
- 一、控制 SST 文件大小的配置参数
- 二、不同层级 SST 文件大小的计算规则
- 三、不同场景下的 SST 文件大小控制
- 四、Compaction 中的 SST 文件切分策略
- 五、工作负载如何增加小 SST 出现概率
- 六、统计指标
- 七、总结
在 RocksDB 中,SST(Sorted String Table)文件是持久化存储数据的基本单位。SST 文件的大小对 RocksDB 的性能有着深远影响:太小的文件会导致文件数量过多,增加元数据开销和文件打开/关闭的操作负担;太大的文件则可能导致读放大和更高的 compaction 负担。
本文基于 RocksDB v8.8.1,分析在启用 Leveled Compaction、kMinOverlappingRatio 和 level_compaction_dynamic_file_size 的情况下,RocksDB 在 compaction 写输出 SST 时,哪些判断会让当前文件提前结束,从而产生小于常规目标大小的 SST 文件。
一、控制 SST 文件大小的配置参数
RocksDB 通过以下核心参数控制 SST 文件大小:
// 主要控制参数
Options options;
options.target_file_size_base = 64 * 1024 * 1024; // 默认 64MB
options.target_file_size_multiplier = 1; // 默认为 1
options.max_compaction_bytes = 1.6 * 1024 * 1024 * 1024; // 默认 1.6GB
options.write_buffer_size = 64 * 1024 * 1024; // 默认 64MB,影响 L0 文件大小以上参数的具体含义是:
target_file_size_base: 定义 L1 层文件的目标大小,默认为 64MBtarget_file_size_multiplier: 文件大小在各层之间的增长倍数,默认为 1max_compaction_bytes: 参与ShouldStopBefore()中的 overlap cut 判断,默认为target_file_size_base * 25;当target_file_size_base使用默认值 64MB 时,对应约 1.6GB。这个分支比较的是grandparent_overlapped_bytes_ + current_output_file_size_是否超过阈值,因此它关注的是当前输出文件与祖父层文件的重叠规模,而不是单个输出 SST 的大小上限write_buffer_size: 控制 Memtable 的大小,间接影响从 Memtable 刷盘生成的 L0 文件大小
二、不同层级 SST 文件大小的计算规则
RocksDB 会根据层级不同,为每个层级计算一个目标文件大小。这一计算过程在 MutableCFOptions::RefreshDerivedOptions 函数中实现:
void MutableCFOptions::RefreshDerivedOptions(int num_levels,
CompactionStyle compaction_style) {
max_file_size.resize(num_levels);
for (int i = 0; i < num_levels; ++i) {
if (i == 0 && compaction_style == kCompactionStyleUniversal) {
max_file_size[i] = ULLONG_MAX; // Universal 压缩中的 L0 层不限制大小
} else if (i > 1) {
// 非 L0 和 L1 层:上一层文件大小 * 倍数
max_file_size[i] = MultiplyCheckOverflow(max_file_size[i - 1],
target_file_size_multiplier);
} else {
// L0 (非Universal) 和 L1 层:使用基础大小
max_file_size[i] = target_file_size_base;
}
}
}根据上述代码,可以得出不同层级 SST 文件大小的计算公式:
Ln 层文件大小 = target_file_size_base * (target_file_size_multiplier^(n-1))具体来说:
L0 层:
- 对于 Universal 压缩风格:文件大小不受限制 (ULLONG_MAX)
- 其他压缩风格:
target_file_size_base(默认 64MB) - 但实际上 L0 的文件大小主要取决于 memtable 刷盘过程
L1 层:
- 总是设置为
target_file_size_base(默认 64MB)
- 总是设置为
L2 及更高层级:
- 按照公式:上一层大小 ×
target_file_size_multiplier - 例如,若
target_file_size_multiplier为 2:- L1: 64MB
- L2: 128MB
- L3: 256MB
- 以此类推
- 按照公式:上一层大小 ×
三、不同场景下的 SST 文件大小控制
3.1 L0 层文件大小控制
L0 层的 SST 文件有两种生成方式:
3.1.1 Memtable 刷盘生成
当 memtable 满或达到其他刷盘条件时,会被刷到 L0 层生成 SST 文件:
// 文件大小由 memtable 大小决定,通常由 write_buffer_size 控制
// 这类文件的大小不受 target_file_size 参数限制
Status DBImpl::FlushMemTableToOutputFile(...) {
// ...
// 从 memtable 创建 SST 文件,大小取决于 memtable 实际内容大小
s = BuildTable(...)
// ...
}该方式生成的 L0 文件大小近似等于 memtable 中实际数据大小,不受 target_file_size 参数限制。当 min_write_buffer_number_to_merge 设置为 2 时,Memtable 刷盘生成的 SST 文件大小约为 2 个 write_buffer_size 的大小(实际情况下,数据压缩、记录合并或删除会降低文件大小)。因为该参数控制了在刷盘前需要合并的最小 memtable 数量。
3.1.2 Intra-L0 compaction 生成
当 L0 层文件过多时,RocksDB 会触发 Intra-L0 compaction,合并多个 L0 文件:
// L0 compaction 不进入后续大小判断和祖父层边界启发式
if (compaction_->output_level() == 0) {
// L0 层不应用基于祖父文件边界的文件切分启发式算法
return false;
}当 output_level() == 0 时,ShouldStopBefore() 会直接返回,不进入后续的大小判断、RoundRobin split 和祖父层边界启发式逻辑。因此,本文后续讨论的几类提前切分分支主要适用于输出层级大于 0 的 compaction。
3.2 非 L0 和非 Bottommost 层文件大小控制
对于 L1 到倒数第二层的文件,RocksDB 在 Compaction 构造函数中设置其大小限制:
// 在 Compaction 构造函数中计算目标输出文件大小
Compaction::Compaction(...) {
// ...
target_output_file_size_ = MaxFileSizeForLevel(
mutable_cf_options, output_level, compaction_style, base_level,
level_compaction_dynamic_level_bytes);
// 非底层文件可能是目标大小的 2 倍
max_output_file_size_ =
bottommost_level_ || grandparents_.empty() ||
!_immutable_options.level_compaction_dynamic_file_size
? target_output_file_size_
: 2 * target_output_file_size_;
// ...
}从代码可以看出,当满足下列条件时,非底层文件的最大大小可能是目标大小的 2 倍:
- 非底层 compaction
- 有祖父层文件
- 启用了动态文件大小调整选项
这种设计允许 RocksDB 在特定场景下生成更大的中间层文件,减少文件数量。
3.3 Bottommost 层文件大小控制
当 compaction 输出到底层时,max_output_file_size_ 使用 target_output_file_size_:
max_output_file_size_ =
bottommost_level_ || grandparents_.empty() ||
!_immutable_options.level_compaction_dynamic_file_size
? target_output_file_size_ // 底层使用目标大小
: 2 * target_output_file_size_;当 compaction 输出到最底层时(bottommost_level_ 为 true),max_output_file_size_ 等于 target_output_file_size_,不会启用非底层的 2 倍动态上限。由于底层之后没有更低层文件参与后续 compaction,本文重点分析的祖父层边界启发式主要发生在非 bottommost 输出场景。
3.4 动态层级大小下的文件大小计算
当启用 level_compaction_dynamic_level_bytes 选项时,RocksDB 使用相对于基础层级的方式计算文件大小:
uint64_t MaxFileSizeForLevel(const MutableCFOptions& cf_options,
int level, CompactionStyle compaction_style, int base_level,
bool level_compaction_dynamic_level_bytes) {
// 检查是否使用动态层大小
if (!level_compaction_dynamic_level_bytes || level < base_level ||
compaction_style != kCompactionStyleLevel) {
// 常规计算方式:直接使用层级对应的大小
assert(level >= 0);
assert(level < (int)cf_options.max_file_size.size());
return cf_options.max_file_size[level];
} else {
// 动态层大小方式:使用相对于基础层的偏移
assert(level >= 0 && base_level >= 0);
assert(level - base_level < (int)cf_options.max_file_size.size());
return cf_options.max_file_size[level - base_level];
}
}这是因为在 level_compaction_dynamic_level_bytes 模式下,RocksDB 的基础层级可能不是 L1,而是由系统根据数据量动态调整的。在这种情况下,我们需要使用相对于基础层级的偏移量来索引文件大小数组。
四、Compaction 中的 SST 文件切分策略
在 compaction 写输出 SST 时,ShouldStopBefore() 决定是否在当前 key 写入之前结束当前文件。这个判断不是单一的大小检查,而是按顺序执行几类提前切分条件:先处理 TTL 和自定义 partitioner,再处理常规大小上限和 RoundRobin split,最后在当前 key 跨过祖父层文件边界时,进入几类可能产生小 SST 的启发式判断。
该函数需要依赖一个重要的辅助函数 UpdateGrandparentBoundaryInfo,该函数负责跟踪正在构建的输出文件与祖父层(L+2 层)文件的关系,为切分决策提供必要的信息。先来深入理解这个辅助函数的工作原理。
4.1 追踪祖父层文件边界:UpdateGrandparentBoundaryInfo 函数
UpdateGrandparentBoundaryInfo 函数的主要作用是跟踪键与祖父层文件的相对位置关系,更新状态并返回键跨越的边界数。
下面是该函数的代码和详细注释:
// 更新关于当前内部键 `internal_key` 与祖父层(L+2)文件边界和重叠的信息。
size_t CompactionOutputs::UpdateGrandparentBoundaryInfo(
const Slice& internal_key) {
// 初始化当前键跨越的边界数量为 0。
size_t curr_key_boundary_switched_num = 0;
// 获取祖父层文件列表。
const std::vector<FileMetaData*>& grandparents = compaction_->grandparents();
// 如果没有祖父文件(例如,输出到 L0 或最底层),则无需执行任何操作。
if (grandparents.empty()) {
return curr_key_boundary_switched_num;
}
// 获取用户键比较器。
const Comparator* ucmp = compaction_->column_family_data()->user_comparator();
// 移动 `grandparent_index_` 指向包含当前用户键的文件。
// 如果多个文件包含相同的用户键,请确保索引指向包含该键的最后一个文件。
while (grandparent_index_ < grandparents.size()) {
// 检查当前是否处于祖父文件之间的间隙中。
if (being_grandparent_gap_) {
// 如果当前键的用户键仍然小于下一个祖父文件的最小用户键,
// 则表示仍在间隙中,跳出循环。
if (sstableKeyCompare(ucmp, internal_key,
grandparents[grandparent_index_]->smallest) < 0) {
break;
}
// 当前键已进入 `grandparent_index_` 指向的祖父文件。
// 只有在处理过至少一个键后(`seen_key_` 为 true),才计算边界切换。
if (seen_key_) {
// 当前键跨越了一个边界(从间隙进入文件)。
curr_key_boundary_switched_num++;
// 将新进入的祖父文件的完整大小添加到重叠字节数中。
grandparent_overlapped_bytes_ +=
grandparents[grandparent_index_]->fd.GetFileSize();
// 增加当前输出文件跨越的总边界数。
grandparent_boundary_switched_num_++;
}
// 不再处于间隙中。
being_grandparent_gap_ = false;
} else { // 当前处于 `grandparent_index_` 指向的祖父文件内部。
// 比较当前键的用户键与当前祖父文件的最大用户键。
int cmp_result = sstableKeyCompare(
ucmp, internal_key, grandparents[grandparent_index_]->largest);
// 如果满足以下条件之一,则跳出循环(表示当前键仍在当前祖父文件范围内):
// 1. 当前键严格小于当前祖父文件的最大键。
// 2. 当前键等于当前祖父文件的最大键,并且:
// a) 这是最后一个祖父文件。
// b) 或者,当前键严格小于下一个祖父文件的最小键(确保 `grandparent_index_` 指向包含该键的最后一个文件)。
if (cmp_result < 0 ||
(cmp_result == 0 &&
(grandparent_index_ == grandparents.size() - 1 ||
sstableKeyCompare(ucmp, internal_key,
grandparents[grandparent_index_ + 1]->smallest) <
0))) {
break;
}
// 当前键已超出当前祖父文件的范围。
// 只有在处理过至少一个键后(`seen_key_` 为 true),才计算边界切换。
if (seen_key_) {
// 当前键跨越了一个边界(从文件进入间隙)。
curr_key_boundary_switched_num++;
// 增加当前输出文件跨越的总边界数。
grandparent_boundary_switched_num_++;
}
// 现在处于间隙中。
being_grandparent_gap_ = true;
// 移动到下一个祖父文件(或文件后的间隙)。
grandparent_index_++;
}
}
// 特殊处理第一个键 (`seen_key_` 为 false)。
// 如果第一个键直接落入某个祖父文件内部(而不是间隙),则计算其初始重叠字节数。
if (!seen_key_ && !being_grandparent_gap_) {
// 初始重叠应为 0。
assert(grandparent_overlapped_bytes_ == 0);
// 调用 GetCurrentKeyGrandparentOverlappedBytes 计算初始重叠。
grandparent_overlapped_bytes_ =
GetCurrentKeyGrandparentOverlappedBytes(internal_key);
}
// 标记已处理过至少一个键。
seen_key_ = true;
// 返回当前这个 `internal_key` 跨越的边界数量。
return curr_key_boundary_switched_num;
}4.1.1 UpdateGrandparentBoundaryInfo 函数的核心状态变量
该函数维护了几个关键的状态变量:
seen_key_: 是否已处理过至少一个键being_grandparent_gap_: 当前键是否位于祖父文件之间的间隙中grandparent_index_: 指向当前祖父文件数组中的位置索引grandparent_boundary_switched_num_: 当前输出文件已跨越的祖父边界总数grandparent_overlapped_bytes_: 与当前输出文件重叠的祖父文件总大小curr_key_boundary_switched_num: 当前的键跨越的祖父边界数量 (返回值)
4.1.2 图解 UpdateGrandparentBoundaryInfo 六种典型场景
按照函数处理 KEY 的数量,通过图解来详细分析 UpdateGrandparentBoundaryInfo 函数在六种不同场景下的行为:
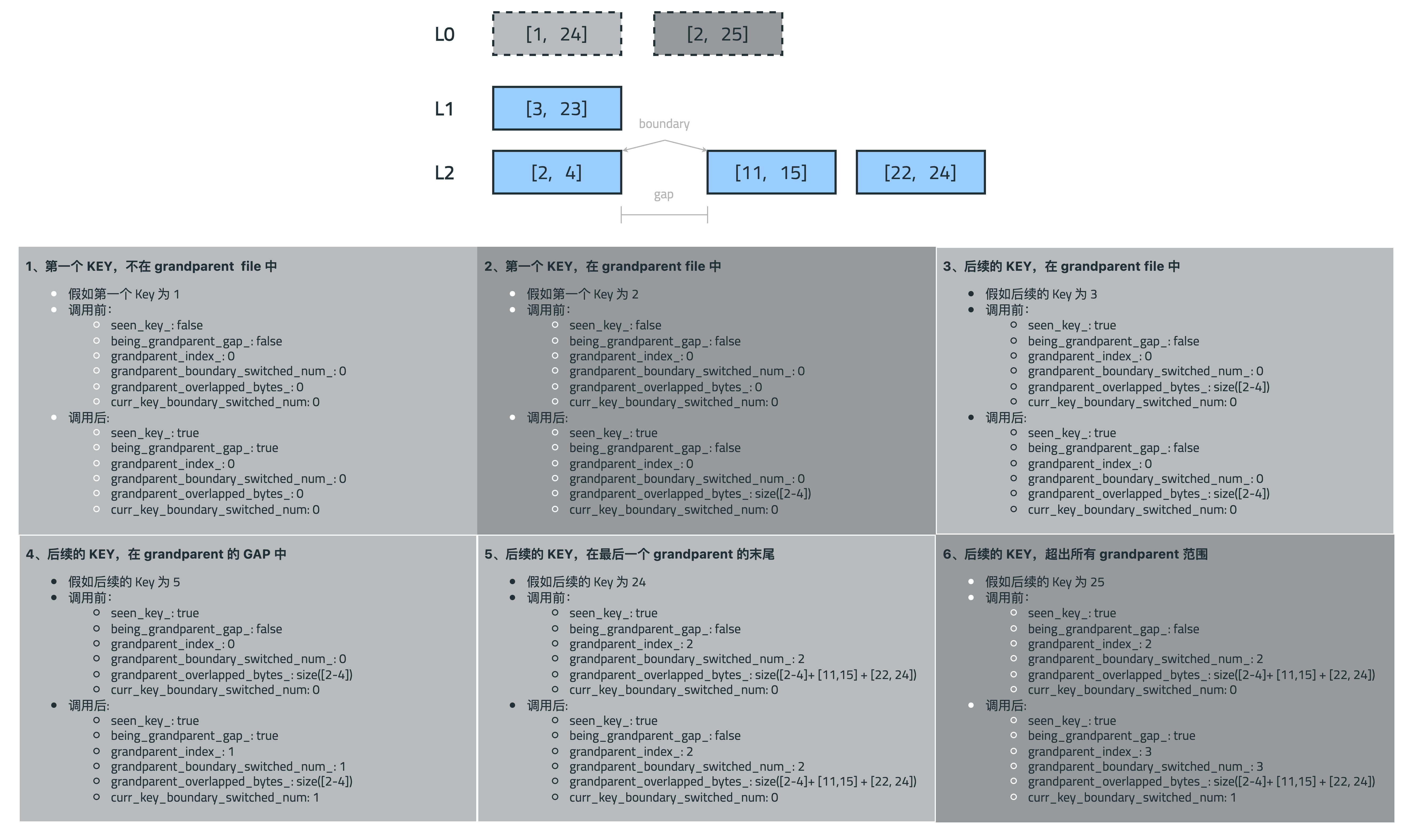
图中上方显示了三层文件:灰色为输入层文件(L 和 L+1),蓝色为祖父层文件(L+2)。使用两种 L 层的例子来覆盖所有的场景,以颜色深浅对应 L 层以及具体的场景。下面则详细展示了处理不同键时的状态变化。
1. 第一个 KEY,不在 grandparent file 中
情景:处理第一个键 (key=1),该键不在任何祖父文件范围内(位于间隙中)。
调用前:
seen_key_= falsebeing_grandparent_gap_= falsegrandparent_index_= 0(指向 [2, 4] 文件)grandparent_boundary_switched_num_= 0grandparent_overlapped_bytes_= 0
调用后:
seen_key_= truebeing_grandparent_gap_= true(从 false 变为 true,表示进入文件前的间隙)grandparent_index_= 0grandparent_boundary_switched_num_= 0grandparent_overlapped_bytes_= 0- 返回
curr_key_boundary_switched_num= 0
关键点:首次调用时不会计算边界切换,只是确定初始状态。由于键在间隙中,设置 being_grandparent_gap_ = true。
2. 第一个 KEY,在 grandparent file 中
情景:处理第一个键 (key=2),该键位于祖父文件 [2, 4] 范围内。
调用前:
seen_key_= falsebeing_grandparent_gap_= falsegrandparent_index_= 0grandparent_boundary_switched_num_= 0grandparent_overlapped_bytes_= 0
调用后:
seen_key_= truebeing_grandparent_gap_= falsegrandparent_index_= 0grandparent_boundary_switched_num_= 0grandparent_overlapped_bytes_= size([2, 4])- 返回
curr_key_boundary_switched_num= 0
关键点:首次调用且键在文件内时,计算并初始化 grandparent_overlapped_bytes_,但不增加边界切换计数。
3. 后续的 KEY,在 grandparent file 中
情景:处理后续键 (key=3),该键仍在同一个祖父文件 [2, 4] 范围内。
调用前:
seen_key_= truebeing_grandparent_gap_= falsegrandparent_index_= 0grandparent_boundary_switched_num_= 0grandparent_overlapped_bytes_= size([2, 4])
调用后:
- 所有值保持不变
- 返回
curr_key_boundary_switched_num= 0
关键点:键仍在同一文件中,没有跨越边界,所有状态保持不变。
4. 后续的 KEY,在 grandparent 的 GAP 中
情景:处理后续键 (key=5),该键已离开祖父文件 [2, 4],进入了文件间的间隙。
调用前:
seen_key_= truebeing_grandparent_gap_= falsegrandparent_index_= 0grandparent_boundary_switched_num_= 0grandparent_overlapped_bytes_= size([2, 4])
调用后:
seen_key_= truebeing_grandparent_gap_= truegrandparent_index_= 1grandparent_boundary_switched_num_= 1grandparent_overlapped_bytes_= size([2, 4])- 返回
curr_key_boundary_switched_num= 1
关键点:键跨越了文件边界(从文件到间隙),增加边界切换计数,但重叠字节数不变(因为只是离开文件,而非进入新文件)。
5. 后续的 KEY,在最后一个 grandparent 的末尾
情景:处理后续键 (key=24),该键位于最后一个祖父文件 [22, 24] 的末尾。
调用前:
seen_key_= truebeing_grandparent_gap_= falsegrandparent_index_= 2(指向 [22, 24] 文件)grandparent_boundary_switched_num_= 2grandparent_overlapped_bytes_= size([2,4]) + size([11,15]) + size([22,24])
调用后:
seen_key_= truebeing_grandparent_gap_= falsegrandparent_index_= 2grandparent_boundary_switched_num_= 2grandparent_overlapped_bytes_= size([2,4]) + size([11,15]) + size([22,24])- 返回
curr_key_boundary_switched_num= 0
关键点:当 key=24 恰好等于最后一个文件 [22, 24] 的 largest key 时,仍被视为在文件内,所有状态保持不变。
6. 后续的 KEY,超出所有 grandparent 范围
情景:处理后续键 (key=25),该键超出了所有祖父文件的范围。
调用前:
seen_key_= truebeing_grandparent_gap_= falsegrandparent_index_= 2(指向 [22, 24] 文件)grandparent_boundary_switched_num_= 2grandparent_overlapped_bytes_= size([2,4]) + size([11,15]) + size([22,24])
调用后:
seen_key_= truebeing_grandparent_gap_= true(从 false 变为 true,表示进入文件后的间隙)grandparent_index_= 3(从 2 增加到 3,指向文件列表结束后的位置)grandparent_boundary_switched_num_= 3(从 2 增加到 3,增加了一次边界切换)grandparent_overlapped_bytes_= size([2,4]) + size([11,15]) + size([22,24])- 返回
curr_key_boundary_switched_num= 1
关键点:键超出了最后一个文件范围,标记为进入间隙,增加边界切换计数和索引,但重叠字节数不变。
4.2 计算祖父层重叠文件大小
为了计算重叠字节数,RocksDB 实现了 GetCurrentKeyGrandparentOverlappedBytes 函数:
uint64_t CompactionOutputs::GetCurrentKeyGrandparentOverlappedBytes(
const Slice& internal_key) const {
if (being_grandparent_gap_) {
return 0; // 在间隙中,无重叠
}
uint64_t overlapped_bytes = 0;
const std::vector<FileMetaData*>& grandparents = compaction_->grandparents();
const Comparator* ucmp = compaction_->column_family_data()->user_comparator();
InternalKey ikey;
ikey.DecodeFrom(internal_key);
// 加上主要重叠文件的大小
overlapped_bytes += grandparents[grandparent_index_]->fd.GetFileSize();
// 查找所有边界重叠的文件
for (int64_t i = static_cast<int64_t>(grandparent_index_) - 1;
i >= 0 && sstableKeyCompare(ucmp, ikey, grandparents[i]->largest) == 0;
i--) {
overlapped_bytes += grandparents[i]->fd.GetFileSize();
}
return overlapped_bytes;
}该函数处理了一种特殊情况:当多个祖父文件有相同的边界键时,一个键可能与多个文件重叠。例如:
输出文件: [c...
祖父文件: [b, b] [c, c] [c, c] [c, d]在这种情况下,键 ‘c’ 可能与多个祖父文件重叠,函数会累加所有这些重叠文件的大小。
4.3 文件切分决策:ShouldStopBefore 函数
在 compaction 过程中,RocksDB 需要决定何时应该 “ 切割 “ 一个正在写入的输出 SST 文件。这是由 CompactionOutputs::ShouldStopBefore 函数实现的:
// 决定是否应在添加来自 `c_iter` 的键之前完成(停止写入)当前的输出文件。
bool CompactionOutputs::ShouldStopBefore(const CompactionIterator& c_iter) {
// 断言迭代器有效并指向一个键。
assert(c_iter.Valid());
// 从迭代器获取内部键 (user_key + seq + type + ts)。
const Slice& internal_key = c_iter.key();
// 存储在考虑当前键 *之前* 的重叠大小。稍后用于查看重叠 *增加* 了多少。
const uint64_t previous_overlapped_bytes = grandparent_overlapped_bytes_;
// 初始化变量以跟踪边界交叉和 TTL 决策。
size_t num_grandparent_boundaries_crossed = 0;
bool should_stop_for_ttl = false;
// 更新祖父文件信息和TTL状态
if (compaction_->output_level() > 0) {
// 根据当前键更新祖父文件跟踪状态。返回此键跨越的祖父文件边界数量。
num_grandparent_boundaries_crossed =
UpdateGrandparentBoundaryInfo(internal_key);
// 检查当前键是否根据 TTL 规则触发文件切割
should_stop_for_ttl = UpdateFilesToCutForTTLStates(internal_key);
}
// 基本检查 - 如果没有活动的TableBuilder,不能切割文件
if (!HasBuilder()) {
return false;
}
// 如果 TTL 逻辑决定需要切割文件,立即执行
if (should_stop_for_ttl) {
return true;
}
// 分区器检查 - 询问自定义SST分区器是否应切割文件
if (partitioner_ && partitioner_->ShouldPartition(PartitionerRequest(
last_key_for_partitioner_,
c_iter.user_key(),
current_output_file_size_
)) == kRequired) {
return true; // 分区器要求切割
}
// 级别特定检查 - L0层通常不按大小或祖父重叠启发式分割
if (compaction_->output_level() == 0) {
return false;
}
// 大小检查 - 如果达到最大文件大小,则强制切割
if (current_output_file_size_ >= compaction_->max_output_file_size()) {
return true;
}
// RoundRobin分割检查 - 针对kRoundRobin压缩优先级
if (local_output_split_key_ != nullptr && !is_split_) {
// 当下一个键大于或等于游标时发生分割
if (icmp->Compare(internal_key, local_output_split_key_->Encode()) >= 0) {
is_split_ = true;
return true;
}
}
// 祖父文件边界启发式逻辑 (仅适用于当前键跨越了祖父边界时)
if (num_grandparent_boundaries_crossed > 0) {
// 启发式1:防止大型未来Compaction
if (grandparent_overlapped_bytes_ + current_output_file_size_ >
compaction_->max_compaction_bytes()) {
return true;
}
// 启发式2:隔离可跳过的祖父文件(动态大小)
const size_t num_skippable_boundaries_crossed =
being_grandparent_gap_ ? 2 : 3;
if (compaction_->immutable_options()->compaction_style ==
kCompactionStyleLevel &&
compaction_->immutable_options()->level_compaction_dynamic_file_size &&
num_grandparent_boundaries_crossed >=
num_skippable_boundaries_crossed &&
grandparent_overlapped_bytes_ - previous_overlapped_bytes >
compaction_->target_output_file_size() / 8) {
return true;
}
// 启发式3:接近目标大小时的预先切割(动态大小)
if (compaction_->immutable_options()->compaction_style ==
kCompactionStyleLevel &&
compaction_->immutable_options()->level_compaction_dynamic_file_size &&
current_output_file_size_ >=
((compaction_->target_output_file_size() + 99) / 100) *
(50 + std::min(grandparent_boundary_switched_num_ * 5,
size_t{40}))) {
return true;
}
}
// 如果以上条件均未满足,则暂时不切割文件
return false;
}让我们详细分析 ShouldStopBefore 函数中可能提前结束当前输出文件的核心逻辑:
4.3.1 TTL boundary cut
TTL boundary cut 是一个独立的提前切分来源。FillFilesToCutForTtl() 会先从 lower input level 中筛选候选文件:要求 compaction style 为 leveled、compaction_pri 为 kMinOverlappingRatio、ttl != 0、当前 compaction 不是 bottommost,并且文件的 oldest_ancester_time 早于 current_time - ttl / 2。同时,为了避免过多小文件,候选文件大小还需要大于 target_file_size_base / 2。
当当前 key 进入或离开这些候选文件的 key range 时,UpdateFilesToCutForTTLStates() 会让 ShouldStopBefore() 在当前 key 前结束输出文件。
4.3.2 基本大小限制
当文件大小达到配置的最大输出文件大小时,强制切分文件:
if (current_output_file_size_ >= compaction_->max_output_file_size()) {
return true; // 达到最大大小,必须切分文件
}4.3.3 祖父层文件边界启发式
在 compaction 过程中,RocksDB 会跟踪当前处理的键与祖父层(L+2 层)文件的关系。当键跨越祖父文件边界时,会触发一系列复杂的启发式规则:
4.3.3.1 防止未来 Compaction 过大
if (grandparent_overlapped_bytes_ + current_output_file_size_ >
compaction_->max_compaction_bytes()) {
return true; // 切分文件以避免将来 compaction 过大
}这个分支只在当前 key 跨过祖父层文件边界时检查。它把当前输出文件已经覆盖到的祖父层文件大小与当前输出文件大小相加,如果超过 max_compaction_bytes,就提前切分。它的目的不是把当前文件切到某个目标大小,而是避免这个输出文件在未来参与下一层 compaction 时拖入过多祖父层数据。
4.3.3.2 隔离可跳过的祖父文件
const size_t num_skippable_boundaries_crossed = being_grandparent_gap_ ? 2 : 3;
if (compaction_->immutable_options()->compaction_style == kCompactionStyleLevel &&
compaction_->immutable_options()->level_compaction_dynamic_file_size &&
// 是否跨越了足够多的边界以可能隔离一个文件?
num_grandparent_boundaries_crossed >= num_skippable_boundaries_crossed &&
// 新增加的重叠(刚刚开始重叠的祖父文件的大小)是否合理地大?
grandparent_overlapped_bytes_ - previous_overlapped_bytes >
compaction_->target_output_file_size() / 8) {
return true; // 切割文件以隔离祖父文件
}这个分支是分析小 SST 时最需要关注的逻辑之一。它在当前 key 跨过足够多祖父层边界,并且新增覆盖的祖父层文件大于 target_output_file_size() / 8 时切分当前输出文件。这样可以让未来 compaction 跳过中间那段祖父层文件,代价是当前层可能产生更小的 SST。考虑以下场景:
L1: [1, 21] <- 当前正在合并的文件
L2: [3, 23] <- 当前正在合并的文件
L3: [2, 4] [11, 15] [22, 24] <- 祖父层(L+2)文件如果不进行切分,L2 层的输出将是 [1,3, 21,23],与 L3 层的三个文件都有重叠。但是,如果在跨越 L3 中间文件 [11, 15] 时切分,L2 的输出将变为两个文件:[1,3] 和 [21,23],那么未来这两个文件分别 compact 到 L3 时,可以跳过中间的 [11, 15] 文件,从而减少重复读写。
RocksDB 会检查以下条件:
- 使用 Level 压缩风格
- 启用了动态文件大小调整
- 当前键跨越的边界足够多(通常是完整跨越了一个文件)
- 刚跨越的祖父文件足够大(>= 目标大小的 1/8)
当所有这些条件都满足时,会切分当前输出文件。
4.3.3.3 动态文件大小预分割
if (compaction_->immutable_options()->compaction_style == kCompactionStyleLevel &&
compaction_->immutable_options()->level_compaction_dynamic_file_size &&
current_output_file_size_ >=
// 计算动态阈值
((compaction_->target_output_file_size() + 99) / 100) *
(50 + std::min(grandparent_boundary_switched_num_ * 5, size_t{40}))) {
return true; // 在边界处预先切割文件
}dynamic pre-cut 也是祖父层边界上的提前切分。它要求当前 key 正好跨过祖父层边界,并且当前输出文件大小达到动态阈值。
阈值计算公式:
阈值 = 目标大小 × (50% + min(已跨越边界数 × 5%, 40%))这意味着:
- 初始阈值是目标文件大小的 50%
- 每跨越一个祖父边界,阈值增加 5%
- 阈值上限是目标文件大小的 90%
因此,它可能在文件尚未达到目标大小时切分,但不会在任意 key 位置切分,只会借助祖父层边界。
五、工作负载如何增加小 SST 出现概率
上面的机制说明了 RocksDB 如何避免单个输出文件过大,也说明了某些提前切分条件可能让输出文件在尚未达到常规目标大小时结束。小文件是否大量出现,还取决于工作负载的 key 分布、写入节奏、各层文件边界以及实际触发的 compaction 路径。下面的例子展示了一类生产环境现象:数据量不到 300GB,但 SST 文件数量达到十万级;full compaction 后文件数量下降到数千级。
$> find /data/kv-datanode/dbs/[0-9]* -type f -name "*.sst" | wc -l
1470845.1 “隔离可跳过的祖父文件” 的 Corner Case
首先回顾“隔离可跳过的祖父文件”启发式算法 的代码注释明确指出:对于随机数据集(无论是均匀分布还是偏斜分布),很少会触发这个条件,但如果用户添加两个没有重叠的不同数据集,这种情况就很可能发生。
// ...
// For random datasets (either evenly distributed or skewed), it rarely
// triggers this condition, but if the user is adding 2 different datasets
// without any overlap, it may likely happen.
const size_t num_skippable_boundaries_crossed =
being_grandparent_gap_ ? 2 : 3;
if (compaction_->immutable_options()->compaction_style == kCompactionStyleLevel &&
compaction_->immutable_options()->level_compaction_dynamic_file_size &&
num_grandparent_boundaries_crossed >= num_skippable_boundaries_crossed &&
grandparent_overlapped_bytes_ - previous_overlapped_bytes >
compaction_->target_output_file_size() / 8) {
return true; // 切割文件以隔离祖父文件
}5.2 雪花算法与小文件问题
雪花算法(Snowflake ID)是一种流行的分布式 ID 生成算法,常被业务用作 RocksDB key 的一部分。通常由以下部分组成:
+----------------------+----------------+---------------+-----------+
| 时间戳(41位) | 机器ID(10位) | 序列号(12位)| 预留(1位)|
+----------------------+----------------+---------------+-----------+其主要特性包括:
- 时间有序性:ID 中包含时间戳,使得生成的 ID 大体上按时间递增
- 局部单调:在单台机器上,生成的 ID 严格单调递增
- 可能存在间隙:时间跳跃或机器重启时会产生 ID 间隙
- 不同机器 ID 区分:不同机器生成的 ID 在特定位上有差异
当雪花 ID 或类似时间有序 ID 出现在 RocksDB key 中时,数据在 key space 中可能呈现按时间段聚集的分布。这个特征本身不会直接触发 ShouldStopBefore() 的某个分支,但它可能改变 compaction 过程中遇到祖父层文件边界的方式:
- 时间有序性:同一生成器上的 ID 大体随时间递增,写入数据更容易按时间段聚集
- 键空间间隙:如果写入在不同时间段之间存在停顿,key space 中可能出现低密度区间
- 边界机会增加:当 compaction 输入跨过这些区间时,更可能遇到祖父层文件的开始或结束边界
- 是否切分仍取决于条件:最终是否触发 skippable grandparent cut 或 dynamic pre-cut,还要看跨越边界数量、祖父文件大小、当前输出文件大小和目标文件大小等运行时状态
5.3 流量峰值特征与小文件问题
当业务有定期(例如:每小时触发的任务)的流量峰值时,可能增加 “ 隔离可跳过的祖父文件 “ 启发式策略获得切分机会的概率,特别是当使用雪花算法等时间有序 ID 作为键时。这种影响主要体现在以下几个方面:
- 时间间隙效应: 当业务每小时流量峰值可能导致数据写入呈现明显的 “ 块状 “ 分布:
峰值期间:大量数据密集写入
峰值之间:数据写入稀疏或几乎停止
写入模式会在键空间中产生规律性的 “ 高密度区 “ 和 “ 低密度区 “,特别是使用时间相关的键(如雪花 ID)时,数据在键空间分布上会呈现明显的 “ 台阶状 “。
- 边界切分频率增加
- 增加边界跨越次数:当 compaction 处理从一个流量峰值时段到另一个时段的数据时,由于键值间隙的存在,更容易满足
num_grandparent_boundaries_crossed >= num_skippable_boundaries_crossed的前置条件 - 文件边界自然对齐:随着数据经历多次 compaction,祖父层文件的边界可能与这些流量峰值的时间边界部分对齐
- 增加边界跨越次数:当 compaction 处理从一个流量峰值时段到另一个时段的数据时,由于键值间隙的存在,更容易满足
- 周期性峰值的累积效应: 这种影响还会随着系统运行时间而累积:
- 第一阶段:初始写入与 L0 形成。每小时峰值写入会在 L0 层形成多个文件,每个峰值期间的文件之间存在时间和键空间上的间隙。
- 第二阶段:初次下沉 compaction。当这些 L0 文件下沉到 L1 时,启发式算法可能检测到峰值间隙,并在这些位置切分文件,使 L1 层文件边界与峰值边界部分对齐。
- 第三阶段:多层级传播。随着数据继续下沉,L2、L3 等底层的文件边界可能继续保留这些周期性流量峰值带来的 key space 分段特征。
5.4 验证 skippable grandparent cut 是否触发
使用 objdump 获取程序 ShouldStopBefore 汇编代码
$> objdump -dC kv-datanode |grep ShouldStopBefore -A 500“ 隔离可跳过的祖父文件 “ 分支的汇编代码如下:
00000000009580d0 <rocksdb::CompactionOutputs::ShouldStopBefore(rocksdb::CompactionIterator const&)>:
...
// 如果标志为 true (假设满足 style 和 dynamic_size 条件):
// 计算并比较 overlap delta: grandparent_overlapped_bytes_ - previous_overlapped_bytes > target_output_file_size() / 8
95820c: 48 8b 40 10 mov 0x10(%rax),%rax ; 加载 this->target_output_file_size_ (偏移 0x10) 到 %rax。
958210: 48 2b 55 98 sub -0x68(%rbp),%rdx ; %rdx = 当前 grandparent_overlapped_bytes_ (来自 9581c0) - 初始 grandparent_overlapped_bytes_ (来自栈 -0x68(%rbp))。即 overlap delta。
958214: 48 89 c7 mov %rax,%rdi ; %rdi = target_output_file_size_。
958217: 48 c1 ef 03 shr $0x3,%rdi ; %rdi = target_output_file_size_ / 8。
95821b: 48 39 fa cmp %rdi,%rdx ; 比较 overlap delta (%rdx) 与 target_output_file_size_ / 8 (%rdi)。
95821e: 0f 87 98 00 00 00 ja 9582bc <...> ; 如果 overlap delta > target_output_file_size_ / 8,跳转到 9582bc (返回 true)。 **即,代码 326 行 "隔离可跳过的祖父文件"分支 的 `return true;`**
...使用 bpftrace 工具在汇编指令前插入探测点
#!/usr/bin/env bpftrace
BEGIN {
printf("开始监控 ShouldStopBefore 函数的分支执行情况\n\n");
@calls = 0;
// 分支计数器初始化
@branch_condition_checked = 0; // 到达比较指令的次数
@branch_condition_true = 0; // 条件为true的次数
}
// 函数入口点
uprobe:kv-datanode:0x9580d0
{
@calls++;
}
// 监控 grandparent_overlapped 比较指令执行点
uprobe:kv-datanode:0x95821b
{
@branch_condition_checked++;
$dx = reg("dx");
$di = reg("di");
if ($dx > $di) {
@branch_condition_true++;
}
}
interval:s:5 {
time("当前时间: %H:%M:%S\n");
printf("当前统计:\n");
printf("函数调用总次数: %d\n", @calls);
printf("条件比较执行次数: %d\n", @branch_condition_checked);
printf("条件比较为 True 次数: %d\n\n", @branch_condition_true);
}
END {
printf("\n最终统计:\n");
printf("函数调用总次数: %d\n", @calls);
printf("条件比较执行次数: %d\n", @branch_condition_checked);
printf("条件比较为 True 次数: %d\n\n", @branch_condition_true);
}在相关机器上执行探测,结果如下
$> bpftrace -p 379970 /data/scripts/datanode_probe.bt
Attaching 5 probes... 开始监控 ShouldStopBefore 函数的分支执行情况
^C
最终统计:
函数调用总次数: 40242437
条件比较执行次数: 69
条件比较为 True 次数: 63
@branch_condition_checked: 69
@branch_condition_true: 63
@calls: 40242437这个 probe 验证的是 grandparent_overlapped_bytes_ - previous_overlapped_bytes > target_output_file_size() / 8 对应的 skippable grandparent cut 分支。它能说明 skippable grandparent cut 是否命中,但不能覆盖 TTL boundary cut 和 max_compaction_bytes overlap cut。
六、统计指标
rocksdb.live-sst-files-size
含义:返回当前列族中所有活跃 (live) 的 SST 文件的总大小(字节)。
rocksdb.live-sst-files-size:0rocksdb.num-files-at-level<N>
含义:返回当前列族指定层级 N 中 SST 文件的数量。
rocksdb.num-files-at-level0:1
rocksdb.num-files-at-level1:5
rocksdb.num-files-at-level12:12
...rocksdb.levelstats
含义:提供一个简洁的表格,显示每个层级的文件数量和总大小。
输出格式:
Level Files Size(MB)
--------------------
0 1 0.01
1 5 2.31
2 12 10.22
...七、总结
从小 SST 的角度看,ShouldStopBefore() 中最值得关注的是几类提前切分来源:TTL boundary cut 按时间和文件边界切分,partitioner 按用户自定义规则切分,RoundRobin 按 compact cursor 切分,max_compaction_bytes overlap cut 按祖父层重叠规模切分,skippable grandparent cut 和 dynamic pre-cut 则按祖父层文件边界切分。本文重点讨论的“小文件”问题,主要来自这些条件在文件尚未达到常规目标大小时提前结束当前输出 SST。
1. L0 层(写入/刷盘层)
Memtable 刷盘生成:
- 文件大小 ≈
write_buffer_size×min_write_buffer_number_to_merge。例如,write_buffer_size=64MB,min_write_buffer_number_to_merge=2,则单个 L0 文件约为 128MB - 实际大小可能略小(memtable 未满、压缩等因素)
- 文件大小 ≈
Intra-L0 Compaction 生成:
ShouldStopBefore()不进入后续大小判断、RoundRobin split 和祖父层边界启发式逻辑
2. 非 L0、非底层(如 L1/L2/…/Lmax-1)
- 目标文件大小:
- 由
target_file_size_base和target_file_size_multiplier计算 - 例如,L1: 64MB,L2: 128MB,L3: 256MB(假设 multiplier=2)
- 由
- 实际文件大小:
- 动态文件大小启用时,最大可达目标大小的 2 倍(如 128MB、256MB、512MB 等)
- 受 compaction 启发式(如祖父层边界)影响,部分文件可能较小
3. 最底层(Bottommost Level)
max_output_file_size_等于target_output_file_size_- 不使用非底层的 2 倍动态上限
- 本文重点分析的祖父层边界启发式主要发生在非 bottommost 输出场景
理解这些机制有助于我们更好地调整 RocksDB 的配置,使其在特定的工作负载下获得最佳性能,并在读性能、写放大、空间使用和管理开销之间找到适合自己应用场景的平衡点。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/05-04-2025/rocksdb-sst-file-size.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!