
背景
在过去的两年里,我们从零开始搭建了整个事业群的监控。目前整套系统接入200+的服务,700+的实例,收集了上万个指标。不停探索,历经曲折,方得自由。本文主要内容是总结两年间走过的路,趟过的坑,学习到的经验。
一无所有
业务刚开始上线时,是没有任何监控的,所有的监控都是依赖接入层的Nginx的监控数据,所有的故障都是从用户获取到反馈才能发现;排查问题依靠日志系统;从上游服务开始,逐层查询日志。每次发布上线内心都在敲锣打鼓。
疲于奔命
在业务第一个大版本上线之后,我们开始着手给业务系统接入监控,此时的选择是兄弟团队搭建的 openfalcon,使用 grafana 作为看板。基于对立体化监控的理解,开始着手建立各种维度的看板
- 服务维度:
提供 Client、Server 端视图,从服务的状态、性能、质量、容量四个维度,分析需要添加到看板的指标
- 业务维度:
关注业务的关键路径,建立业务监控树,用于出现问题时,快速定位到具体的服务
- 产品维度:
分析产品关键指标,构建公共看板
在这个阶段,我们投入了大量的人力资源到监控中,却收效甚微,主要有以下几点原因:
- 从下往上的构建看板,需要不停的耗费人力补齐遗漏的指标
- 关注服务质量的指标多于关注产品质量指标,对于产品指标缺少足够的认识
- 受限于 openfalcon+grafana的能力,建立和维护 监控和告警,人力成本极高
- 所有人都要摸索熟悉监控的基础概念、门槛高
- 告警与业务关联度不高,业务一有波动就会误告,真正出现问题又发现没有配置告警
在这个阶段,我们投入了大量的人力,建立和维护各种看板,处理各种告警,疲于奔命,却不尽如人意。
前路始现
在第一个版本稳定之后,很长一段时间没有大需求,促使我们考虑如何解决这些问题。同时在这个阶段,在部门内部开始开发自己的RPC框架,基于在微信的工作经验,促使我们把目光投向 Prometheus 等基于数据的监控平台。
在监控方面,我们使用 SDK(数据上报) + Prometheus(数据收集)+ Grafana(监控看板),构建了更灵活方便的看板
- 服务维度
在开发RPC框架的同时,将服务维度的上报直接嵌入框架中,同时提供SDK给兄弟团队用于现有服务的接入。然后统一维护了两套服务看板:全局看板,详细看板。前者负责日常运营,后者负责排查问题。
- 业务&产品维度
SDK设计了统一简单的上报接口,方便构建业务、产品相关的看板
至此,服务维度的数据变成了可以逐渐迭代优化的统一视图,随着经验的积累,对监控的认识越深刻,看板使用越是应手。
在告警方面,使用 Prometheus(数据计算) + Promgen(规则管理) + AlertManager(告警管理) + Webhook (告警调用)+ 企业微信群,构建了完善的告警链条。
方得自由
在监控告警中,我们会频繁遇到以下问题:
- 阈值设定:不同业务场景,不同指标,如何衡量阈值是过于宽松,还是过于严格。
- 流量波动:在理想的世界里,流量是有起伏规律的,监控系统能够掌握这种规律,当流量上升时,告警阈值自动上升
- 瞬态告警:每个人都会遇到这样的情况,同样的问题隔段时间就出现一次,持续时间不过几分钟,来得快去得也快。说实话,你已经忙得不可开交了,近期内也不大会去排除这种问题。是忽略呢?还是忽略呢?
- 信息过载:典型的信息过载场景是,给所有需要的地方都加上了告警,以为这样即可高枕无忧了,结果随着而来的是,各种来源的告警轻松挤满你的收件箱。
- 故障定位:在相对复杂的业务场景下,一个“告警事件” 除了包含“时间”(何时发生)、“地点”(哪个服务器/组件)、“内容”(包括错误码、状态值等)外,还包含地区、机房、服务、接口等,故障定位之路道阻且长。
那么目前我们解决的怎么样了呢?
- 问题 1、2,为了解决该问题,在监控平台里,引入了异常检测算法(anomaly detection) ,得到了很好的解决
- 问题 3,使用Prometheus的能力,得以解决
- 问题 4,我们对告警指标进行分级,只在调用链条的最上游配置细化的重要告警指标,告警之后通过链接跳转到对应的详细看板进行问题排查,告警更少更精确可查,维护起来也更简单了。
- 问题 5,目前仍然没有得到很好的解决,但是已经有了方案,将在后续进一步优化
未来之路
基于 Prometheus 的数据平台能力,可以构建出业务所有服务的调用的树状图,并且当时的错误变化情况,进行自动故障根源分析,这也是我们以后将要做的
附:
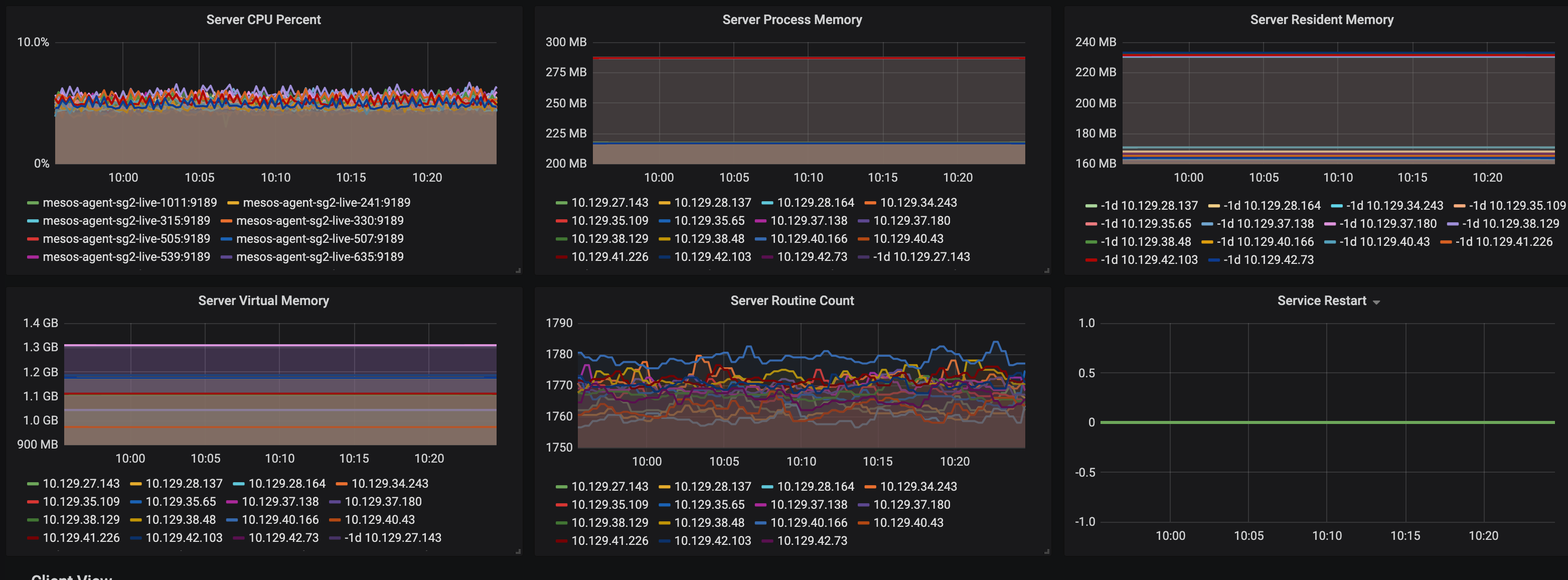
(全局看板部分视图)
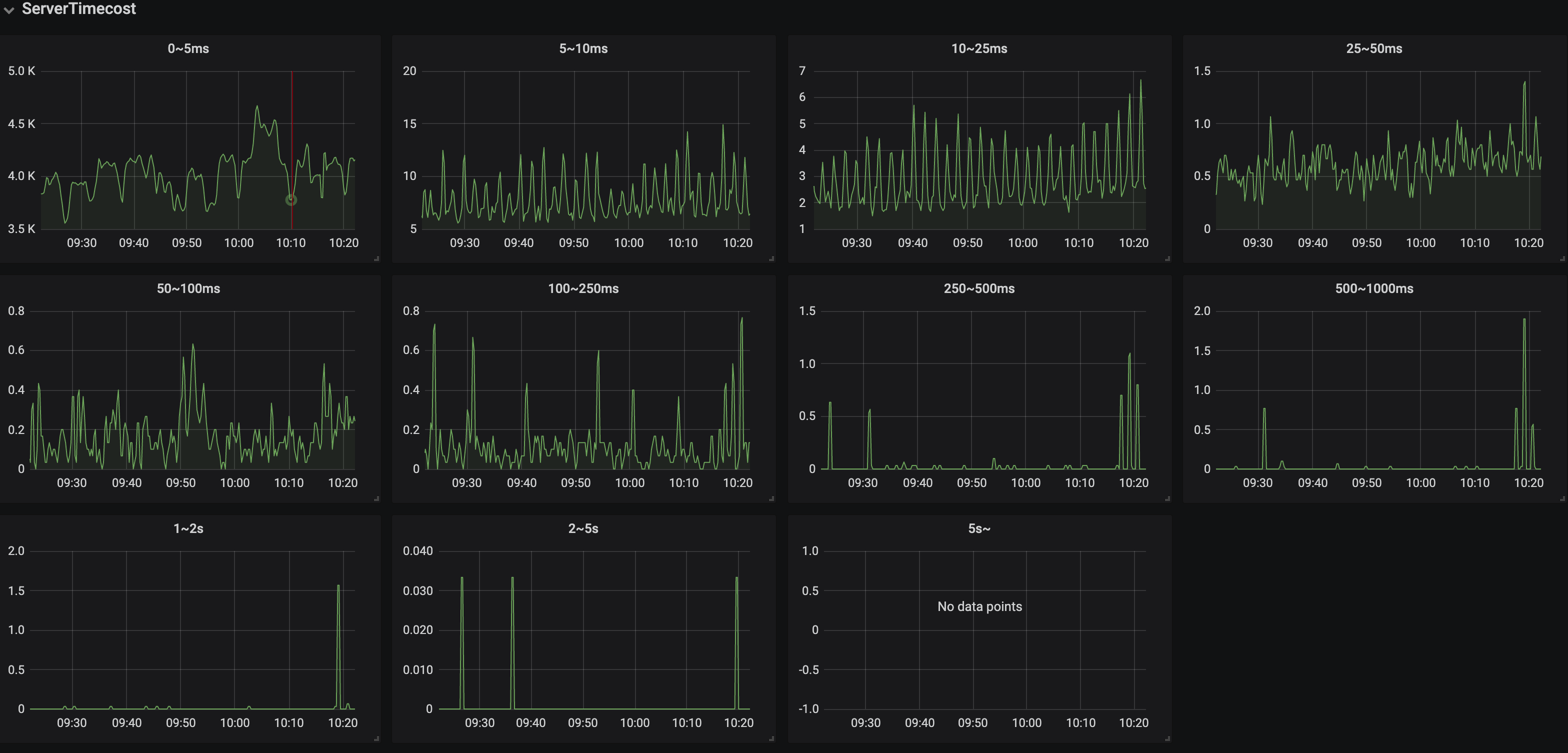
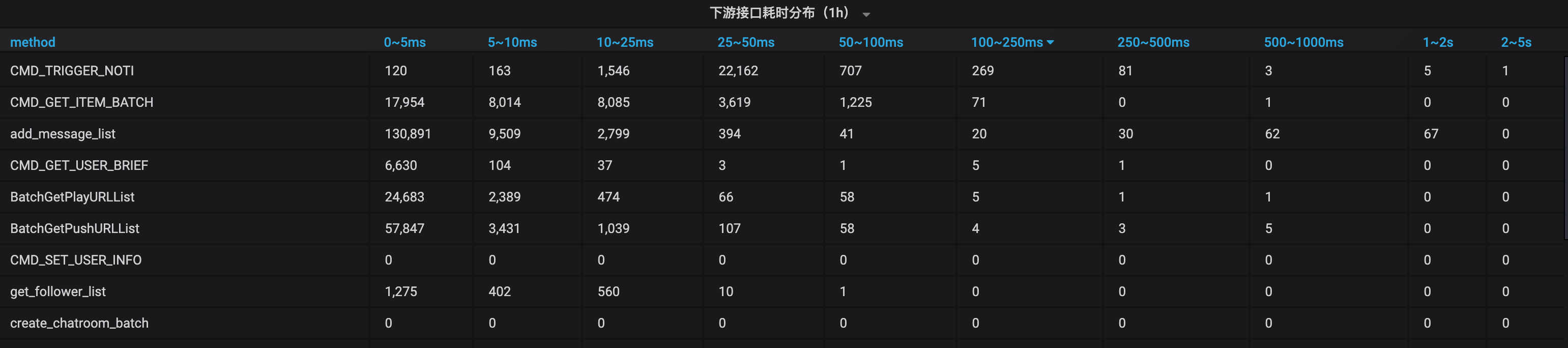
(详细看板部分视图)
参考链接
https://www.jianshu.com/p/06c7dd803d4a
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/03-28-2020/site-reliability-engineering.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!