPS 翻倍的预期,并且所需的工作负载节点数将大幅减少。该问题驱动了我们对于空间放大的关注。此外,随着 SSD 价格的持续下降,最小化空间放大使得 SSD 相对于磁盘,在冷数据存储领域正成为越来越具吸引力的替代方案。在追求最小化空间放大的过程中,我们愿意牺牲一些额外的读取或写入放大。这种权衡是必要的,因为不可能同时减少空间、读取和写入放大 [13]。
RocksDB 基于日志结构合并树(LSM-tree)。LSM-tree 最初旨在最小化对存储的随机写入,因为它从不就地修改数据,而只将数据追加到位于稳定存储的文件中,以利用硬盘的高顺序写入速度 [14]。随着技术的变化,LSM-tree 因其低写入放大和低空间放大的特性而变得有吸引力。
在本文中,描述了 RocksDB 减少空间放大的技术。我们相信其中一些技术是首次被描述,包括动态 LSM-tree 层级大小调整、分级压缩(tiered compression)、共享压缩字典、前缀布隆过滤器以及不同 LSM-tree 层级使用差异化大小乘数。我们讨论了空间放大技术如何影响读取和写入放大,并描述了其中涉及的一些权衡。通过实证测量表明,RocksDB 平均所需存储空间比 InnoDB 减少约 50%,同时具备更高的事务吞吐量,且读取延迟仅略有增加,完全保持在可接受范围内。我们还探讨了空间放大与 CPU 开销之间的权衡,因为一旦空间放大显著降低,CPU 可能成为新的瓶颈。
基于实验数据证明,基于 LSM-tree 的存储引擎在用于 OLTP 工作负载时可以具有性能竞争力。我们相信这是首次展示这一点。在 MyRocks 中,每个 MySQL 表行存储为一个 RocksDB 键值对:主键编码在 RocksDB 键中,所有其他行数据编码在值中。非唯一的二级键作为单独的键值对存储,其中 RocksDB 键编码了附加了相应目标主键的二级键,值留空;因此,二级索引查找被转换为 RocksDB 范围查询。所有 RocksDB 键都带有一个 4 字节的表 ID 或索引 ID 作为前缀,以便多个表或索引可以共存于一个 RocksDB 键空间中。最后,每个键值对都存储一个随着每个写操作递增的全局序列 ID,以支持快照。快照用于实现多版本并发控制,进而使我们能够在 RocksDB 内实现 ACID 事务。
在下一节中,我们简要介绍 LSM-tree 的背景。在第 3 节中,我们描述减少空间放大的技术。在第 4 节中,我们展示如何平衡空间放大与读取放大和 CPU 开销。最后,在第 5 节中,我们展示了使用实际生产工作负载(TPC-C 和 LinkBench)以及从生产数据库实例获取的测量结果进行的实验评估结果。我们以结束语作为结尾。
2. LSM-TREE 背景
日志结构合并树(LSM-tree)如今用于许多流行系统,包括 BigTable [15]、LevelDB、Apache Cassandra [16] 和 HBase [17]。近期的重点研究也集中在 LSM-tree 上;例如 [18, 19, 20, 21, 22]。这里我们简要描述在 Facebook 的 MyRocks 中默认实现和配置的 LSM-tree。
每当数据写入 LSM-tree 时,它会被添加到一个称为内存表(mem-table)的内存写缓冲区中,该缓冲区实现为具有 O(log n) 插入和搜索复杂度的跳表(skiplist)。同时,为了恢复目的,数据会被追加到一个预写日志(WAL)中。写入后,如果 mem-table 的大小达到预定大小,则 (i) 当前的 WAL 和 mem-table 变为不可变的,并分配新的 WAL 和 mem-table 来捕获后续写入,(ii) mem-table 的内容被刷新到一个“排序序列表”(SST)数据文件中,完成后,(iii) 包含刚刷新数据的 WAL 和 mem-table 被丢弃。这种通用方法带来了许多优势:新的写入可以与旧 mem-table 的刷新同时处理;所有 I/O 都是顺序的,² 并且,除 WAL 外,只写入整个文件。
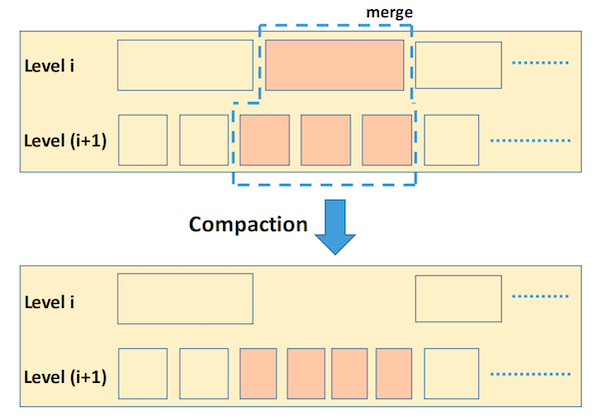
图 2:压实(Compaction)。 选定的 level-i SST 文件的内容与 level i+1 中那些键范围与 level-i SST 键范围重叠的 SST 文件合并。图中上半部分的阴影 SST 文件在合并过程后被删除。图中下半部分的阴影 SST 文件是压实过程创建的新文件。压实过程清除了已过时的数据;即,已被标记为删除的数据以及已被覆盖的数据(如果它们不再被快照需要)。
每个 SST 以排序顺序存储数据,划分为未对齐的 16KB 块(未压缩时)。每个 SST 还有一个索引块,用于二分查找,每个 SST 块一个键。SST 被组织成一系列大小递增的层级,Level-0 – Level-N,每个层级将有多个 SST,如图 1 所示。Level-0 被特殊对待,因为其 SST 可能具有重叠的键范围,而更高级别的 SST 具有不同的非重叠键范围。当 Level-0 中的文件数超过阈值(例如 4)时,Level-0 SST 与具有重叠键范围的 Level-1 SST 合并;完成后,所有合并排序输入(L0 和 L1)文件被删除,并由新的(合并后的)L1 文件替换。对于 L>0,当 level-L 中所有 SST 的组合大小超过阈值(例如 10^(L-1)GB)时,则选择一个或多个 level-L SST 并与 level-(L+1) 中重叠的 SST 合并,之后删除已合并的 level-L 和 level-(L+1) SST。如图 2 所示。
² 通常存在并发的顺序 IO 流,这会导致寻道。然而,寻道成本将被 LSM-tree 非常大的写入(许多 MB 而不是 KB)所分摊。
³ 分层压实(Leveled compaction)与 HBase 和 Cassandra [23] 等使用的压实方法不同。在本文中,所有使用的术语“压实”均指分层压实。
这个合并过程称为压实(compaction),因为它会移除标记为已删除的数据和已被覆盖的数据(如果不再需要)。该过程是多线程实现的。压实还具有将新更新从 Level-0 逐渐迁移到最后一级的效果,这就是为什么这种特定方法被称为“分层”压实的原因。³ 该过程确保在任何给定时间,每个 SST 对于任何给定键和快照最多包含一个条目。压实期间发生的 I/O 是高效的,因为它只涉及整个文件的大块读取和写入:如果一个正在压实的 level-L 文件仅与 level-(L+1) 文件的一部分重叠,那么整个 level-(L+1) 文件仍将用作压实的输入并最终被移除。一次压实可能会触发一系列级联压实。
一个单独的清单文件(Manifest File)维护每个层级的 SST 列表、它们对应的键范围以及其他一些元数据。它被维护为一个日志,对 SST 信息的更改会追加到该日志中。清单文件中的信息以高效格式缓存在内存中,以便快速识别可能包含目标键的 SST。
对键的搜索在每个连续层级进行,直到找到该键或确定该键不存在于最后一级。它首先搜索所有 mem-table,然后是所有 Level-0 SST,接着是后续各级的 SST。在每一个连续层级中,需要进行三次二分查找。第一次搜索使用清单文件中的数据定位目标 SST。第二次搜索使用 SST 的索引块定位 SST 文件内的目标数据块。最后一次搜索在数据块内查找键。布隆过滤器(保存在文件中但缓存在内存中)用于消除不必要的 SST 搜索,因此在常见情况下只需要从磁盘读取 1 个数据块。此外,最近读取的 SST 块会缓存在由 RocksDB 维护的块缓存(block cache)和操作系统的页缓存(page cache)中,因此对最近获取的数据的访问可能不需要执行 I/O 操作。MyRocks 的块缓存通常配置为 12GB 大小。
范围查询涉及更多操作,并且总是需要搜索所有层级,因为必须找到范围内的所有键。首先在 mem-table 中搜索范围内的键,然后是所有 Level-0 SST,接着是所有后续层级,同时忽略来自较低层级的范围内的重复键。前缀布隆过滤器(§4)可以减少需要搜索的 SST 数量。
为了更好地理解 LSM-tree 的系统特性,我们在附录中提供了从三个生产服务器收集的各种统计信息。
3. 空间放大
LSM-tree 通常比 B-tree 的空间效率高得多。在类似于 Facebook 的读写工作负载下,B-tree 的空间利用率会很差 [24],其页只有 1/2 到 2/3 满(根据 Facebook 生产数据库的测量)。这种碎片化导致基于 B-tree 的存储引擎的空间放大比大于 1.5。压缩的 InnoDB 在磁盘上具有固定的页大小,这进一步浪费了空间。
相反,LSM-tree 不会受到碎片化的影响,因为它不要求数据按 SSD 页面对齐写入。LSM-tree 的空间放大主要取决于尚未被垃圾回收的过时数据量。如果我们假设最后一级(last level)已按其目标大小填满数据,并且每一级比前一级大 10 倍,那么在最坏的情况下,LSM-tree 的空间放大将是 1.111…,考虑到直到最后一级的所有层级加起来只有最后一级大小的 11.111…%。
RocksDB 使用两种策略来减少空间放大:(i) 根据当前数据库大小调整层级大小,以及 (ii) 应用多种压缩策略。
3.1 动态层级大小调整
如果为每个层级指定固定大小,那么在实践中,存储在最后一级的数据大小不太可能是前一级目标大小的 10 倍。在更糟的情况下,存储在最后一级的数据大小可能仅略大于前一级的目标大小,这种情况下空间放大会大于 2。
然而,如果我们动态调整每一级的大小,使其为下一级数据大小的十分之一,那么空间放大将减少到小于 1.111…。
层级大小乘数(level size multiplier)是 LSM-tree 中的一个可调参数。上面我们假设它是 10。大小乘数越大,空间放大和读取放大越低,但写入放大越高。因此,选择代表了一种权衡。对于 Facebook 大多数生产环境的 RocksDB 安装,使用的大小乘数是 10,尽管有少数实例使用 8。
一个有趣的问题是每一级的大小乘数是否应该相同。关于 LSM-tree 的原始论文证明,在优化写入放大时,每一级使用相同的乘数是最优的 [14]。⁴ 在优化空间放大时,尤其是考虑到不同级别可能使用不同的压缩算法导致每级压缩比不同的情况下(如下一节所述),这是否仍然成立是一个悬而未决的问题。我们打算在未来的工作中分析这个问题。⁵
⁴ 原始的 LSM-tree 论文使用固定数量的层级,并随着数据库变大而改变乘数,但保持每级的乘数相同。LevelDB/RocksDB 使用固定乘数,但随着数据库变大而改变层级数量。
⁵ 初步结果表明,调整每级的大小目标以考虑每级实现的压缩比会带来更好的结果。
3.2 压缩
可以通过压缩 SST 文件来进一步减少空间放大。我们同时应用多种策略。LSM-tree 提供了许多使压缩策略更有效的特性。特别是,LSM-tree 中的 SST 及其数据块是不可变的。
键前缀编码。 通过不写入与前一个键重复的前缀,对键应用前缀编码。我们发现这在实践中可以减少 3% – 17% 的空间需求,具体取决于数据工作负载。
序列 ID 垃圾回收。 如果键的序列 ID 比多版本并发控制所需的最旧快照还旧,则将其移除。用户可以任意创建快照以在以后的时间点引用当前数据库状态。移除快照 ID 往往是有效的,因为 7 字节大的序列 ID 压缩效果不好,并且因为大多数序列 ID 在引用它们的相应快照被删除后不再需要。在实践中,这种优化可以减少 0.03%(例如,对于存储具有大值的社交图谱顶点的数据库)到 23%(例如,对于存储具有空值的社交图谱边的数据库)的空间需求。
数据压缩。 RocksDB 目前支持多种压缩算法,包括 LZ、Snappy、zlib 和 Zstandard。每个层级可以配置为使用这些压缩算法中的任何一种或不使用。压缩按块(block) basis 应用。根据数据的组成,较弱的压缩算法可以将空间需求降低到其原始大小的 40%,而较强的算法在 Facebook 生产数据上可以低至 25%。
为了减少解压缩数据块的频率,RocksDB 块缓存以未压缩的形式存储块。(请注意,最近访问的压缩文件块将由操作系统页缓存以压缩形式缓存,因此压缩的 SST 将使用更少的存储空间和更少的缓存空间,这反过来允许文件系统缓存更多数据。)
基于字典的压缩。 可以使用数据字典来进一步改进压缩。当使用小数据块时,数据字典尤其重要,因为较小的块通常产生较低的压缩比。字典使得较小的块能够从更多的上下文中受益。通过实验,我们发现数据字典可以额外减少 3% 的空间需求。
LSM-tree 使得构建和维护字典更加容易。它们倾向于生成大的不可变 SST 文件,这些文件可能高达数百兆字节。应用于所有数据块的字典可以存储在文件内部,这样当文件被删除时,字典会自动丢弃。
4. 权衡
LSM-tree 有许多配置参数和选项,使得能够根据目标工作负载的具体情况为每个安装进行多种权衡。Athanassoulis 等人的先前工作确定,可以优化空间、读取和写入放大中的任意两个,但会牺牲第三个 [13]。例如,减少层级数量(比如通过增加层级乘数)会降低空间和读取放大,但会增加写入放大。
再举一个例子,在 LSM-tree 中,较大的块大小可以在不降低写入放大的情况下改进压缩,但会对读取放大产生负面影响(因为每次查询必须读取更多数据)。这一观察允许我们在处理写入密集型应用程序时使用较大的块大小来获得更好的压缩比。(在 B 树中,较大的块会同时降低写入和读取放大。)
在许多情况下,如何权衡需要人为判断,并取决于预期的工作负载以及系统最低可接受的服务质量水平。当专注于效率时(正如我们所做的),极难将系统配置为恰当地平衡 CPU、磁盘 I/O 和内存利用率,尤其是因为它强烈依赖于高度变化的工作负载。
正如我们在下一节所示,我们的技术将存储空间需求比 InnoDB 减少了 50%。这使我们能够在每个节点上存储两倍的数据,从而实现现有硬件的显著整合。然而,与此同时,这也意味着每个服务器的工作负载(QPS)翻倍,这可能导致系统达到可用 CPU、随机 I/O 和 RAM 容量的极限。
分级压缩(Tiered compression)。 压缩(Compression)通常会减少所需的存储空间量,但会增加 CPU 开销,因为数据必须被压缩和解压缩。压缩越强,CPU 开销越高。在我们的安装中,通常在最末级使用强压缩算法(如 zlib 或 Zstandard),即使它带来更高的 CPU 开销,因为大部分(接近 90%)数据位于该级,但只有一小部分读取和写入会访问它。在各种用例中,对最末级应用强压缩比仅使用轻量级压缩额外节省 15%–30% 的存储空间。
相反,我们在级别 0-2 不使用任何压缩,以牺牲更高的空间和写入放大为代价来允许更低的读取延迟,因为它们只占总存储空间的一小部分。Level-3 到最末级使用轻量级压缩(如 LZ4 或 Snappy),因为其 CPU 开销是可接受的,同时它减少了空间和写入放大。对位于前三个级别的数据的读取更可能位于操作系统缓存的(未压缩的)文件块中,因为这些块被频繁访问。然而,对位于高于 2 的级别中的数据的读取将必须被解压缩,无论它们是否位于操作系统文件缓存中(除非它们也位于 RocksDB 块缓存中)。
布隆过滤器。 布隆过滤器可有效减少 I/O 操作及随之而来的 CPU 开销,但代价是稍微增加内存使用量,因为过滤器(通常)每个键需要 10 位。为了说明一些权衡是微妙的,我们在最末级不使用布隆过滤器。虽然这会导致更频繁地访问最末级文件,但读取查询到达最末级的概率相对较小。更重要的是,最末级的布隆过滤器很大(比所有较低级别布隆过滤器的总和还大 9 倍),并且它在基于内存的缓存中消耗的空间将阻止缓存其他将被访问的数据。我们根据经验确定,对于我们的工作负载,最末级没有布隆过滤器总体上改善了读取放大。
前缀布隆过滤器。 布隆过滤器对范围查询没有帮助。我们开发了一种前缀布隆过滤器来帮助处理范围查询,这是基于我们的观察:许多范围查询通常只针对某个特定前缀;例如,(userid,timestamp) 键的 userid 部分或 (postid,likerid) 键的 postid 部分。为此,我们允许用户定义前缀提取器(prefix extractors),以确定性地从键中提取前缀部分,并据此构建布隆过滤器。查询范围时,用户可以指定查询是针对已定义的前缀。我们发现这种优化在我们的系统上将范围查询的读取放大(及随之而来的 CPU 开销)减少了高达 64%。
5. 评估
对 Facebook 众多 MySQL 安装的回顾普遍表明:
- RocksDB 使用的存储空间比启用压缩的 InnoDB 使用的空间低约 50%,
- RocksDB 写入存储的数据量是 InnoDB 写出的数据的 10% 到 15% 之间,并且
- RocksDB 的读取次数和量比 InnoDB 高 10% – 20%(但仍完全在可接受的范围内)。
为了从受控环境中获得更有意义的指标,我们展示了使用两个基准测试对 MySQL 进行广泛实验的结果。第一个基准测试 LinkBench,基于来自 Facebook 存储“社交图谱”数据的生产数据库的跟踪;它发出大量范围查询 [25]。我们运行了 24 个 1 小时间隔的 LinkBench,并测量第 24 个间隔的统计数据,以获取稳态系统的数字。⁶ 第二个基准测试是标准的 TPC-C 基准测试。
⁶ 我们还收集了加载完整 LinkBench 数据库时的统计数据;(未显示的)结果与稳态数字一致。
对于这两个基准测试,我们试验了两个变体:一个是数据库完全放入 DRAM 中,因此只需要磁盘活动用于实现持久性的写入;另一个是数据库不能完全放入内存中。我们比较了 RocksDB、InnoDB 和 TokuDB 的行为,配置为使用各种压缩策略。(TokuDB 是另一个开源的、高性能的 MySQL 存储引擎,其核心使用分形树索引数据结构来减少空间和写入放大 [26]。)
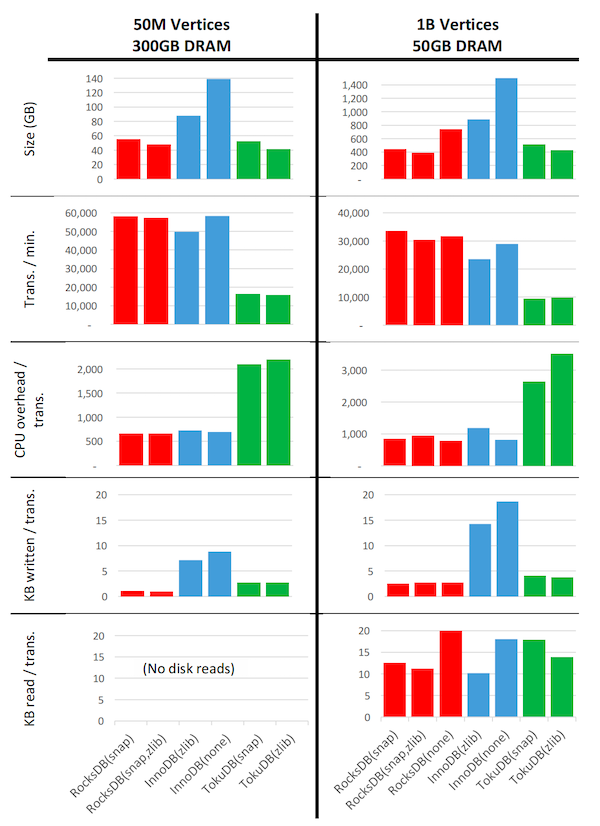
图 3:LinkBench 基准测试。 使用 16 个并发客户端运行 24 小时后,在第 24 小时收集的统计数据,针对三种不同的存储引擎:RocksDB(来自 Facebook MySQL 5.6)以红色显示,InnoDB(来自 MySQL 5.7.10)以蓝色显示,以及 TokuDB(Percona Server 5.6.26-74.0)以绿色显示,配置为使用括号中列出的压缩方案。(同步提交(Sync-on-commit)被禁用,二进制日志/操作日志(binlog/oplog)和重做日志(redo logs)已启用。)
系统设置:硬件包括一个 Intel Xeon E5-2678v3 CPU,具有 24 核/48 硬件线程,运行频率为 2.50GHz,256GB RAM,以及大约 5T 的快速 NVMe SSD,通过配置为 SW RAID 0 的 3 个设备提供。操作系统是 Linux 4.0.9-30。
左侧图表:来自配置为存储 5000 万个顶点(完全放入 DRAM)的 LinkBench 的统计数据。
右侧图表:来自配置为存储 10 亿个顶点(在将 DRAM 内存限制为 50GB 后无法放入内存)的 LinkBench 的统计数据:除 50GB 外的所有 RAM 都被后台进程 mlock,因此数据库软件、操作系统页缓存和其他监控进程必须共享这 50GB。MyRocks 块缓存设置为 10GB。
图 3 显示了我们的 LinkBench 实验结果。使用的硬件和软件设置在图的说明中描述。对于数据库不能完全放入内存的 LinkBench 基准测试的一些观察:
- 空间使用: 启用压缩的 RocksDB 使用的存储空间比考虑的任何替代方案都少;未压缩时,它使用的存储空间不到未压缩 InnoDB 的一半。
- 事务吞吐量: RocksDB 表现出比所有考虑的替代方案更高的吞吐量:比 InnoDB 好 3%-16%,远优于 TokuDB。图中未显示的是,在所有情况下,CPU 都是阻止吞吐量进一步提高的瓶颈。
- CPU 开销: 当使用更强的压缩时,RocksDB 表现出比未压缩的 InnoDB 每事务高不到 20% 的 CPU 开销,但只有 TokuDB 的不到 30% 的 CPU 开销。使用强压缩的 RocksDB 产生的 CPU 开销仅相当于启用压缩的 InnoDB 的 80%。
- 写入量: RocksDB 中每事务写入的数据量不到 InnoDB 写入数据量的 20%。⁷ RocksDB 的写入量显著低于 TokuDB 的写入量。
- 读取量: 未使用压缩时,RocksDB 中每个读取事务读取的数据量比 InnoDB 高 20%,使用压缩时则高出 10% 到 22%。RocksDB 的读取量显著少于 TokuDB 的读取量。
⁷ I/O 量数字来自 iostat。写入量数字必须进行调整,因为 iostat 将 TRIM 计为写入的字节,而实际上并没有写入任何字节。RocksDB 经常删除整个文件(与 InnoDB 相比)并为此使用 TRIM,iostat 将其报告为好像整个文件已被写入。
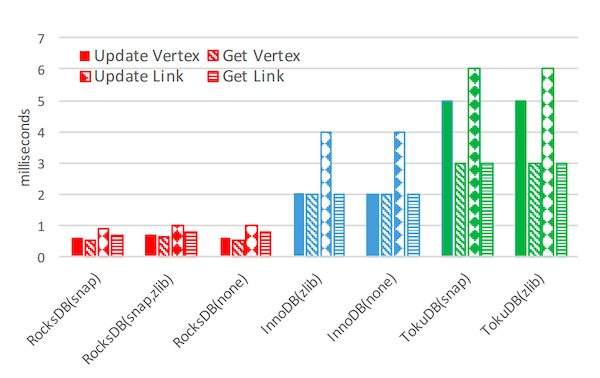
图 4:LinkBench 服务质量: 更新顶点、获取顶点、更新链接、获取链接的 99th 百分位数延迟。硬件和存储引擎的设置如图 3 所述。使用了具有 10 亿个顶点的数据库,可用 DRAM 限制为 50GB。
图 4 描述了不同存储引擎实现的服务质量。具体来说,它显示了 LinkBench 数据库中顶点和边的读写请求的 99th 百分位数延迟。RocksDB 的性能表现比所有其他考虑的替代方案好一个数量级。
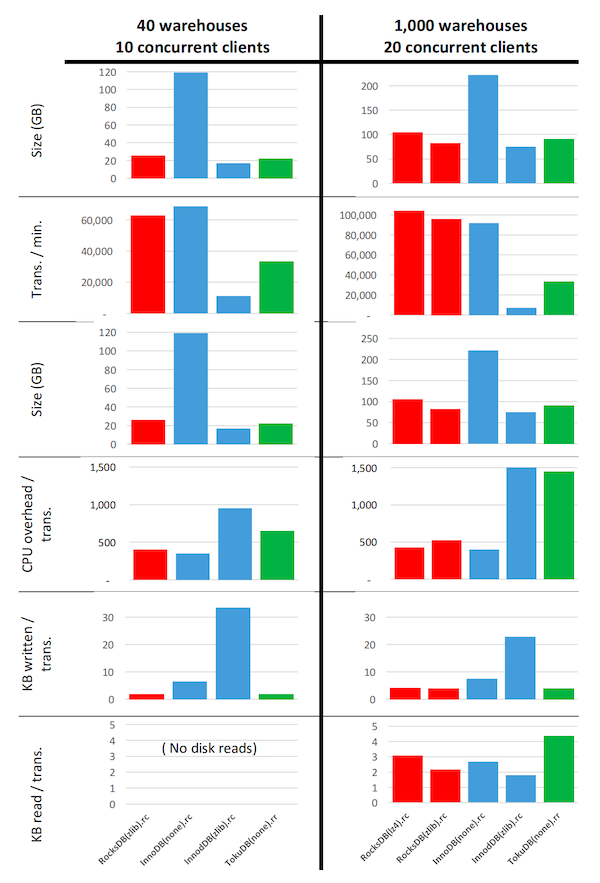
图 5:TPC-C 基准测试。 使用与图 3 相同的设置获得的指标。
左侧:40 个仓库和 10 个并发客户端的配置。数据库完全放入内存。统计数据是在运行 14 小时后的整个第 15 小时内收集的。
右侧:1000 个仓库和 20 个并发客户端的配置。统计数据是在运行 11 小时后的整个第 12 小时内收集的。使用的事务隔离级别标记为“rc”表示 READ COMMITTED(读已提交)或“rr”表示 REPEATABLE READ(可重复读)。
TPC-C 基准测试的结果显示在图 5 中。这里的数据库大小统计数据较难解释,因为 TPC-C 数据库随着事务数量的增长而增长。例如,显示启用压缩的 InnoDB 需要较小的存储空间,但这只是因为该 InnoDB 变体在测量点之前能够处理的事务少得多;实际上,InnoDB 数据库大小在事务时间内的增长比 RocksDB 快得多。
该图清楚地表明,RocksDB 不仅在 OLTP 工作负载上具有竞争力,而且通常具有更高的事务吞吐量,同时所需的存储空间显著少于替代方案。RocksDB 每事务写出的数据比所有其他测试的配置都少,而读取的数据仅略多,每事务所需的 CPU 开销也仅略高。
6. 结束语
我们描述了 RocksDB 如何能够将存储空间需求比 InnoDB 所需减少 50%,同时提高事务吞吐量并显著降低写入放大,而平均读取延迟仅略微增加。它通过利用 LSM-tree 并应用各种节省空间的技术来实现这一点。
据我们所知,其中许多技术是首次被描述,包括:(i) 基于当前数据库大小的动态 LSM-tree 层级大小调整;(ii) 分级压缩(tiered compression),即在不同的 LSM-tree 层级使用不同级别的压缩;(iii) 使用共享压缩字典;(iv) 将布隆过滤器应用于键前缀;以及 (v) 在不同的 LSM-tree 层级使用不同的大小乘数。此外,我们相信这是首次表明基于 LSM-tree 的存储引擎在传统 OLTP 工作负载上具有竞争性能。
7. 参考文献
[1] http://rocksdb.org.
[2] http://leveldb.org.
[3] https://github.com/google/leveldb.
[4] https://github.com/facebook/rocksdb/wiki/Features-Not-in-LevelDB.
[5] https://github.com/facebook/rocksdb.
[6] G. J. Chen, J. L. Wiener, S. Iyer, A. Jaiswal, R. Lei, N. Simha, W. Wang, K. Wilfong, T. Williamson, and S. Yilmaz, “Realtime data processing at Facebook,” in Proc. Intl. Conf. on Management of Data, 2016, pp. 1087–1098.
[7] A. Sharma, “Blog post: Dragon: a distributed graph query engine,” https://code.facebook.com/posts/1737605303120405/dragon-a-distributed-graph-query-engine/, 2016.
[8] https://www.mongodb.com.
[9] https://yahooeng.tumblr.com/post/120730204806/sherpa-scales-new-heights.
[10] https://www.youtube.com/watch?v=plqVpO̲nSzg.
[11] http://techblog.netix.com/2016/05/application-data-caching-using-ssds.html.
[12] http://opencompute.org.
[13] M. Athanassoulis, M. S. Kester, L. M. Maas, R. Stoica, S. Idreos, A. Ailamaki, and M. Callaghan, “Designing access methods: the RUM conjecture,” in Proc. Intl. Conf. on Extending Database Technology (EDBT), 2016.
[14] P. O’Neil, E. Cheng, D. Gawlick, and E. O’Neil, “The log-structured merge-tree (LSM-tree),” Acta Informatica, vol. 33, no. 4, pp. 351–385, 1996.
[15] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber, “BigTable: A distributed storage system for structured data,” ACM Trans. on Computer Systems (TOCS), vol. 26, no. 2, p. 4, 2008.
[16] A. Lakshman and P. Malik, “Cassandra: a decentralized structured storage system,” ACM SIGOPS Operating Systems Review, vol. 44, no. 2, pp. 35–40, 2010.
[17] A. S. Aiyer, M. Bautin, G. J. Chen, P. Damania, P. Khemani, K. Muthukkaruppan, K. Ranganathan, N. Spiegelberg, L. Tang, and M. Vaidya, “Storage infrastructure behind Facebook messages: Using HBase at scale.” IEEE Data Eng. Bull., vol. 35, no. 2, pp. 4–13, 2012.
[18] P. A. Bernstein, S. Das, B. Ding, and M. Pilman, “Optimizing optimistic concurrency control for tree-structured, log-structured databases,” in Proc. 2015 ACM SIGMOD Intl. Conf. on Management of Data, 2015, pp. 1295–1309.
[19] H. Lim, D. G. Andersen, and M. Kaminsky, “Towards accurate and fast evaluation of multi-stage log-structured designs,” in 14th USENIX Conf. on File and Storage Technologies (FAST 16), Feb. 2016, pp. 149–166.
[20] R. Sears and R. Ramakrishnan, “bLSM: a general purpose log structured merge tree,” in Proc. 2012 ACM SIGMOD Intl. Conf. on Management of Data, 2012, pp. 217–228.
[21] H. T. Vo, S. Wang, D. Agrawal, G. Chen, and B. C. Ooi, “LogBase: a scalable log-structured database system in the cloud,” Proc. of the VLDB Endowment, vol. 5, no. 10, pp. 1004–1015, 2012.
[22] P. Wang, G. Sun, S. Jiang, J. Ouyang, S. Lin, C. Zhang, and J. Cong, “An efficient design and implementation of LSM-tree based key-value store on open-channel SSD,” in Proc. 9th European Conf. on Computer Systems. ACM, 2014, p. 16.
[23] T. Hobbs, “Blog post: When to use leveled compaction,” http://www.datastax.com/dev/blog/when-to-use-leveled-compaction, june 2012.
[24] A. C.-C. Yao, “On random 2|3 trees,” Acta Inf., vol. 9, no. 2, pp. 159–170, Jun. 1978.
[25] T. G. Armstrong, V. Ponnekanti, D. Borthakur, and M. Callaghan, “LinkBench: A database benchmark based on the Facebook Social Graph,” in Proc. 2013 ACM SIGMOD Intl. Conf. on Management of Data, 2013, pp. 1185–1196.
[26] I. Tokutek, “TokuDB: MySQL performance, MariaDB performance,” http://www.tokutek.com/products/tokudb-for-mysql/, 2013.
附录
在本附录中,我们展示了三个基于 LSM tree 的生产系统中收集的各种统计数据。目的是让读者更好地了解基于 LSM tree 的系统在实践中的行为。
我们展示的统计数据是从生产环境中运行 MySQL/MyRocks 服务器处理社交网络查询的代表性服务器收集的。工作负载是更新密集型的。这里提供的数据是在超过一个月的观察期内收集的。
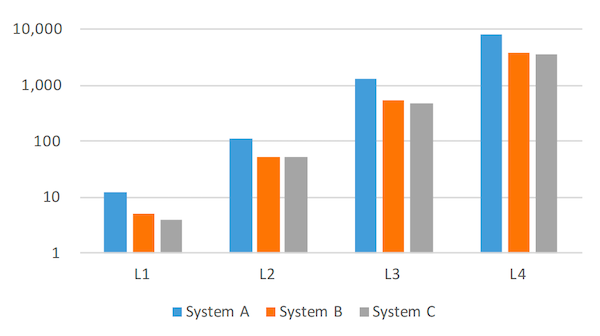
图 6:每个层级的文件数。 注意 y 轴是对数刻度。未包括 Level 0,因为该级别的文件数在 0 到 4 之间振荡,并且报告的值很大程度上取决于快照的拍摄时间。
图 6 描述了观察期结束时每个层级的文件数量。图 7 描述了观察期结束时每个层级文件的聚合大小。在这两个图中,不同层级数字之间的相对差异比绝对数字提供更多洞察。图表显示,文件数量和文件的聚合大小在每一级大约增长 10 倍,这正如第 2 节描述所预期的那样。
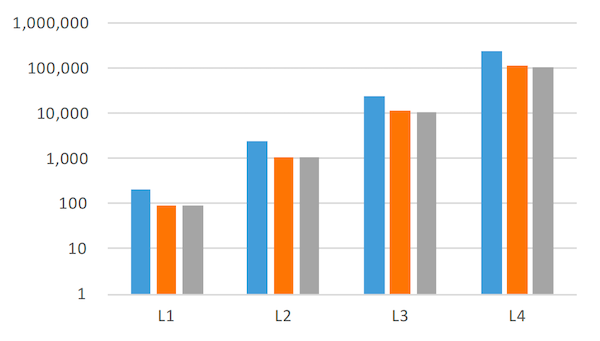
图 7:每个层级所有文件的聚合大小(兆字节)。 注意 y 轴是对数刻度。出于与图 6 所述相同的原因,未包括 Level 0。
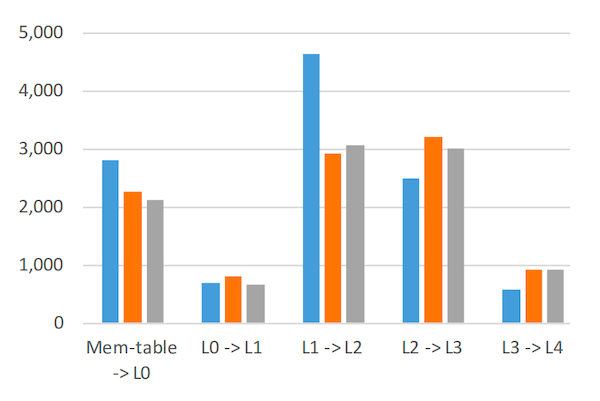
图 8:观察期间三个系统在每个层级发生的压实次数。 注意 y 轴不是对数刻度。
图 8 显示了观察期间每个层级发生的压实次数。同样,绝对数字意义不大,尤其是它们受配置参数影响很大。左侧的第一组条形代表将 mem-table 复制到 L0 文件的实例。第二组条形代表将所有 L0 文件合并到 L1;因此,每次这样的压实涉及的数据远多于,例如,将 L1 文件合并到 L2 的压实。
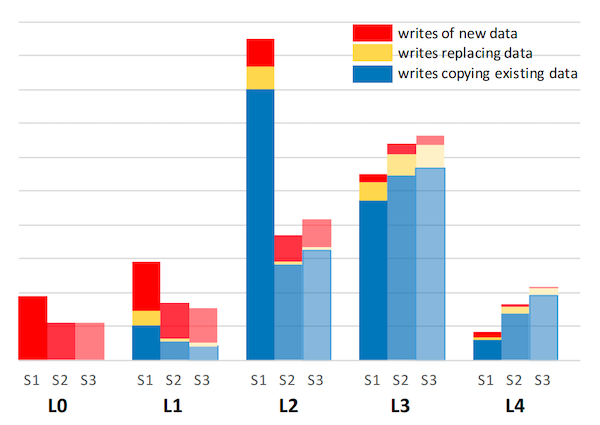
图 9:三个系统在每个层级的磁盘写入。 每个条形的高度代表观察期间每个层级写入磁盘的总字节数。这进一步细分为:(i) 红色:新数据的写入,即键在当前该层级不存在的写入;(ii) 黄色:正在更新的数据的写入,即键已在该层级存在的写入;以及 (iii) 蓝色:从同一层级的现有 SST 复制的数据的写入。y 轴已隐藏,因为绝对数字不具有信息性。y 轴未按对数缩放。
图 9 描述了观察期间每个层级写入磁盘的数据量(以 GB 为单位),按新数据写入、更新数据写入以及从同一层级现有 SST 复制的数据写入进行细分。对 Level 0 的写入几乎全是新写入,由红色条形表示。需要谨慎解释数据:在 level Li 的新数据写入仅意味着写入数据时该键值对的键在该层级不存在,但该键很可能存在于 level Lj(j > i)中。
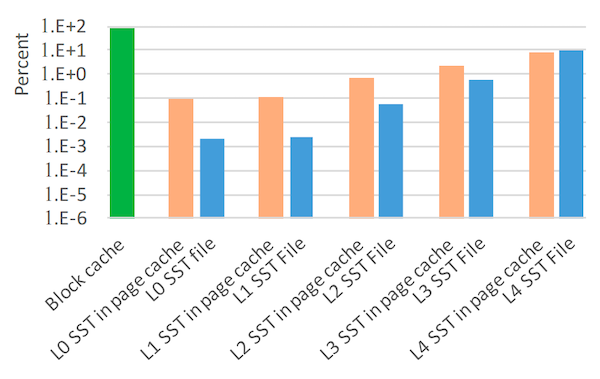
图 10:目标读取查询数据的位置。 每个条形显示从每个可能来源提供服务的读取查询的百分比。注意该图的 y 轴是对数刻度。此图中表示的读取查询是聚合了正在监控的三个系统的查询。79.3% 的所有读取查询由 RocksDB 块缓存提供服务。未由块缓存提供服务的读取查询由 L0、L1、L2、L3 或 L4 SST 文件提供服务。其中一些由操作系统页缓存提供服务,因此不需要任何磁盘访问。不到 10% 的读取查询导致磁盘访问。
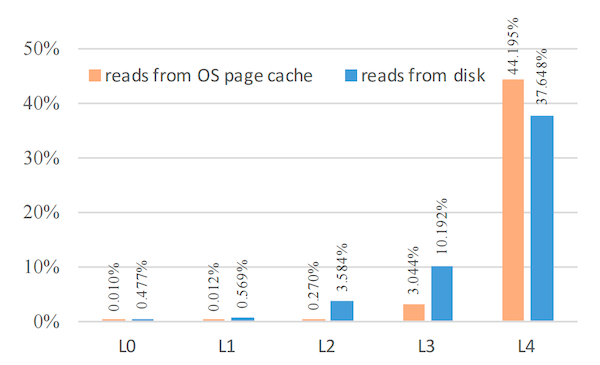
图 11:当不在 RocksDB 块缓存中时,目标读取查询数据的位置。 该图描述了与图 10 相同的数据,但针对的是在 RocksDB 块缓存中未命中的读取访问。注意该图的 y 轴不是对数刻度。该图显示绝大多数(82%)在 RocksDB 块缓存中未命中的读取查询由最后一级 L4 提供服务。对于这些读取查询,有 46% 的数据是从操作系统文件页缓存中获取的。
图 10 和图 11 描述了读取查询数据提供服务的位置。对于此图,我们汇总了所有三个系统的读取次数。大多数读取请求由 RocksDB 块缓存成功提供服务:对于数据块,命中率为 79.3%,对于包含索引和布隆过滤器的元数据块,命中率为 99.97%。RocksDB 缓存中的未命中会导致文件系统读取。该图显示大多数(52%)的文件系统读取由操作系统页缓存服务,对于级别 L0-L4,页缓存命中率分别为 98%、98%、93%、77% 和 46%。然而,考虑到近 90% 的磁盘存储空间用于保存来自最后一级 L4 的数据,并且 L4 数据的 RocksDB 块缓存命中率较差(92% 的所有在块缓存中未命中的读取查询由 L4 提供服务),这一点很清楚。由于大多数文件访问是针对 L4 SST,显然布隆过滤器有助于减少这些读取查询在 L0–L3 级别的文件访问次数。
版权及翻译声明:
本文翻译自 Siying Dong 等人发表于 CIDR 2017 的论文《Optimizing Space Amplification in RocksDB》。原论文基于 Creative Commons Attribution License (CC BY 3.0) 许可协议发布,允许在保留对原作者及出处(CIDR 2017)署名的前提下进行分发、复制和演绎。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/04-03-2026/optimizing-space-amplification-in-rocksdb-cn.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!