
背景
一个应用于生产环境的监控服务,单机Prometheus往往是无法满足需求的,此时就要搭建一套Prometheus集群,此时就需要考虑:
服务高可用:服务要冗余备份,以消除单点故障。
数据一致性:冗余结点之间数据需要保证一致性。
水平可扩展:可以通过增加服务数量,线性提高服务能力。
数据持久化:节点故障数据不丢失、海量历史数据存储
服务高可用
Prometheus采用Pull模型收集监控数据,服务高可用意味着同一个服务需要至少两个节点同时拉取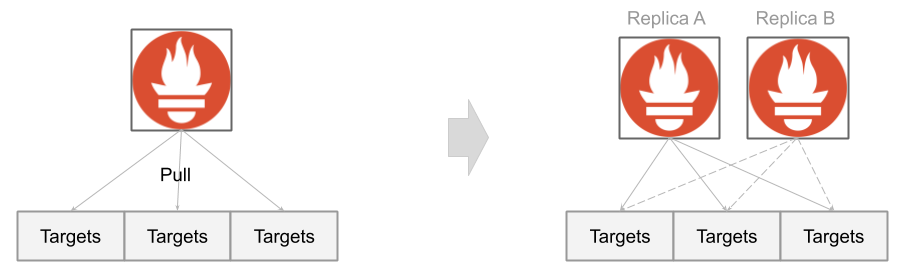
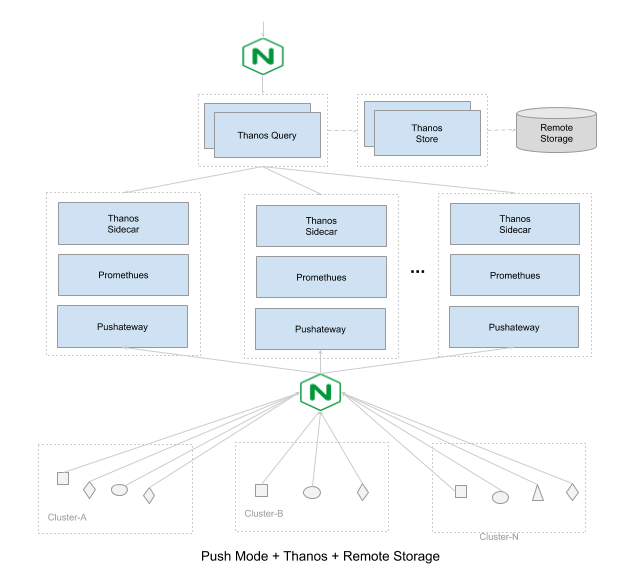
或者切换为Push模型,使用一致性哈希,将不同实例的Metrics推送到固定推送到其中一台服务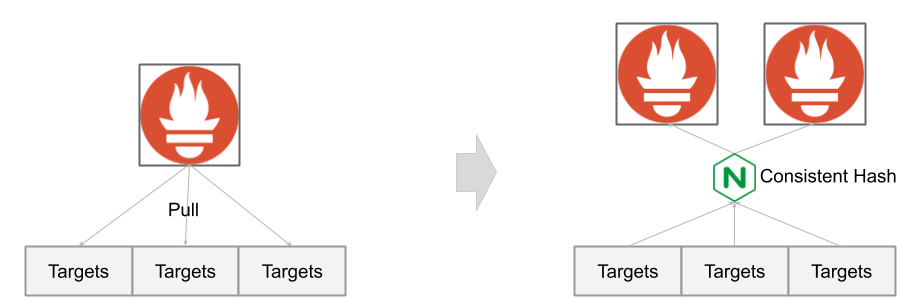
此模式优势是,在保障服务可用性的同时,资源消耗量少一半;新节点不需要重新配置抓取规则,可以做到快速平行扩容。但缺点是,节点故障将导致历史数据丢失。
数据一致性
Pull模式下,冗余节点存在以下两个问题:
两个数据源(Prometheus)的metrics是重复的
两个数据源的同样的metrics有细微差异(两次抓取)
解决这些问题有两种方案:
方案一:使用HA Proxy保证同时只有一个数据源提供服务,另外一个节点作为备份,当检测故障时接管主节点提供服务。
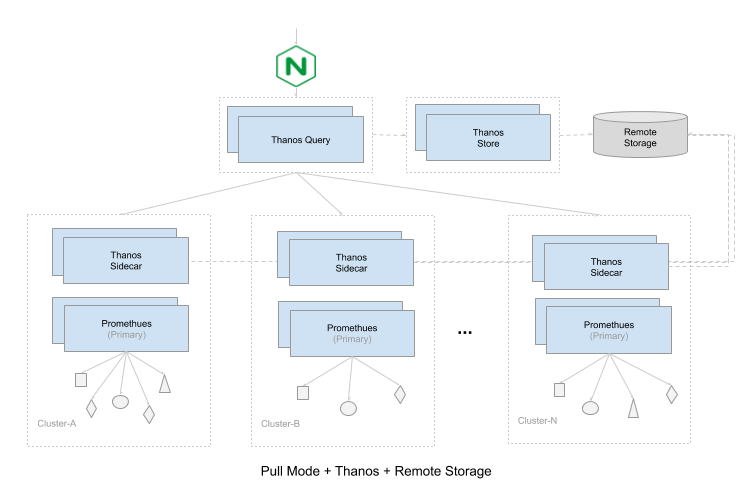
方案二:使用Thanos来接管Prometheus提供服务,将Thanos Sidecar与Prometheus同机部署,Thanos Query可以调用Sidecar获取metrics,并且进行去重。此时 Thanos Query代替Prometheus对外提供Http API接口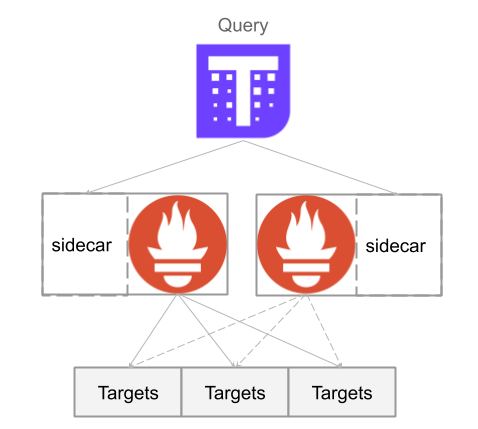
相反,Push模式下,所有节点都可以提供服务,数据没有重复,所以不存在数据一致性的问题。
水平可扩展
Prometheus解决水平扩展的方式是:Sharding。当单台Prometheus Server无法处理大量的采集任务时,用户可以考虑基于Prometheus联邦集群的方式将监控采集任务划分到不同的Prometheus实例。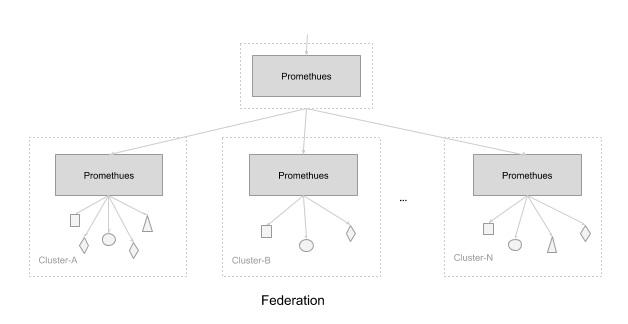
可以根据场景选择根据Sharding的方式
按照功能分区:例如一个Prometheus Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标
按照实例分区:当单个采集任务的Target数也变得非常巨大。简单通过联邦集群进行功能分区,Prometheus也无法有效处理时。需要考虑继续在实例级别进行功能划分
数据持久化
Prometheus的本地存储设计可以减少其自身运维和管理的复杂度,同时能够满足大部分用户监控规模的需求。但是本地存储也意味着Prometheus无法持久化数据,无法存储大量历史数据。Prometheus并没有尝试在自身中解决以上问题,而是让用户可以通过接口将数据保存到任意第三方的分布式存储中,即:Remote Storage。
一旦开始查询历史数据,我们很快便意识到,在我们检索几周,几个月,乃至最终数年的数据时,这里存在的大O复杂度会让查询变得越来越慢。Prometheus暂时并未提供完整的方案来解决该问题,此时需要依靠Thanos解决方案的 Downsampling了。
总结
综上所述,根据不同的业务场景,选择合适的高可用部署方案,并根据自身需求进行灵活调整。下面列出来的是三套完整的高可用的方案: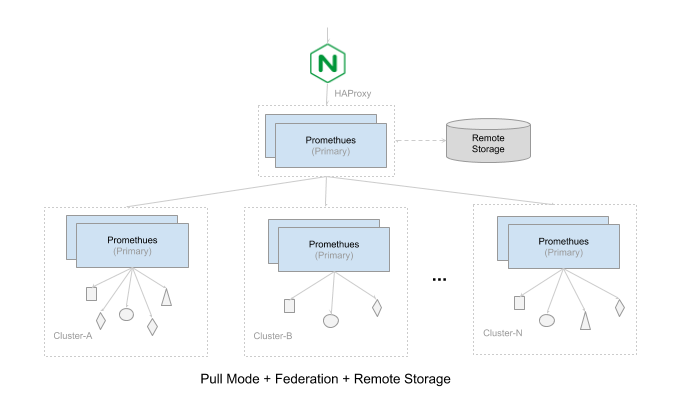
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/09-13-2019/micro-service-monitor-prometheus-ha.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!