
SIYING DONG, SHIVA SHANKAR P, SATADRU PAN, ANAND ANANTHABHOTLA, DHANABAL EKAMBARAM, ABHINAV SHARMA, SHOBHIT DAYAL, NISHANT VINAYBHAI PARIKH,YANQIN JIN,ALBERT KIM,SUSHIL PATIL,JAY ZHUANG, SAM DUNSTER, AKANKSHA MAHAJAN, ANIRUDH CHELLURI, CHAITANYA DATYE, LUCAS VASCONCELOS SANTANA, NITIN GARG, 和 OMKAR GAWDE,Meta, USA
正如业界的普遍趋势,Meta 数据中心也在将数据从本地直连 SSD 迁移到云存储。我们扩展了 RocksDB [26],这是一款广泛使用、为本地 SSD 设计和构建的开源存储引擎,使其能够利用分离式存储。RocksDB 的设计(如其数据和日志文件的访问模式)使得追加写分布式文件系统成为理想的底层存储。在 Meta,我们基于 Tectonic 文件系统 [35] 构建了存算分离式 RocksDB,Tectonic 之前主要用于数据仓库和大对象存储。我们发现元数据开销和尾延迟是 Tectonic 的主要性能瓶颈,并针对性地进行了优化。我们通过对 RocksDB 核心引擎的通用和定制优化,提升了可靠性、性能及其他需求。我们还深入理解了运行在 RocksDB 上的应用所面临的常见挑战,并据此做了增强。这一架构使 RocksDB 能够适应更分布式的架构以提升性能。
CCS 概念: • 信息系统 → DBMS 引擎架构;分布式存储。
附加关键词和短语: 分离式存储,日志结构合并树(LSM-tree),rocksdb,分布式文件系统
1 引言
RocksDB [26] 是一款在 Meta 内外广泛使用的开源存储引擎。历史上,它主要用于本地 SSD 存储数据。然而,分离式存储(RocksDB 通过网络访问底层存储系统)可以通过让 CPU 和存储按需独立配置来实现更高的效率。
几年前,几乎没有 RocksDB 应用能承受将存储放在远程网络上的代价,但近年来网络带宽迅速提升。例如,十年前我们还在将主机从 1Gbps 网卡升级到 10Gbps,而现在至少是 25Gbps,常见的还有 50Gbps 或 100Gbps。另一方面,大多数用户对磁盘 IO 带宽的需求与十年前相似。这一趋势使得分离式存储对越来越多的应用具有吸引力。尽管网络仍是瓶颈,但许多场景受限于空间而非 IOPS,在这种情况下,降低 IOPS 可能是可以接受的权衡。此外,如果分离式存储实现为可靠服务,用户可以以多种方式利用其可靠性,例如提升区域内可用性、减少跨区域数据传输。因此,我们开始设计一种运行在分离式存储之上的存储引擎方案。
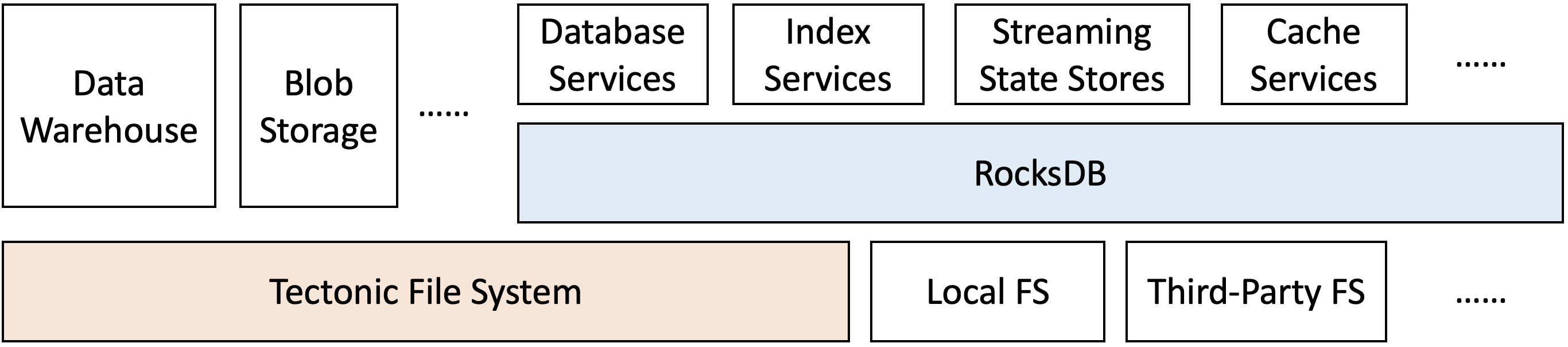
图 1. 不同的使用 RocksDB 的应用程序可以在分离式存储上运行。
在 Meta,我们选择继续使用 RocksDB,但将数据存储在分布式文件系统而非本地 SSD 上。我们之所以坚持使用 RocksDB,是因为其主要数据结构——日志结构合并树(LSM-tree)[34]——能够最大限度地减少空间占用(这是常见瓶颈),并且已被证明对分布式文件系统高效 [21]。LSM-tree 生成的数据文件一旦创建即不可变。托管存储服务还能提供容错能力,RocksDB 应用可以多种方式利用这一点,比如减少数据中心内的故障切换时间。由于 RocksDB 已服务于多种服务,扩展其支持的存储类型自然能让这些服务运行在分离式存储上,如图 1 所示;我们的经验表明,这样做可以获得令人满意的性能。Tectonic 文件系统 [35] 是一种最初为数据仓库和大对象存储构建的追加写分布式文件系统,符合所需的存储特性。我们决定让 RocksDB 运行在 Tectonic 之上。
要让 RocksDB 应用运行在分布式文件系统(DFS)上,我们面临四大挑战(§3):a)分离式存储引入了额外的网络跳数,通常导致延迟较本地 SSD 倒退;b)只有数据以容错方式存储时,托管存储系统的优势(如快速故障切换)才能实现,但增加冗余会带来额外的存储和 SSD 耗损开销;c)在分离式存储下,多个节点可访问同一 RocksDB 目录的文件,发生故障切换时,必须保证前一节点无法再修改数据;d)RocksDB 库需要针对远程 IO 行为(故障、超时等)与本地 IO 行为做出不同响应。第 4 节介绍了我们对这些问题的解决方案。
在追加写分布式文件系统上运行基于 LSM-tree 的数据库引擎并非新鲜事,但我们认为我们的经验和收获在多个方面具有独特性。首先,我们证明了 RocksDB 可以同时支持本地和存算分离模式:即使存算分离模式的性能不及本地,但对于 Meta 内大量 RocksDB 应用来说已足够(§5)。
其次,我们分享了将一个为机械硬盘、主要用于数据仓库和大对象存储的分布式文件系统转型为服务 RocksDB 的经验(§8)。我们认为这种转型是常见模式,这里的经验具有广泛适用性。
最后,我们还分享了 RocksDB 应用常见挑战及其解决方案。我们以 Meta 内成熟数据库服务 ZippyDB [15] 为案例,介绍其如何解决非 RocksDB 文件、构建新副本、质量验证和文件垃圾回收等问题(§6)。据我们所知,类似经验尚未有公开分享。
凭借 RocksDB 的广泛应用,我们的经验对那些考虑将生产环境 RocksDB 从本地迁移到分离式存储的用户具有参考价值。
2 背景与动机
本节将概述 RocksDB 和 Tectonic,并介绍在 Tectonic 上运行 RocksDB 的动机。
2.1 RocksDB
RocksDB 是一款被多种数据服务广泛使用的开源数据库存储引擎。它主要用于 SSD 存储数据,但也有用户让 RocksDB 存储在机械硬盘或基于内存的文件系统上。统一的引擎为不同场景带来了可靠性、性能和可管理性等优势。
RocksDB 采用日志结构合并树(LSM-tree)[34] 实现。每当数据写入 RocksDB 时,数据首先被缓存在内存中,并写入磁盘上的预写日志(WAL)。数据随后会被刷新到磁盘上的有序字符串表(SST)数据文件中。每个 SST 文件以有序方式存储数据,并划分为多个块。热点块会被缓存在基于内存的块缓存中以减少 I/O。一旦写入,SST 文件即不可变。
SST 文件经常通过合并(compaction)过程被合并生成新的一组 SST 文件。在此过程中,被删除和被覆盖的数据会被移除,新的 SST 文件会针对读取性能和空间效率进行优化。由于每个 SST 文件中的键都是有序的,因此合并过程中的读写都是顺序进行的。写入可以使用任意大小的缓冲区进行缓冲,因为合并过程输出的 SST 文件在合并完成前不会被读取。通常,大部分对存储系统的写入都是由合并过程完成的。
2.2 为什么选择分离式存储?
基于闪存的 SSD 在 Meta 的各类服务中被广泛使用。最初,SSD 总是以本地方式使用,数据库服务器通过直连 PCI-e 访问 SSD 数据。这种架构让数据库服务器能够充分利用 SSD 的高吞吐和低延迟特性,至今仍适用于许多应用。但这种架构可能导致资源浪费,并增加了服务管理的难度。
在本地 SSD 架构下,主机内的 CPU 和存储资源往往不均衡。[26] 此外,一些用户由于闪存擦写预算或读取带宽限制,无法用满所有空间,而另一些用户虽然用满了空间,但也会浪费部分 I/O 或擦写周期。此外,每个服务都需要预留足够的缓冲和冗余空间,但大多数时间这些空间并未被使用。
如果计算与存储分离,存储可以按需从共享池中分配。未用空间可以共享,因此只需为缓冲和冗余预留更小比例的总空间。CPU 也可以更灵活地在数据库间调度和迁移,因为无需数据拷贝。这种快速的 CPU 配置让用户能够以更高的 CPU 利用率配置主机。结果,分离式存储让用户能够最大化整体 CPU 和存储利用率。使用分布式文件系统进行存算分离的更多好处见 §2.5。
2.3 为什么仍然选择 RocksDB?
我们没有选择构建或使用其他存储引擎,而是决定继续使用 RocksDB,原因如下。首先,即使采用了分离式存储,许多场景的瓶颈并非 I/O,而是空间占用。RocksDB 优秀的空间效率特性 [25] 同样适用于存算分离架构。
其次,统一的存储引擎支持本地和分离式存储,使迁移更容易,并允许两种模式长期共存,便于随时切换。
第三,一个同时支持本地和分离式存储的简单引擎意味着未来的改进只需在同一处实现,便可同时惠及两种模式。这对 RocksDB 这样流行的开源项目尤其有益,外部研究者也能利用这些改进。
最后,我们认为 RocksDB 的主数据结构 LSM-tree 非常适合分离式存储。
2.4 为什么选择 Tectonic 文件系统?
我们最初尝试构建存算分离方案时,聚焦于远程块设备。我们使用 ATA over Ethernet(AoE)或网络块设备(NBD)将远程磁盘连接到计算节点,提供标准本地访问的假象。这种简单架构实现了分离式存储,但我们发现它无法充分发挥潜力。由于不支持精简配置,效率提升有限。此外,存储节点或网络故障处理困难,服务拥有者也觉得这种系统难以运维。
为了解决上述方案的局限,我们探索了包括 NFS 和分布式可靠块设备在内的多种方案。然而,NFS 过于复杂,难以高效利用;而块设备接口下,不同主机间的数据共享也很困难。我们意识到,通用的分布式块设备或文件系统过于泛化,可能错失针对性优化机会,从而限制了系统的潜力。RocksDB 的数据和日志文件采用顺序写入,写入后即不可变。任何允许随机写的方案都不可避免地引入额外开销和复杂性。假设数据块不可变的文件系统能实现更高效率,这正是 Tectonic 文件系统的设计假设。因此我们决定以 RocksDB 运行在 Tectonic 上为起点,逐步演进方案。Tectonic 是 Meta 的艾字节(EB)级分布式文件系统,最初为数据仓库和大对象存储场景设计 [35]。它提供类似 Hadoop 文件系统(HDFS)的分层文件系统 API,大多数云服务商也有兼容的存储方案。在很多方面,我们的设计选择得到了前人系统的验证,如 BigTable[21]、HBase[6] 和 Spanner[22],它们都是基于追加写分布式文件系统的数据库。
不过,我们为 RocksDB 支持分离式存储的方式,使其可以运行在大多数分布式文件系统和对象存储系统之上,因此我们的工作具有广泛适用价值。原则上,我们需要如下 API 原语:a)数据以文件(或称对象、blob)为单位分组,文件名由用户指定;b)文件以追加写方式构建,数据可通过文件偏移读取;c)文件可分组到目录(或桶)中。我们在 §8 讨论了如何让存储系统在效率和易用性上达到满意水平的经验。
关于 Tectonic 文件系统的更多细节见 [35]。这里仅强调部分方面,帮助读者理解后续章节中我们提出的优化。Tectonic 中的数据通过冗余(纠删码或副本)实现持久性。Tectonic 文件由多个块组成。每个块的数据片段(以及若采用纠删码则包括校验片段)被存储在不同故障域的独立存储节点上,这样即使少量节点失效,数据也能从其他片段重建。Tectonic 的元数据层存储了目录到文件列表、文件到块列表、块到数据片段列表等多种映射。Tectonic 客户端库(在本例中运行于 RocksDB 库内部)负责协调与元数据和存储节点的 RPC 调用,管理数据片段的存储。
2.5 使用 Tectonic 的额外好处
如上所述,分离式存储带来了更好的资源利用率和 CPU、存储的独立扩展能力。使用 Tectonic 作为分离式存储还带来以下额外好处:
- 减少副本数量。使用 RocksDB 的应用需要提供高可用性保障,并能容忍各种故障。Tectonic 能确保常见故障场景(主机、机架或电源域故障)下的数据可用性。这种可用性提升让部分应用可以减少所需副本数。在许多情况下,应用可以将副本数从三份降至两份,或从五份降至三份,同时维持同等可用性。
- 快速故障切换。应用还可以依赖 Tectonic 快速从单主机故障中恢复。当服务将数据存储在本地 SSD 上时,主机故障可能导致数 TB 数据副本数不足,必须快速重建副本以避免永久性数据丢失。Tectonic 的容错特性允许应用在无需数据拷贝的情况下恢复(§6.2)。
- 简化存储管理。管理 SSD 并非易事,尤其对小团队而言。许多 RocksDB 用户希望避免这类复杂性,因此选择专用存储服务来屏蔽所有问题。例如,Tectonic 会自动将副本分布在不同电源故障域,应用天然获得大规模电源故障的保护。
- 存储共享。Tectonic 允许多台主机访问同一组文件。这使得备份、合并、校验等后台操作可以卸载到独立层(§7),也支持快速数据克隆。
2.6 何时不宜存算分离
尽管存算分离带来诸多好处,RocksDB 应用仍需权衡多种因素。a)RocksDB 在 Tectonic 上的查询延迟和吞吐仍有性能差距(§5),应用需验证能否容忍性能下降。b)为保证持久性,Tectonic 需要对数据做一定冗余,通常会使存储使用量增加 20% 以上,实际配置常高达 50%。c)Tectonic 系统复杂,依赖较多。对大多数应用不是问题,但某些原始服务可能要求依赖极少。例如,Tectonic 的元数据服务本身就难以运行在 RocksDB on Tectonic 上。
3 架构概览与主要挑战
本节将介绍 RocksDB 存算分离架构的高层概览,并描述需要应对的一些挑战。
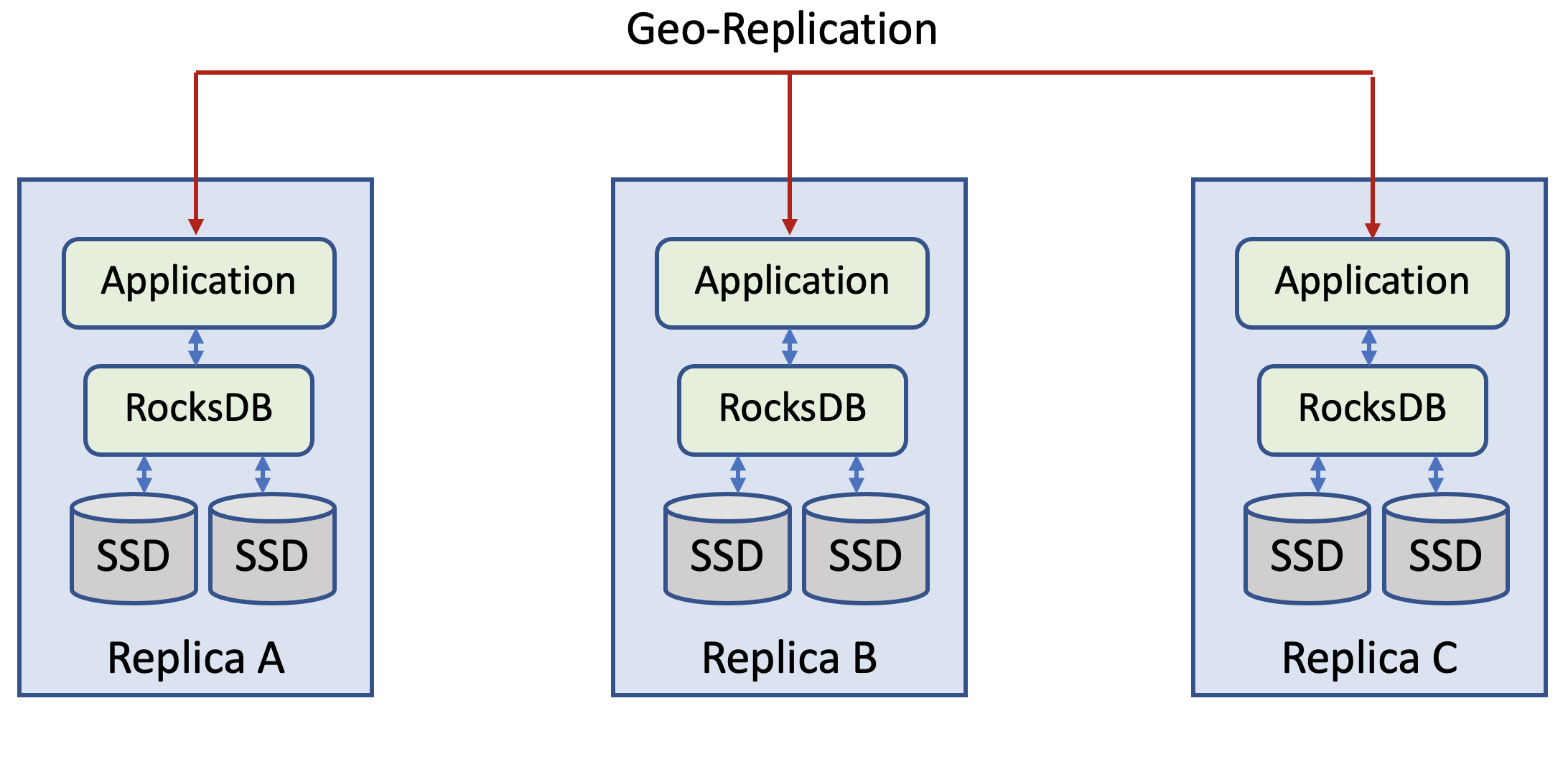
图 2. 在本地 SSD 上使用 RocksDB 的典型服务。
3.1 架构
图 2 展示了存算分离前 Meta 内典型数据服务的架构,图 3 展示了存算分离后的对应架构。
Tectonic 集群是数据中心区域内的,因此应用通常需要继续使用自身的地理复制逻辑,每个副本都将数据存储在数据中心内的 Tectonic 集群上。如果计算节点发生故障或需要负载均衡,另一台计算主机会接管并在 Tectonic 上操作同一份数据。
让 RocksDB 运行在 Tectonic 上所需的核心变更很简单。首先,为了支持 Tectonic 文件的读写,需要开发一个新插件,实现 RocksDB 的存储接口(§6.1),使 RocksDB 能与 Tectonic 协作。其次,RocksDB 用户需要通过共享的 Tectonic 命名空间管理文件,而不是使用独占的本地文件系统。不同应用可以在集群中拥有各自逻辑隔离的命名空间。为了从独占本地文件系统迁移到 Tectonic 命名空间,有些应用通过目录结构(如 ‘namespace/…/
应用配置好 Tectonic 插件并传递给 RocksDB 库,同时指定基础目录信息,确保数据被读写到期望的远程目录。插件还会读取 Tectonic 特定配置,如副本方案。有些配置(如副本方案)可能基于 RocksDB 传递的文件类型。每个 RocksDB 实例是对应目录下文件的唯一写入者,因此该实例可以安全地缓存数据和元数据,无需担心一致性问题(§4.1.2, §4.1.3)。
上述基础设置可作为原型运行,但我们在将其扩展到生产可用、可扩展和高效时遇到了若干问题。这些挑战及其对应解决方案分别在第 3.2 节和第 4 节详细描述。
需要实现的接口:https://github.com/facebook/rocksdb/blob/7.6.fb/include/rocksdb/file_system.h
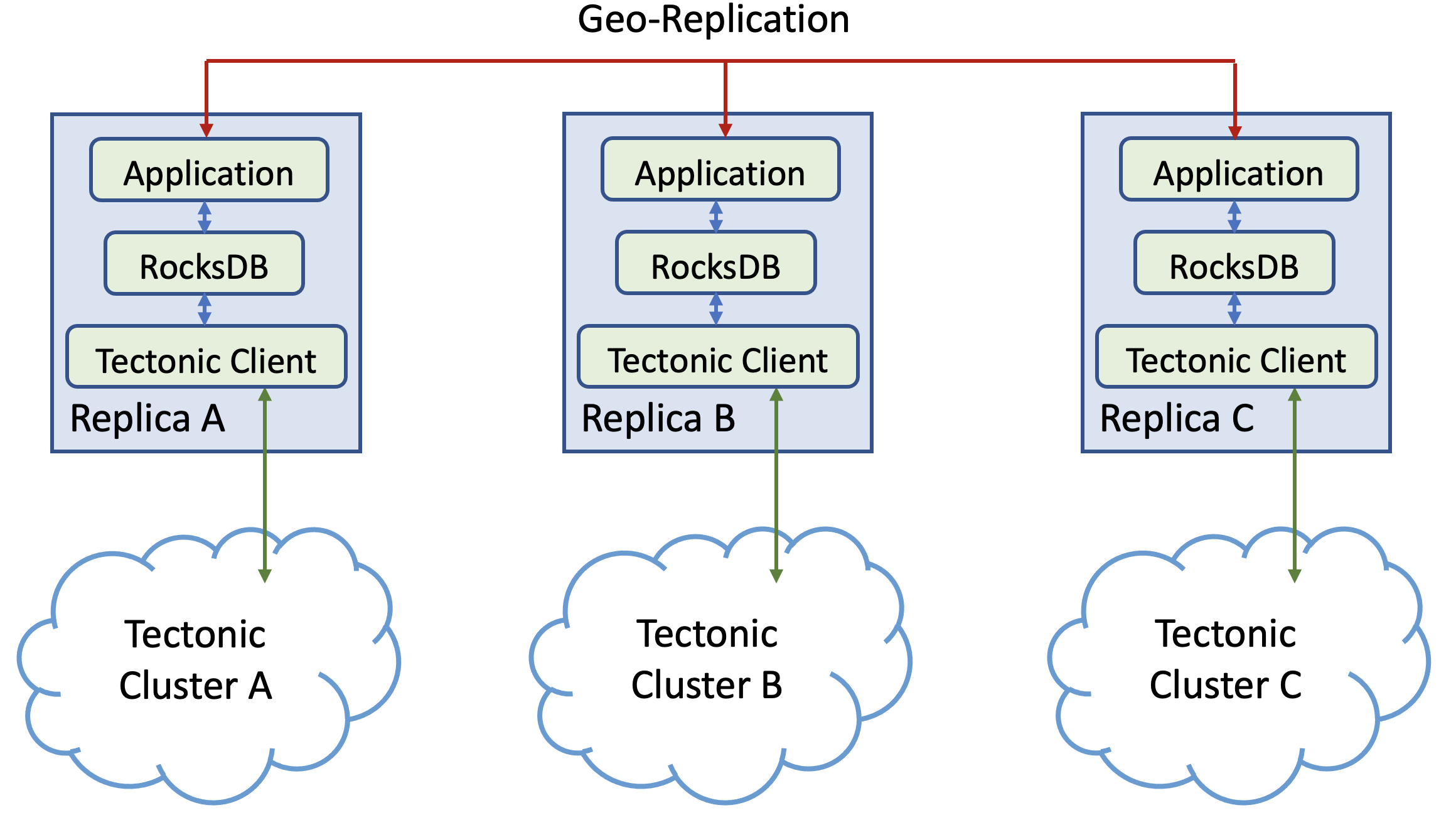
图 3. 典型服务在 Tectonic 上使用 RocksDB。
3.2 挑战
3.2.1 性能
分离式存储引入了网络跳数,导致性能相较本地 SSD 架构有所倒退。我们接受部分应用永远无法由远程存储服务,但仍希望拓展可服务的应用范围。
我们调研了典型工作负载模式及其性能预期。通常我们期望小型读写(KB 级到数百 KB,通常为点查或 Get/Put 请求)的 99 分位延迟小于 5 毫秒。对于 MultiGet 查询、迭代器或扫描操作,99 分位延迟期望在数十毫秒级。我们在第 4.1 节介绍了为满足上述需求所做的性能优化。
3.2.2 低开销冗余
为实现托管存储系统的优势并支持快速故障切换,DFS 数据需具备持久性(§2.4)。但增加冗余会带来存储空间和 SSD 寿命的额外开销。由于 Tectonic 客户端驱动架构,数据的副本或纠删码操作在 Tectonic 客户端内部完成,这也会为 RocksDB 应用带来网络开销。我们在第 4.2 节介绍了如何为 RocksDB 的 SST 和 WAL 文件采用不同的副本方案。
3.2.3 多写者下的数据完整性
为支持快速故障切换,分离式存储下多个计算节点可访问同一 RocksDB 目录下的文件。通常只有一个节点能修改数据。当该节点失效时,应用会选取另一节点接管。此时需保证前一节点无法再修改数据。实现这一点并不简单,因为通常无法联系失效节点,且该节点未来可能重新上线并尝试操作。换句话说,问题可转化为:如何保证某一目录及其内容在任一时段只能被唯一指定进程操作。我们的解决方案见第 4.3 节。
3.2.4 适配远程 IO
RocksDB 需改变部分假设以支持远程 IO。本地文件系统通常无需处理瞬时 I/O 错误,除非极端情况(如磁盘空间耗尽)。RocksDB 过去将 I/O 错误视为本地文件系统损坏,此时会将整个数据库设为只读。现在,RocksDB 需更合理地处理不同错误,确保数据库在可能情况下持续运行。更多示例及其解决方案见第 4.4 节。
4 应对挑战
本节介绍我们如何克服上述挑战。大部分变更都在 RocksDB 库内部。但为解决部分挑战,我们还需要底层 DFS 提供特定功能或性能保障。我们会在本节中标注这些需求,并在 §8 总结经验。
4.1 性能优化
RocksDB 存算分离方案需弥合远程 IO 带来的延迟差距(§3.2.1)。底层 DFS(Tectonic)需提供良好的尾延迟,RocksDB 层则需尽量屏蔽额外延迟。我们将介绍 DFS 尾延迟改进及 RocksDB 侧的专用优化。最后在第 5 节评估存算分离方案的性能。
4.1.1 优化 I/O 尾延迟
整体 I/O 可能因一两个慢存储节点而变慢,导致读写操作出现长尾延迟。为应对该问题,当怀疑某节点变慢时,我们尝试通过其他节点服务流量。具体采用了三种技术:
- 动态主动重构(Dynamic Eager Reconstructions):通常先发起第一次读取,延迟后有条件地发起第二次读取,取最早返回结果。对副本数据来说很直接,但对纠删码数据,第二次读取涉及多个并行 IO,资源消耗更大。此外,若集群健康状况导致延迟升高,重构读取若处理不当会进一步恶化延迟。我们通过密切跟踪集群读取延迟分位数,并持续调整发起第二次读取的阈值来应对。
- 动态追加写入超时(Dynamic Append Timeouts):写入 Tectonic 通常涉及将数据刷新到一组存储节点。我们只等待部分节点(仲裁组/子集)确认后即向客户端确认,其余写入在后台继续。这带来更好的尾延迟。但若集群有维护活动,更多节点响应变慢,该技术就失效了。为此,我们采用类似动态主动重构的方法:若超时发生,则终止正在进行的追加,记录元数据中最后成功的大小,选择新一组存储节点,更新元数据,并在新节点上重试。这能屏蔽少数慢节点带来的影响。我们密切跟踪集群追加延迟分位数,并持续调整新追加的超时时间。我们计划进一步优化,消除该流程中的元数据更新。
- 对冲仲裁组全块写入(Hedged Quorum Full Block Writes):与追加写入不同,要求必须在特定存储节点组完成数据写入,对于大型写入任务,Tectonic 会创建全块,因此可选择任意存储节点执行写入。我们将块写分为两个阶段:许可获取和数据传输。第一阶段,客户端从远超所需数量的存储节点池获取写入许可,节点根据自身资源(内存、带宽、CPU)决定是否授予许可。第二阶段,客户端选择最早响应的节点进行实际写入。
4.1.2 RocksDB 元数据缓存
RocksDB 对某些文件元数据操作(如目录列举、文件存在性检查、文件大小查询)有更高性能要求。这些操作也被数据仓库等其他应用使用,但 RocksDB 使用频率更高且延迟要求更严格。为应对这一挑战,我们利用了这样一个事实:底层 RocksDB 目录在任一时刻只会被一个进程访问和修改,因此元数据可以主动缓存。通过缓存,我们几乎绕过了所有元数据查找操作。由于目录始终只被一个进程访问和修改,结合 §4.3 的 IO Fencing 方法,该缓存始终保持一致。
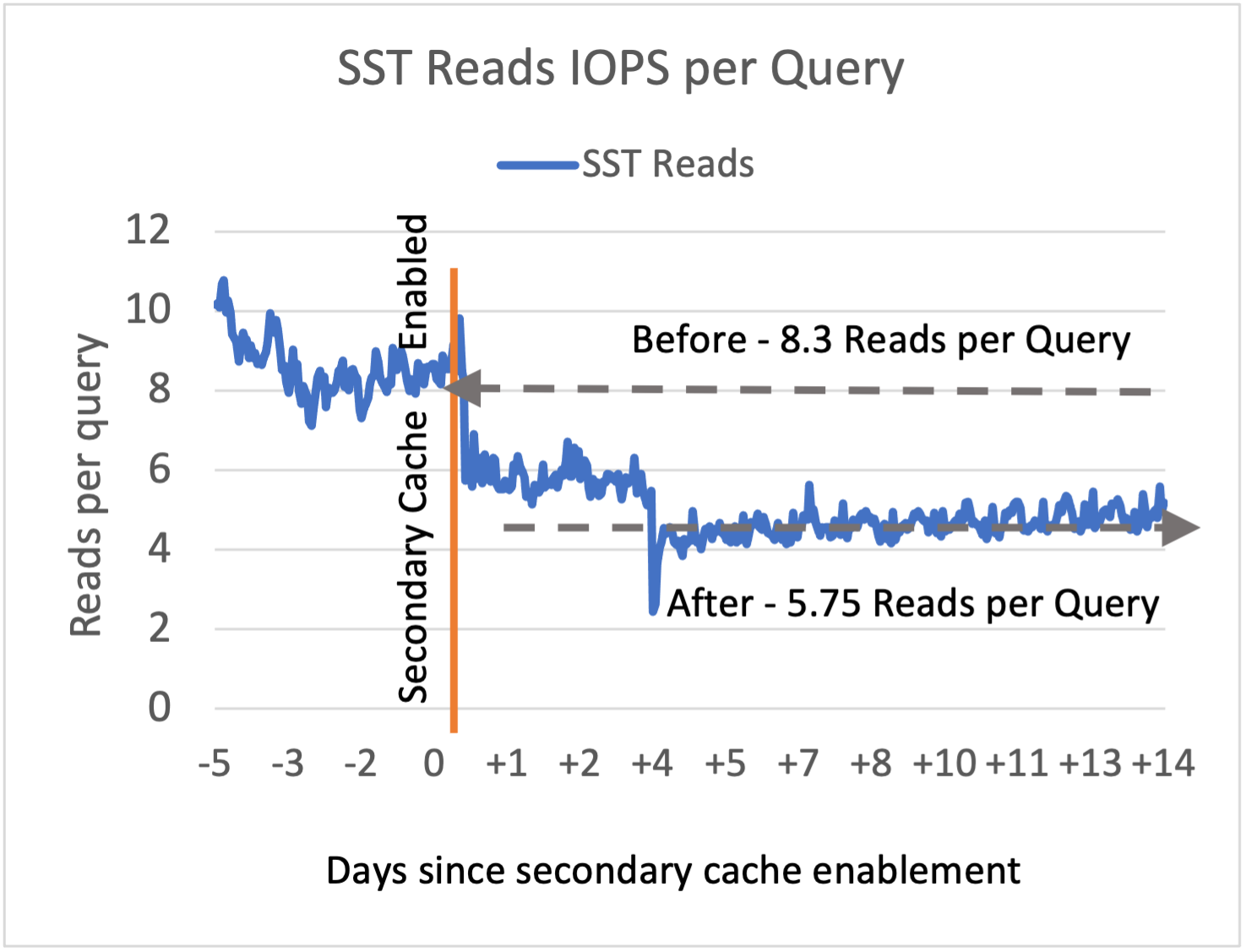
图 4. 在 ZippyDB 中启用辅助缓存之前/之后,每个 ZippyDB 读取查询的 SST 文件读取图。
4.1.3 RocksDB 本地闪存缓存。
为让部分读密集型应用能在 Tectonic 上使用 RocksDB,我们实现了基于非易失性介质(如本地闪存设备或 NVM/SCM)的块缓存。它可视为 RocksDB 现有块缓存(基于 DRAM)的扩展。非易失性块缓存作为二级缓存,存放从主缓存驱逐的块。这些块在访问变热时会被提升回主缓存。官方称该缓存为 SecondaryCache,内部基于 Cachelib [14][17] 实现。
在生产环境下,ZippyDB 启用二级缓存后,读 IOPS 提升 50-60%(见图 4),ZippyDB 层面的读延迟降低 30-40%(见图 5)。缓存配置为 20GB 主缓存和 100GB 二级缓存。
该优化已完全开源,包括基于 cachelib 的 SecondaryCache 插件 [2]
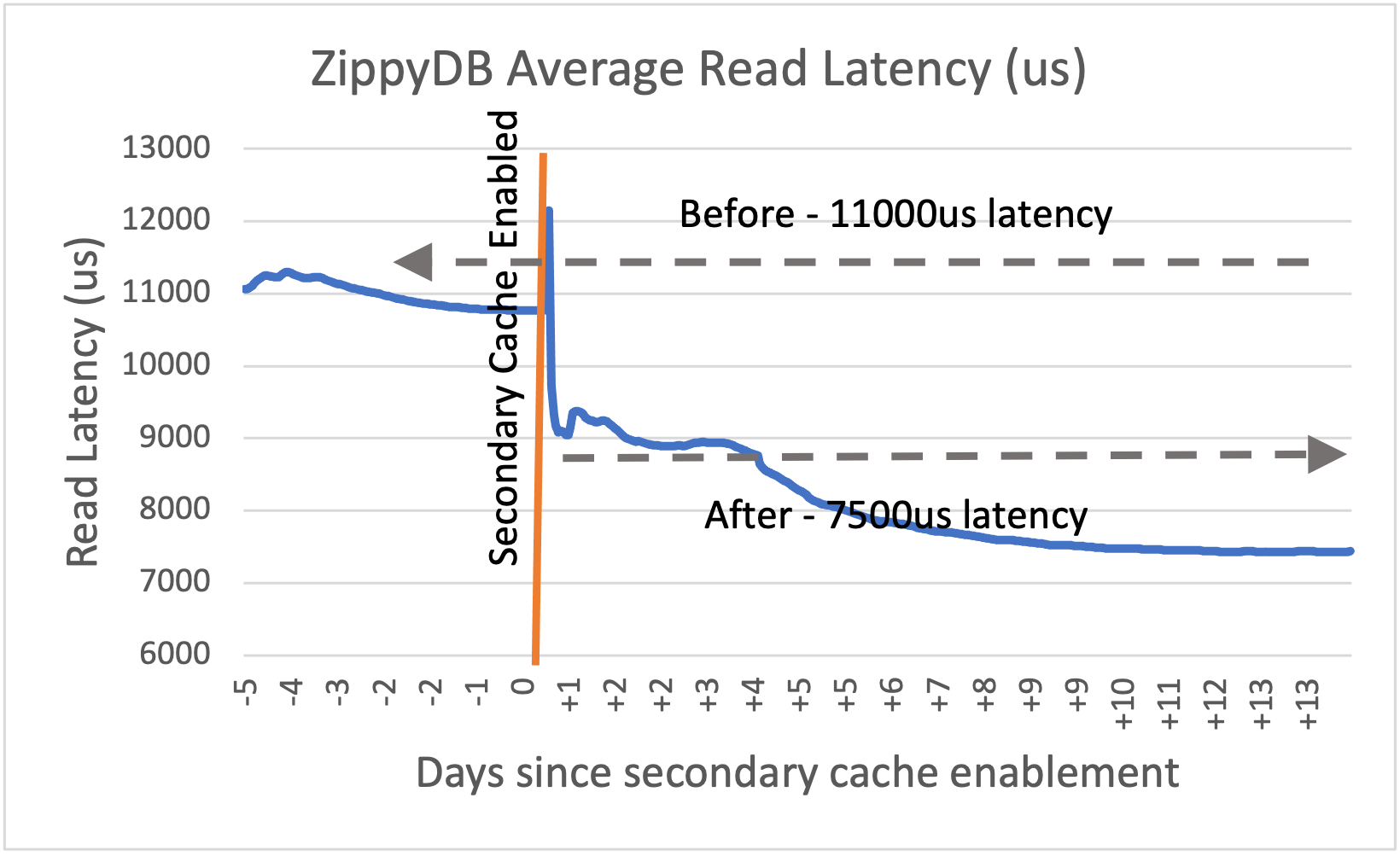
图 5. ZippyDB 启用二级缓存前后的平均读延迟。
4.1.4 RocksDB IO 处理。
由于 Tectonic 的 IO 特性与本地 SSD 不同,我们思考是否应调整 RocksDB 的 IO 策略。我们发现 Tectonic 在 IO 特性上与 HDD 有相似之处,如读写延迟更高、偏好大块写入。通过调整 RocksDB 针对 HDD 的相关参数,在 Tectonic 上的性能也大幅提升。
RocksDB 在合并路径上提供了 IO 调整的灵活性,因为合并读写 IO 都是顺序的,缓冲区大小可调。在 Tectonic 上运行时,通常将合并读取大小设为 4MB 或 8MB,合并写缓冲区设为 64MB 或更大,应用即可获得满意性能。合并延迟仍可能增加——幸运的是,RocksDB 支持并行 memtable 刷新和合并,可帮助吸收延迟。
虽然调整现有参数能解决许多性能问题,但我们仍观察到某些需要大量 IO 的操作存在长查询延迟。举例:1)用户用 MultiGet() 读取过多键,可通过并行 IO(§4.1.5)缓解;2)迭代器读取过多连续数据块。RocksDB 通过预读减少迭代器路径上的 IO,预读有两种模式:固定配置和自适应。HDD 用户通常用固定预读,但在 Tectonic 上会导致过多网络带宽消耗。自适应模式从读取一个块开始,不断翻倍直到最大 256KB。但这种方式在 Tectonic 上预热太慢。为此,我们让 RocksDB 基于历史统计设置初始预读大小,并使最大值可配置。
4.1.5 RocksDB 并行 IO。
即使 Tectonic 单次读取的平均延迟只比本地 SSD 高几百微秒,若一次查询需多次 IO,累计延迟差距会很大。这常见于应用用 MultiGet() 一次读取多个键。为此,我们优化了 IO 密集型 MultiGet 的延迟:对同一 SST 文件的多个键,数据块读取可并行发起 3 。这对 Tectonic 尤为重要,因为远程存储读取延迟更高。IO 并行化会提升 Tectonic 客户端 IO 路径的 CPU 占用,微基准测试显示提升达 50%,但绝对值很小,因为 IO 仅占 MultiGet 总处理的一小部分。
4.1.6 RocksDB 合并调优。
Tectonic 的读写 IOPS 较低,会限制 RocksDB 的读 QPS 和合并吞吐。此外,数据冗余也占用更多空间。
我们未观察到瓶颈转移的统一模式,主要取决于工作负载。若用户在迁移到 Tectonic 后发现瓶颈变化,可据此调整 RocksDB 合并策略。有趣的是,极少用户在迁移后需要更改合并策略,或许说明瓶颈通常不会因迁移而变化。
一个可能影响 Tectonic 性能的合并参数是目标 SST 文件大小。本地文件通常设为 32MB-256MB。直观上,SST 文件太小会导致文件过多,可能拖慢数据库打开等操作。根据我们的经验,除非目标 SST 文件小于 64MB,否则对性能影响很小。
3 本节中提到的改进都在开源 RocksDB 中,除了文件异步 IO 的存储特定实现
4.2 低开销冗余
存算分离方案需以低开销实现冗余(§3.2.2)。Tectonic 提供多种编码方案,具备不同的持久性和可用性保障。RocksDB 用户可为不同文件类型选择合适的编码方案。
SST 文件需高持久性且低开销编码,因为它们占用大部分空间和写带宽。我们为 SST 文件选择 [12,8] 编码(8 数据块 +4 校验块),只需 1.5 倍空间和带宽开销,且能适配 6 或 12 个故障域的部署,提供高持久性 SLA。
WAL 及其他日志文件需支持小块(子块)追加的低尾延迟持久化。我们为 WAL 及日志文件采用 5 副本(R5)编码,原因如下:1)副本编码对小写入无 RS 编码开销,尾延迟更优;2)与 RS 编码不同,副本编码无需写入对齐或填充;3)R5 足以满足主机失效概率下的可用性需求。
对于日志更新频繁、R5 带来 5 倍网络开销过高的场景,Tectonic 侧增加了条带化 RS 编码 [12] 的小块追加持久化支持。条带化编码需收集一条带(或多条带)数据后再刷新。例如 [12,8] 编码 +8KB 条带时,将 8KB 数据分成 8 个 1KB 数据块,生成 4 个 1KB 校验块,共 12 个 1KB 块分发到 12 个存储节点。每个节点将 1KB 块追加到对应的 XFS 文件(通常为 8MB)。条带大小按文件类型预设。偶尔需刷新非对齐数据时,会用零填充对齐后编码并刷新。条带较小会降低随机读效率,因为需从多个节点组装并解码,但日志文件几乎总是顺序读取,因此该方案适用。
少数场景下,我们用更高开销的纠删码配合对冲技术(§4.1.1)降低尾延迟。
4.3 多写者下的数据完整性
为解决 §3.2.3 所述多写者导致数据损坏问题,我们实现了协作式 IO Fencing 协议,将前一节点的写操作隔离开来,原理类似于单调递增 token 的分布式锁 [4]。
我们要求试图 “ 拥有 “ 某 RocksDB 目录的进程,必须先用一个 token(变长字节串)对目录进行 IO Fence,后续对该目录及其下文件的所有操作都需携带该 token。只有 token 字典序大于此前任意进程用过的 token,fence 才会成功。Tectonic 内部会依次完成以下步骤以保证 fence:首先在元数据系统中更新目录 token(前提是新 token 更大),这样可阻止持有旧 token 的进程对文件进行新建、重命名、删除等变更。随后,Tectonic 遍历目录下所有可变(未封存)文件,对每个文件(a)更新元数据 token,(b)通过连接存储节点封存文件尾部可写块。步骤(b)可迫使旧写者与元数据系统同步,从而获知自身已过期并放弃重试。若任一步骤因 token 被更大 token 取代而失败,则本次 fence 失败,进程不得尝试以写模式打开 RocksDB。
4.4 适配远程调用
RocksDB 库本身需适配远程 IO 调用,其行为可能与本地 IO 不同(§3.2.4)。RocksDB 内部所有变更均已开源,但需针对不同存储实现专用插件(我们内部实现为 Tectonic)。
4.4.1 区分 IO 超时
远程 IO 操作可能因多种原因比本地慢。例如,瞬时故障重试后可恢复,这类 IO 可能需数秒才能成功。但对用户请求的 IO,等待数秒太久。RocksDB 应用通常要求查询在 1 秒内完成。若某 IO 需数秒,结果可能已无意义。相反,数据库内部操作(如合并、刷盘)发起的 IO 可容忍单次慢 IO,哪怕耗时数秒甚至数分钟。这类 IO 的故障处理更复杂,因此 Tectonic 可适当延长超时以避免失败。我们结论是,不同类型 IO 应设置不同超时。
我们为刷盘和合并等操作设置较长的超时时间,而对 Get() 或迭代器等操作则设置亚秒级超时。RocksDB 新增了可配置参数 request deadline,若请求超时则直接返回失败。用户设置的 deadline 会传递给 Tectonic。
4.4.2 RocksDB 的故障处理
历史上,RocksDB 在 WAL 写入/同步、后台刷盘和合并等关键数据库操作遇到 IO 错误时,会切换为只读模式,以保证数据库一致性。这与 Ext4、XFS 等本地文件系统的做法类似。
在 Tectonic 文件系统上读写数据可能遇到高延迟、瞬时写/读失败、短时数据不可用,甚至系统级故障。与本地文件系统不同,这些情况发生频率更高,但往往是瞬时且可恢复的。我们意识到,若能合理分类错误并对瞬时错误做恢复,可大幅提升数据库可用性。为此,我们增强了文件系统 API 的返回状态,不仅包含错误码,还包括可重试性、作用域(文件级或全局)及是否永久丢失等元数据。Tectonic 可据此判断错误是否可恢复。RocksDB 侧则聚焦于在文件系统写入错误后恢复数据库一致性并恢复写入。
对于某些写入失败(如后台刷盘或合并),操作会自动重试且无用户停机。而 WAL 写入失败等情况,则需暂时停止写入,将 memtable 刷盘以保证一致性。
避免因 Tectonic 瞬时故障导致用户写入停机非常重要,因为写入失败对部分服务代价极高。例如,写入失败会导致 ZippyDB(基于 RocksDB 的应用)将受影响副本移出 Paxos 仲裁组,并重建新副本。
4.4.3 IO 监控
随着存储栈变得更复杂,提升 IO 路径可观测性对故障排查尤为重要。用户常用本地文件系统的 IO 跟踪工具(如 strace),但 Tectonic 不支持这些工具。因此我们在 RocksDB 中开发了更多 IO 监控能力,使同一套工具可用于所有类型文件系统。
4.4.4 工具支持
RocksDB 有多种命令行工具,但原本只支持本地文件系统。这些工具用于检查数据库状态、SST 文件,有时还可帮助用户对数据库进行离线操作。用户在使用 Tectonic 时也需运行这些工具。同样,针对 Tectonic 运行基准测试、压力测试等工具也很有价值。我们在 RocksDB 中实现了通用 “ 对象注册表 “,维护对象名模式到工厂函数的映射,用于创建特定类型对象。若用户提供如 “tfs://cluster1/db1” 的 Tectonic 集群 URL,RocksDB 会查表并用 Tectonic 插件对象与底层 Tectonic 文件系统通信。我们仅对开源代码做了极小改动,即可迁移现有工具和测试到 Tectonic,其他用户开发的文件系统插件也可用同样方式集成。
5 性能基准
基准测试设置
我们用 RocksDB 的微基准工具 db_bench 评估了 RocksDB+Tectonic 的性能。该工具的基准测试被 RocksDB 开发者、用户和硬件厂商广泛采用。我们采用 RocksDB 官方 wiki[10] 推荐的基准设置,验证每个 RocksDB 官方版本。基准测试用 20 字节键、400 字节值,值可压缩到原来一半。总共 10 亿个键,数据库物理占用约 200GB。块缓存设为 16GB,保证大多数查询至少需一次 IO。块大小 8KB,磁盘数据主要用 ZSTD 压缩,新数据用 LZ4。RocksDB 选项未针对 Tectonic 特别调优,仅调整 IO 相关参数。本地 SSD 场景用 direct IO,避免用 DRAM 做页缓存,未用本地闪存缓存。
所有实验均用 3 个 1.6GHz 物理核、64GB DRAM。我们在 Tectonic 上跑基准,并用本地 SSD 结果作参考。正如预期,本地 SSD 查询延迟更低、QPS 更高。我们仅将本地 SSD 结果作为参考,目标并非追平本地 SSD 性能。RocksDB 版本为 7.4,唯一非开源部分是让 RocksDB 支持 Tectonic 的存储接口实现。
写入吞吐
表 1 展示了顺序写和随机写基准结果。在 RocksDB 中,顺序写入的键会写入不同 SST 文件,这些文件无需合并。基准显示,RocksDB 在 Tectonic 上的顺序写吞吐与本地模式相当。随机写时,Tectonic 吞吐比本地低约 25%。虽然 Tectonic 能为多文件并发读写提供足够吞吐,但单文件处理速度有限,成为瓶颈。调优 RocksDB 合并参数可缓解,但为公平对比我们保留默认设置。
| 工作负载 | Tectonic | 本地 SSD |
|---|---|---|
| 顺序写入 | 262.4 | 264.1 |
| 随机写入 | 19.2 | 26 |
表 1. 写入工作负载的 RocksDB 吞吐量(MB/s)。
读取性能
我们做了三组读测试。第一组对随机键做 Get(),每次读通常对应一次底层 IO。单次查询延迟与 Tectonic、本地 SSD 的随机读延迟接近,Tectonic IO 延迟约为本地 SSD 的 5 倍。MultiGet 测试一次查询 10 个相近键,键间距为 32,确保分布在相近但非相邻数据块(相邻块会被 RocksDB 合并为一次 IO)。迭代器测试从随机位置读取 10 个键。MultiGet 和迭代器都可通过并行 IO(§4.1.5)获益。未用并行 IO 时,Tectonic 查询延迟约为本地 SSD 的 5 倍,启用并行 IO 可将差距缩小到 3 倍。
| Threads | Tectonic(Parallel I/O on) | Tectonic(Parallel I/O off) | 本地 SSD | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| QPS | P50 延迟(ms) | P99 延迟 (ms) | QPS | P50 延迟(ms) | P99 延迟 (ms) | QPS | P50 延迟(ms) | P99 延迟 (ms) | ||
| Get | 64 | N/A | N/A | N/A | 54.8K | 1.1 | 2.9 | 334K | 0.19 | 0.42 |
| 32 | N/A | N/A | N/A | 41K | 0.74 | 1.6 | 208K | 0.15 | 0.34 | |
| 1 | N/A | N/A | N/A | 1.2K | 9.76 | 2.0 | 7.2K | 0.14 | 0.26 | |
| MultiGet | 32 | 6.4K | 4.51 | 13.23 | 5.8K | 5.35 | 12.48 | 39.3K | 0.79 | 1.51 |
| 16 | 5.5K | 2.74 | 6.50 | 4.2K | 3.77 | 6.54 | 23.1K | 0.70 | 1.26 | |
| 8 | 4.1K | 1.88 | 3.67 | 2.4K | 3.39 | 6.42 | 12.4K | 0.66 | 1.20 | |
| 1 | 0.6K | 1.69 | 5.49 | 0.3K | 3.42 | 9.06 | 1.7K | 0.61 | 1.07 | |
| 迭代器 | 32 | 14.2K | 2.12 | 5.38 | 11.3K | 2.77 | 6.38 | 70.2K | 0.30 | 0.61 |
| 16 | 10.7K | 1.33 | 2.88 | 6.4K | 2.34 | 5.94 | 34.4K | 0.26 | 0.57 | |
| 8 | 6.1K | 1.27 | 2.72 | 3.2K | 2.38 | 6.01 | 15.7K | 0.25 | 0.55 | |
| 1 | 0.7K | 1.29 | 3.24 | 0.3K | 3.03 | 9.36 | 1.8K | 0.25 | 0.54 |
表 2. 读取工作负载的 RocksDB 基准测试结果。
所有读测试中,Tectonic 客户端允许的并发 IO 数有限,导致无法通过增加线程提升吞吐。该限制并非本质,可移除,但当前用户对现有吞吐已满意,且移除后需引入流控以保护 Tectonic 存储节点不被过载。
6 应用实践:ZippyDB
我们已将多种原本用本地存储的 RocksDB 应用迁移到 Tectonic。我们发现,虽然 RocksDB on Tectonic 让应用更易采用分离式存储,但应用仍需应对一些常见生产挑战。
本节将以 ZippyDB 为例说明这些挑战。ZippyDB[15] [40] 是 Meta 原生构建的可靠、一致、高可用、可扩展的分布式键值存储服务,服务场景包括存储存储系统元数据、事件计数(内外部)、产品数据等。其底层用 Multi Paxos 做地理复制,存储引擎为 RocksDB。ZippyDB 采用分离式存储的动机包括:提升存储池利用率、加快故障切换/下线速度、简化托管存储运维。
6.1 处理非 RocksDB 文件
与许多使用 RocksDB 的服务类似,ZippyDB 也会直接在文件系统上存储部分数据,如 MultiPaxos 协议的复制日志。虽然 Tectonic 可直接支持日志,但我们认为有必要为 Tectonic、RocksDB 及其应用(如 ZippyDB)提供统一的资源控制工具。例如,对所有后台任务做 IO 限流,控制最大 IO 大小、维护最大未刷脏数据量等。为解决这些问题,ZippyDB 将所有文件操作迁移到 RocksDB 的存储接口上,这样文件系统操作就能满足 RocksDB 的所有需求。该接口实现为本地文件系统和 Tectonic 的统一存储接口,因此 ZippyDB 可像 RocksDB 一样同时运行在本地文件系统和 Tectonic 上。
由于复制日志(rlog)写入发生在用户 IO 上下文中,在 Tectonic 上运行时,写入因网络通信带来更多开销。在本地文件系统上,ZippyDB 会先将 rlog 写入 OS 页缓存再确认,这种权衡在多副本主机并发内核崩溃(或主机故障)概率极低的前提下,能为客户端提供足够的性能和持久性。为优化 Tectonic 上的 rlog 写入,我们保持同样模型:先写入共享内存缓冲区再确认,后台异步将内核内存中的数据写入 Tectonic。我们对这类数据采用条带化纠删码(§4.2)的小块追加,以低开销实现高可用。这样,用户写入延迟不受 Tectonic 影响,Tectonic IO 次数减少,网络放大也最小化。
6.2 构建新副本
与所有数据服务类似,ZippyDB 的副本需在多种场景下重建。常见场景是主机故障。在本地文件系统下,主机故障时需从健康副本(通常在其他区域)复制数据库持久状态(所有 DB 文件)以构建新副本。在复制完成前,系统处于降级副本状态,因此重建新副本所需时间直接影响整体可用性——此期间若再有副本失效,Paxos 仲裁组(如三副本)节点数不足,服务可用性受损。Tectonic 下,主机故障需重建副本时,ZippyDB 会将失效副本用到的所有文件复制到新数据目录,新计算节点从该目录打开 DB。得益于 Tectonic 的快速文件复制操作(新文件元数据指向原物理数据),该过程极快。负载均衡等场景下重建同区域副本也采用类似流程,旧副本在快速复制成功后销毁。Tectonic 让 ZippyDB 将同区域副本重建时长从约 50 分钟缩短到 1 分钟以内。
跨区域负载均衡、集群下线等场景仍需数据复制,此时无法用 Tectonic 快速复制。可用 RocksDB 的统一存储接口像本地文件系统一样复制,或用 Tectonic 提供的跨集群文件复制工具,保证用合适的网络和 IO 优先级完成。
6.3 正确性与性能验证
应用通常希望在全面迁移到 Tectonic 前验证数据正确性和性能。为保证平滑迁移且不影响可靠性,我们设计了可快速回退到迁移前状态的迁移方案。为此,我们基于 RocksDB 存储接口实现了镜像文件系统。该实现底层用两个存储系统,一个作为真实源,处理所有 IO 请求,另一个异步镜像第一个的更新。
正向镜像:此模式下,ZippyDB 继续用本地闪存为真实源,同时在 Tectonic HDD 上维护异步副本。这样,ZippyDB 和 Tectonic 可在低风险/低成本下互相熟悉。
基于镜像的恢复:当使用镜像的 DB 实例切换到其他服务器时,我们用 Tectonic 的异步副本初始化 DB。由于 DB 状态可能与异步副本不一致,我们在 RocksDB 中实现了 “ 尽力恢复 “ 模式,可将 DB 恢复到异步副本的最近一致状态。我们在边从 Tectonic 拷贝数据到本地文件系统边启动 DB。
反向镜像:迁移第二步(正向镜像后),ZippyDB 以 Tectonic 闪存为真实源,同时在本地闪存保留异步副本。新负载在此模式下运行数周,验证可靠性和性能后,最终切换为仅用 Tectonic 闪存。
6.4 文件垃圾回收
如用例删除、硬件故障等场景,若拥有 DB 实例的计算节点宕机/不可达,可能在闪存上遗留 DB 实例存储。本地闪存下,节点回收时会清理这些状态;Tectonic 下,这些 DB 实例状态会一直遗留。我们增加了后台服务,通过比对 ZippyDB 活跃实例和 Tectonic 上所有实例,识别并清理无主 DB 实例。
6.5 RocksDB on Tectonic 的收益
许多 ZippyDB 服务器因 §2.2 所述原因无法高效利用全部空间或 CPU,我们为提升效率做了多项努力。RocksDB on Tectonic 让我们实现了更高利用率。某 ZippyDB 集群用本地 SSD 时空间利用率为 35%,而用 Tectonic 时为 75%。即使考虑每字节存储的额外开销,依然实现了显著节省。存储可靠性也帮助我们缩短了硬件故障导致的服务不可用时间(§6.2)。实时监控显示,Tectonic 上 ZippyDB 可用性通常高于 99.99999%,本地 SSD 上则常见为 99.99993%(见图 6)。表 3 对比了两者部分指标。
| 生产指标 | Tectonic | 本地 SSD |
|---|---|---|
| 空间利用率 | 75% | 35% |
| 可用性 | 99.99999% | 99.99993% |
| 副本重建时间 | <1 分钟 | ~50 分钟 |
表 3. 本地 SSD 和 Tectonic 上 ZippyDB 的比较。
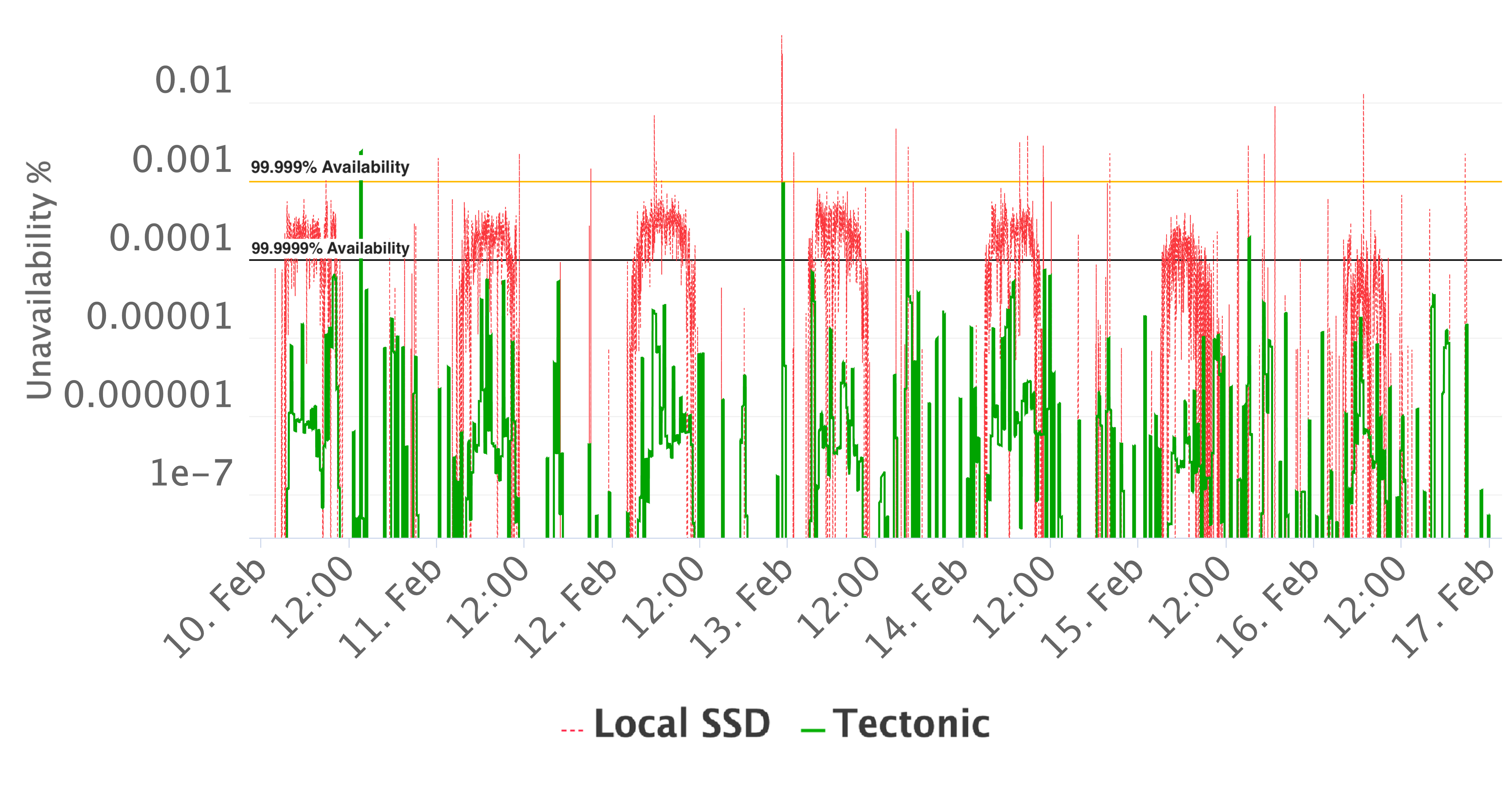
图 6. ZippyDB 一周可用性比较。
6.6 性能分析
本次性能分析选取了 4 个基于 ZippyDB、每个存储至少数百 TB 数据的应用(见表 4),它们读写负载较轻,适合 Tectonic。每个用 3 副本,其中 1 个在 Tectonic,2 个在本地 SSD。主副本/从副本无优先级,读流量均衡。这种设置便于对比两者性能。
| Use Case | QPS Per TB | Bandwidth(MB) Per TB | 工作负载描述 | ||
|---|---|---|---|---|---|
| Read | Write | Read | Write | ||
| 1 | 14 | 548 | 0.4 | 0.37 | 存储推荐系统的不同受众的标志。读取通常使用迭代器完成。 |
| 2 | 33K | 28 | 294 | 28.42 | 存储推荐系统的目标组的估计和统计信息。读取通常使用迭代器完成。 |
| 3 | 54 | 12 | 0.77 | 5.55 | 存储以多种方式折叠的内容的曝光、点击和其他指标,由推荐系统使用。读取由迭代器和 MultiGet() 完成,比率约为 6:1。 |
| 4 | 3K | 1.7K | 0.17 | 0.27 | 从多媒体中提取标志,用于 ML 模型。读取通常使用 MultiGet() 完成。 |
表 4. 分析的 ZippyDB 用例摘要。
Tectonic 和 SSD 副本都运行在同类型服务器上的 RocksDB 实例,但配置略有不同。本地 SSD 主机不使用 direct IO,OS 页缓存命中率很高;Tectonic 不用 OS 页缓存,而用本地闪存缓存,容量约为块缓存 4 倍,仅占 DB 小部分。这样通常能减少 Tectonic 的 IO 次数。尽管配置不同,我们认为延迟数据能反映真实体验。
每个用例我们都收集了 ZippyDB 客户端的端到端延迟(见表 5-8),包括客户端计算、网络通信、服务器排队、RocksDB 延迟等。我们还展示了单次 RocksDB 操作延迟。需注意,ZippyDB 操作不一定直接映射到 RocksDB 操作,ZippyDB 代理层常将多个客户端请求合并为一次 RocksDB 操作,且代理层有小缓存,部分重复查询直接命中缓存。我们还展示了 Tectonic 和本地文件系统的小读 IO 延迟。许多本地文件系统读操作被 OS 页缓存命中,我们过滤了 30 微秒内完成的请求。
| 生产指标 | Tectonic | 本地 SSD |
|---|---|---|
| 端到端 MultiScan 延迟(P50,ms) | 8.9 | 5.5 |
| 端到端 MultiScan 延迟(P99,ms) | 49.6 | 40.0 |
| 端到端 Write 延迟(P50,ms) | 103 | 114 |
| 端到端 Write 延迟(P99,ms) | 876 | 766 |
| RocksDB IteratorSeek 延迟(P50,ms) | 0.44 | 0.33 |
| RocksDB IteratorSeek 延迟(P99,ms) | 6.6 | 3.9 |
| 平均从 SST 文件读取的块数量 | 0.077 | 0.857 |
| 文件系统小数据读取延迟(P50,us) | 1325 | 388 |
| 文件系统小数据读取延迟(P99,us) | 5220 | 2330 |
表 5. ZippyDB 用例 1 的性能分析
| 指标 | Tectonic | 本地 SSD |
|---|---|---|
| 端到端 MultiScan 延迟(P50,ms) | 1.5 | 1.4 |
| 端到端 MultiScan 延迟(P99,ms) | 6.5 | 7.4 |
| 端到端 Write 延迟(P50,ms) | 44 | 36 |
| 端到端 Write 延迟(P99,ms) | 180 | 145 |
| RocksDB IteratorSeek 延迟(P50,ms) | 0.12 | 0.11 |
| RocksDB IteratorSeek 延迟(P99,ms) | 2.3 | 1.1 |
| 平均从 SST 文件读取的块数量 | 0.03 | 0.06 |
| 文件系统小数据读取延迟(P50,us) | 1382 | 346 |
| 文件系统小数据读取延迟(P99,us) | 8943 | 1993 |
表 6. ZippyDB 用例 2 的性能分析
| 指标 | Tectonic | 本地 SSD |
|---|---|---|
| 端到端 Iterator 延迟(P50,ms) | 10.4 | 5.8 |
| 端到端 Iterator 延迟(P99,ms) | 74 | 50 |
| 端到端 MultiGet 延迟(P50,ms) | 3.4 | 2.1 |
| 端到端 MultiGet 延迟(P90,ms) | 23 | 16 |
| 端到端 Write 延迟(P50,ms) | 34 | 46 |
| 端到端 Write 延迟(P99,ms) | 63 | 72 |
| RocksDB IteratorSeek 延迟(P50,ms) | 0.89 | 0.99 |
| RocksDB IteratorSeek 延迟(P99,ms) | 17.5 | 7.4 |
| RocksDB MultiGet 延迟(P50,ms) | 1.6 | 1.2 |
| RocksDB 延迟(P99,ms) | 21 | 24 |
| IteratorSeek 平均从 SST 文件读取的块数量 | 0.57 | 0.71 |
| MultiGet 平均从 SST 文件读取的块数量 | 1.4 | 2.7 |
| 文件系统小数据读取延迟(P50,us) | 1019 | 325 |
| 文件系统小数据读取延迟(P99,us) | 4593 | 4806 |
表 7. ZippyDB 用例 3 的性能分析
| 指标 | Tectonic | 本地 SSD |
|---|---|---|
| 端到端 MultiGet 延迟(P50,ms) | 0.754 | 5.7 |
| 端到端 MultiGet 延迟(P99,ms) | 60 | 132 |
| 端到端 Write 延迟(P50,ms) | 129 | 137 |
| 端到端 Write 延迟(P99,ms) | 235 | 265 |
| RocksDB IteratorSeek 延迟(P50,ms) | 0.098 | 0.11 |
| RocksDB IteratorSeek 延迟(P99,ms) | 3.1 | 1.5 |
| 平均从 SST 文件读取的块数量 | 0.17 | 0.25 |
| 文件系统小数据读取延迟(P50,us) | 1080 | 346 |
| 文件系统小数据读取延迟(P99,us) | 3154 | 2432 |
表 8. ZippyDB 用例 4 的性能分析
所有用例中,端到端写入延迟无明显变化,
这是因为地理复制操作主导了延迟,这部分不会因 Tectonic 而变化。端到端读延迟在 Tectonic 上有时更高,但 P99(ZippyDB 用户最关心的指标)差距通常较小。幸运的是,这些 ZippyDB 用户可以接受性能倒退。Tectonic 的读延迟在这些服务中相对稳定,P50 读延迟为 1-1.3ms,是本地 SSD 的数倍,P99 为数毫秒。部分用例中,Tectonic 和本地 SSD 的 P99 延迟接近,另一些则差距较大。
在用例 1(表 5)和用例 2(表 6)中,平均 RocksDB 读查询无需 IO,仅需亚毫秒。但用例 1 中,ZippyDB 用户发起 MultiScan 命令,需多个迭代器,P50 延迟受影响。有趣的是,P99 延迟差距更小,可能因 Tectonic 的读对冲特性。用例 2 中,大多数 ZippyDB 请求对应单次 RocksDB 请求,延迟相当。用例 3(表 7)中,平均 RocksDB 查询需 IO,P99 端到端延迟提升 50%。
总体来看,虽然 Tectonic 单次读延迟通常是本地 SSD 的数倍,但对终端用户的影响远小于此,且对性能异常值影响更小。许多 ZippyDB 用户认为这种性能倒退是可接受的。
7 持续工作与挑战
本节介绍 RocksDB on Tectonic 方案的部分在研项目。这些都是开放性挑战,希望分享能激发社区进一步创新。
7.1 次级实例
计算 - 存储分离的一个好处是资源利用更高效。用户可灵活扩缩机器、存储空间、网络带宽等资源,以应对不同负载或同一负载的不同阶段。例如,读请求高峰时可增加机器共享底层数据,专门服务读请求;高峰过后可将这些机器释放。合并操作(compaction)对 CPU/IO 消耗大,若与主服务同主机运行,易导致 SLA 违约,因此有了远程合并的需求。
为支持多个 RocksDB 实例访问共享数据,我们开发了 “ 次级实例 “ 支持。主实例和次级实例以单写多读模式运行,次级实例重放主实例生成的日志文件。
仍有一些开放挑战,如防止次级实例使用期间文件被删除,以及在次级实例中查找并应用最新更新等。
7.2 远程合并
合并操作会与主服务争抢 CPU/IO 资源。远程合并将合并任务卸载到专用主机,Tectonic 文件系统让我们能构建统一的合并服务,为任意 RocksDB 数据库分发合并任务。这不仅提升了主服务的性能和可靠性,还能跨数据库统一调度和管理合并任务,这是本地合并无法实现的。我们也希望通过跨 DB 负载均衡合并任务,提升突发流量和倾斜负载下的吞吐。
我们在 ZippyDB 用例上测试了该特性。虽然 ZippyDB 主机只在同一区域用 Tectonic,但常分布于不同数据中心。Tectonic 集群通常部署在数据中心内,因此可通过让远程合并主机与 Tectonic 同地部署,节省跨数据中心网络。在测试中,我们节省了 50% 以上的跨数据中心 IO,平均合并时间缩短 20.4%。
远程合并在跨实例调度、优先级管理和用户插件支持等方面仍有挑战。
7.3 分层存储
闪存每字节成本和功耗远高于机械硬盘。将闪存(SSD)和机械硬盘(HDD)结合用于数据库有助于优化成本/能效。RocksDB on Tectonic 文件系统(支持 HDD 和 SSD)为我们设计分层存储方案提供了机会:冷 SSTable 存 HDD,热数据存 SSD。我们实现了分离冷热数据到不同 SST 文件并分别放置到不同介质的方案。通过分析数据插入时间预测冷热效果不错,但更复杂的冷热预测仍有挑战。
8 经验与反思
RocksDB 的通用性。 RocksDB 被 Meta 内外多种应用广泛采用。我们发现 RocksDB on Tectonic 方案足够通用,适合广泛服务。例如,我们的数据仓库索引服务为 HIVE 表内容提供低延迟查找。数据仓库表每日刷新时,索引服务的 RocksDB 实例会在短时间内被大量加载,这种访问模式会导致 Tectonic 文件打开请求激增。我们通过减少 SST 文件数来减少元数据调用次数。我们还实现了基于 RocksDB 的 FIFO 缓存服务的存算分离,最老的 SST 文件直接删除而非合并。
底层 DFS 的经验。 Tectonic 最初为机械硬盘服务数据仓库和大对象存储而建。转型服务 SSD 场景下的 RocksDB 时,我们发现以下特性尤为重要:a)支持应用进程独占写目录(§4.3 IO Fencing);b)支持可配置副本方案(§4.2);c)提供满意的性能,尤其是尾延迟(§3.2.1、§4.1);d)高效支持小写入,RocksDB 通常以几 KB 为单位追加 WAL 文件且需持久化(§4.2)。
RocksDB 应用需做的工作。 RocksDB 应用需做一定改造以适配 RocksDB on Tectonic,包括处理非 RocksDB 文件(§6.1)、构建新副本(§6.2)、服务质量验证(§6.3)。
9 相关工作
我们对 RocksDB on Tectonic 的探索建立在前人研究基础上,受益于计算 - 存储分离提升弹性和成本效率的观察。以往分布式文件系统和数据库(尤其是 LSM-tree 结构)设计与实现的经验为我们提供了宝贵启示。
计算 - 存储分离。 近期研究 [27,29,31,32] 探讨了存储、内存和网络的设计,以实现资源分离满足不同应用需求。研究者将资源分离思想应用于操作系统 [38]、文件系统 [18]、大对象存储 [33]、分析 [19,37]、数据仓库 [42] 等领域。
分布式文件系统。 分离式存储的虚拟化有多种方式,暴露给上层程序的接口也因部署规模、网络拓扑和应用需求而异 [1,3,5,7,11,28,30,33,35]。关于哪种接口最优的讨论超出本文范围。
分布式文件系统是集群环境下管理分离式存储的常用接口 [3,5,7,28,35]。部分文件系统兼容 POSIX[3,5],但也有不少分布式文件系统只支持或优化部分文件操作(如 GFS[28] 和 HDFS[7] 都假定覆盖写很少)。Tectonic 也有类似设计,只支持文件追加。追加写语义与 LSM 结构存储的访问模式高度契合。分布式文件系统社区为 LSM 存储做了大量优化。Hailstorm[18] 是专为 LSM 键值数据库设计和优化的轻量级机架级远程文件系统。
数据库与分离式存储。 已有多种分布式数据库系统为分离式存储而设计 [6,20-22,24,39,41],这些系统架构复杂,与作为库嵌入应用进程空间的 RocksDB 存储引擎不可直接类比。
BigTable[21] 及其开源实现 HBase[6] 是半结构化数据的分布式存储系统。BigTable 将数据划分为 tablet,每个 tablet 可由不同服务器托管。专用服务器(master)负责维护 tablet 到服务器的映射。BigTable 的设计与实现经验对我们后续在 Tectonic 文件系统上运行 RocksDB 有重要借鉴意义。Spanner[22] 是分布式数据库,数据存储在分布式文件系统 Colossus[23](新一代 GFS[28])上。Amazon Aurora[41] 是云原生关系数据库,数据库实例将 redo 处理卸载到多租户、可扩展的存储服务。Aurora 基于 MySQL[8],将备份和 redo 恢复卸载到存储集群以摊薄成本。[41] 中对比了 Aurora 和运行在 EBS[1] 上的 MySQL。PolarDB[20] 用 RDMA[9] 连接分离式存储与计算节点。
LSM-tree 与分离式存储。 日志结构合并树(LSM-tree)[34] 是分离式存储数据库常用的数据结构。BigTable、HBase 和 PolarDB 都将数据存为 SST 文件,因 SST 文件一旦写入即不可变,可被多个计算节点并发读取,即使作为合并输入也不影响。这与只支持追加写的分布式文件系统高度契合。
将合并操作卸载到分离式存储的思路也被其他系统探索过。[16] 提出将合并卸载集成到 HBase。Rockset 的 RocksDB-cloud[36] 是 RocksDB 的变体,支持将合并卸载到远程无状态服务器 [13]。RocksDB-cloud 在本地缓存 SST 和 WAL 文件,定期同步到云端。
10 结论
将数据库运行在直连 SSD 上可以获得更好的性能,但将数据存储在分离式存储上可能更高效且更易于管理。拥有一个能够同时支持本地和分离式存储的数据库存储引擎非常方便,我们的经验表明,通过有针对性的改进,这是完全可行的。我们通过扩展 RocksDB 支持 Tectonic 文件系统,实现了预期的效率提升。数据服务在生产中使用 RocksDB on Tectonic 也积累了许多经验。运行在分离式存储上还让 RocksDB 能够演进为更分布式的架构,我们也在持续探索这一方向。
11 致谢
我们感谢 SIGMOD 评审专家的宝贵意见和建议,这些意见提升了本文的质量。我们还要感谢 Michael Stumm 教授提供的深刻反馈和润色,以及 Mark Callaghan 的有益建议。
RocksDB on Tectonic 项目及其在 ZippyDB 上的应用,离不开这些团队成员及众多合作团队的宝贵贡献。我们特别感谢 Dan Meredith、David Felty、Federico Piccinini、Giang Nguyen、Guna Lakshminarayanan、JR Tipton、Jennifer Chan、Joe Hirschfeld、Jorge Guerra、Junjie Wu、Junqing Deng、Kapil Kataria、Karthik Krishnamurthy、Lachlan Mulcahy、Lujin Luo、Madhu Anantha、Michael C Huang、Michael Meng、Mikhail Antonov、Murali Vilayannur、Naveen Ganapathi Subramanian、Nicholas Ormrod、Peter Dillinger、Pratap Singh、Ramkumar Vadivelu、Sachin Lakhanpal、Sai Bathina、Sankalp Kohli、Sarah Wang、Shrikanth Shankar、Shubham Singhal、Sorin Stoiana、Tejasvi Aswathanarayana、Tyler Heucke、Victoria Tsai、Xiaoyu Wang、Yunqiao Zhang、Zhichao Cao 以及所有为本项目做出重要贡献的同事。
参考文献
[1] [n.d.]. Amazon EBS. https://aws.amazon.com/ebs/.
[2] [n.d.]. Cachelib Repo. https://github.com/facebook/CacheLib.
[3] [n.d.]. Ceph File system. https://docs.ceph.com/en/pacific/cephfs/index.html.
[4] [n.d.]. Distributed locks with Redis. https://redis.io/topics/distlock.
[5] [n.d.]. GlusterFS. https://www.gluster.org/.
[6] [n.d.]. Hbase. https://hbase.apache.org/.
[7] [n.d.]. HDFS. https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html.
[8] [n.d.]. MySQL. https://www.mysql.com/.
[9] [n.d.]. RDMA. http://www.rdmaconsortium.org/.
[10] [n.d.]. RocksDB Benchmark Wiki Page. https://github.com/facebook/rocksdb/wiki/Performance-Benchmarks.
[11] 2009. Rados. https://ceph.io/en/news/blog/2009/the-rados-distributed-object-store/.
[12] 2015. Introduction to HDFS Erasure Coding in Apache Hadoop. https://blog.cloudera.com/introduction-to-hdfs-erasure-coding-in-apache-hadoop/.
[13] 2020. RocksDB-Cloud remote compaction. [https://rockset.com/blog/remote-compactions-in-rocksdb-cloud/.](https://rockset.com/blog/remote-compactions-in-rocksdb-cloud/
[14] 2021. Cachelib. https://engineering.fb.com/2021/09/02/open-source/cachelib/.
[15] 2021. How we built a general purpose key value store for Facebook with ZippyDB. https://engineering.fb.com/2021/08/06/core-data/zippydb/.
[16] Muhammad Yousuf Ahmad and Bettina Kemme. 2015. Compaction management in distributed key-value datastores. Proceedings of the VLDB Endowment 8, 8 (2015), 850–861.
[17] Benjamin Berg, Daniel S. Berger, Sara McAllister, Isaac Grosof, Sathya Gunasekar, Jimmy Lu, Michael Uhlar, Jim Carrig, Nathan Beckmann, Mor Harchol-Balter, and Gregory R. Ganger. 2020. The CacheLib Caching Engine: Design and Experiences at Scale. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, 753–768. https://www.usenix.org/conference/osdi20/presentation/berg
[18] Laurent Bindschaedler, Ashvin Goel, and Willy Zwaenepoel. 2020. Hailstorm: Disaggregated compute and storage for distributed lsm-based databases. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 301–316.
[19] Laurent Bindschaedler, Jasmina Malicevic, Nicolas Schiper, Ashvin Goel, and Willy Zwaenepoel. 2018. Rock You like a Hurricane: Taming Skew in Large Scale Analytics. In Proceedings of the Thirteenth EuroSys Conference (Porto, Portugal) (EuroSys ’18). Association for Computing Machinery, New York, NY, USA, Article 20, 15 pages. https://doi.org/10.1145/3190508.3190532
[20] Wei Cao, Yang Liu, Zhushi Cheng, Ning Zheng, Wei Li, Wenjie Wu, Linqiang Ouyang, Peng Wang, Yijing Wang, Ray Kuan, et al. 2020. {POLARDB} Meets Computational Storage: Eficiently Support Analytical Workloads in {Cloud-Native} Relational Database. In 18th USENIX Conference on File and Storage Technologies (FAST 20). 29–41.
[21] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C Hsieh, Deborah A Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E Gruber. 2008. Bigtable: A distributed storage system for structured data. ACM Transactions on Computer Systems (TOCS) 26, 2 (2008), 1–26.
[22] James C Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, Jeffrey John Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, et al. 2013. Spanner: Google’s globally distributed database. ACM Transactions on Computer Systems (TOCS) 31, 3 (2013), 1–22.
[23] Jeffrey Dean. 2010. Evolution and future directions of large-scale storage and computation systems at Google. (2010).
[24] David DeWitt and Jim Gray. 1992. Parallel database systems: The future of high performance database systems. Commun. ACM 35, 6 (1992), 85–98.
[25] Siying Dong, Mark Callaghan, Leonidas Galanis, Dhruba Borthakur, Tony Savor, and Michael Strum. 2017. Optimizing Space Amplification in RocksDB.. In CIDR, Vol. 3. 3.
[26] Siying Dong, Andrew Kryczka, Yanqin Jin, and Michael Stumm. 2021. RocksDB: Evolution of Development Priorities in a Key-Value Store Serving Large-Scale Applications. ACM Trans. Storage 17, 4, Article 26 (oct 2021), 32 pages. https://doi.org/10.1145/3483840
[27] Peter X Gao, Akshay Narayan, Sagar Karandikar, Joao Carreira, Sangjin Han, Rachit Agarwal, Sylvia Ratnasamy, and Scott Shenker. 2016. Network requirements for resource disaggregation. In 12th USENIX symposium on operating systems design and implementation (OSDI 16). 249–264.
[28] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. 2003. The Google filesystem. In Proceedings of the nineteenth ACM symposium on Operating systems principles. 29–43.
[29] Zvika Guz, Harry Li, Anahita Shayesteh, and Vijay Balakrishnan. 2018. Performance characterization of nvme-over-fabrics storage disaggregation. ACM Transactions on Storage (TOS) 14, 4 (2018), 1–18.
[30] Dave Hitz, James Lau, and Michael A Malcolm. 1994. File System Design for an NFS File Server Appliance.. In USENIX winter, Vol. 94. 10–5555.
[31] Ana Klimovic, Christos Kozyrakis, Eno Thereska, Binu John, and Sanjeev Kumar. 2016. Flash storage disaggregation. In Proceedings of the Eleventh European Conference on Computer Systems. 1–15.
[32] Mihir Nanavati, Jake Wires, and Andrew Warfield. 2017. Decibel: Isolation and Sharing in Disaggregated {Rack-Scale} Storage. In 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). 17–33.
[33] Edmund B Nightingale, Jeremy Elson, Jinliang Fan, Owen Hofmann, Jon Howell, and Yutaka Suzue. 2012. Flat datacenter storage. In 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI 12). 1–15.
[34] Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. 1996. The log-structured merge-tree (LSM-tree). Acta Informatica 33, 4 (1996), 351–385.
[35] Satadru Pan, Theano Stavrinos, Yunqiao Zhang, Atul Sikaria, Pavel Zakharov, Abhinav Sharma, Shiva Shankar P, Mike Shuey, Richard Wareing, Monika Gangapuram, Guanglei Cao, Christian Preseau, Pratap Singh, Kestutis Patiejunas, JR Tipton, Ethan Katz-Bassett, and Wyatt Lloyd. 2021. Facebook’s Tectonic Filesystem: Eficiency from Exascale. In 19th USENIX Conference on File and Storage Technologies (FAST 21). USENIX Association, 217–231. https://www.usenix.org/conference/fast21/presentation/pan
[36] Rockset.2018. RocksDBCloud. https://rockset.com/blog/rocksdb-cloud-enabling-the-next-generation-of-cloud-native-databases/.
[37] Amitabha Roy, Laurent Bindschaedler, Jasmina Malicevic, and Willy Zwaenepoel. 2015. Chaos: Scale-out graph processing from secondary storage. In Proceedings of the 25th Symposium on Operating Systems Principles. 410–424.
[38] Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang. 2018. LegoOS: A Disseminated, Distributed OS for Hardware Resource Disaggregation. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). USENIX Association, Carlsbad, CA, 69–87. https://www.usenix.org/conference/osdi18/presentation/shan
[39] Michael Stonebraker. 1986. The case for shared nothing. IEEE Database Eng. Bull. 9, 1 (1986), 4–9.
[40] Amy Tai, Andrew Kryczka, Shobhit Kanaujia, Chris Petersen, Mikhail Antonov, Muhammad Waliji, Kyle Jamieson, Michael J Freedman, and Asaf Cidon. 2018. Live recovery of bit corruptions in datacenter storage systems. arXiv preprint arXiv:1805.02790 (2018).
[41] Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. 2017. Amazon aurora: Design considerations for high throughput cloud-native relational databases. In Proceedings of the 2017 ACM International Conference on Management of Data. 1041–1052.
[42] Midhul Vuppalapati, Justin Miron, Rachit Agarwal, Dan Truong, Ashish Motivala, and Thierry Cruanes. 2020. Building an elastic query engine on disaggregated storage. In 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20). 449–462.
本文翻译自:
原文链接:Disaggregating RocksDB: A Production Experience
原文采用 CC BY 4.0 授权发布。本文为中文翻译,仅用于学习与分享,版权归原作者所有。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/06-01-2025/disaggregating-rocksdb-a-production-experience-cn.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!