
- 为什么异常检测有效?
- 正确的聚合级别是什么?
- 使用 z-score 进行异常检测
- 如果不是正态分布怎么办?
- 使用季节性检测异常
- 如何利用季节性?
- 怎么知道预测是真正准确的?
- 如何使用Prometheus设置警报
- 总结
Prometheus 查询语言的最基本功能之一是实时汇总时间序列数据。GitLab基础架构团队的杰出工程师 Andrew Newdigate 认为 Prometheus 查询语言也可以用于检测时间序列数据中的异常。本博客文章解释了异常检测如何与 Prometheus 一起工作,并包括您需要在自己的系统上亲自尝试的代码片段。
为什么异常检测有效?
异常检测对 GitLab 非常重要的四个关键原因:
- 诊断事件:我们可以快速找出哪些服务执行超出正常范围,并减少检测事件的平均时间(MTTD),从而更快地解决问题。
- 检测应用程序性能回归:例如,如果引入 n+1 回归,发现一个服务以很高的速率调用另一个服务,可以迅速找到问题并加以解决。
- 识别并解决滥用问题:GitLab 提供免费计算(GitLab CI/CD)和托管(GitLab Pages),会被一小部分用户加以利用。
- 安全性:异常检测对于发现 GitLab 时间序列数据中的异常趋势至关重要。
由于以上以及其他许多原因,Andrew 研究了是否可以仅通过使用 Prometheus 查询和规则对 GitLab 时间序列数据执行异常检测。
正确的聚合级别是什么?
首先,时间序列数据必须正确聚合。尽管可以将相同的技术应用到许多其他类型的指标,Andrew 使用了标准计数器 http_requests_total 作为数据源进行演示。
http_requests_total{
job="apiserver",
method="GET",
controller="ProjectsController",
status_code="200",
environment="prod"
}上述示例指标有一些额外的维度:method,controller,status_code,environment,如同 Prometheus 添加的维度 instance 和 job 一样。
接下来,您必须为正在使用的数据选择正确的聚合级别。这有点像“金发姑娘问题”-太多,太少还是恰到好处-但这对于发现异常至关重要。过多地汇总数据,数据将缩减为过小的维度,从而产生两个潜在的问题:
- 可能会错过真正的异常,因为聚合隐藏了数据子集中出现的问题。
- 如果确实检测到异常,则不对异常进行更多调查,则很难将其归因于系统的特定部分。
但是,聚合的数据汇太少,最终可能会得到一系列样本量非常小的数据。如此可能导致误报,并可能将真实数据标记为离群值(outliers)。
恰到好处:我们的经验表明,正确的聚合级别是服务级别,因此我们将 job 和 environment 标签包括进来,但删除了其他维度。在本演讲的以下部分中使用的数据聚合包括:job、http requests、五分钟速率(基本上是五分钟窗口中覆盖 job 和 environment 之上的速率)。
- record: job:http_requests:rate5m
expr: sum without(instance, method, controller, status_code)
(rate(http_requests_total[5m]))
# --> job:http_requests:rate5m{job="apiserver", environment="prod"} 21321
# --> job:http_requests:rate5m{job="gitserver", environment="prod"} 2212
# --> job:http_requests:rate5m{job="webserver", environment="prod"} 53091使用 z-score 进行异常检测
一些统计学的主要原理可以应用于 Prometheus 检测异常。
如果知道 Prometheus 序列的平均值和标准偏差(σ),则可以使用该系列中的任何样本来计算 z-score。z-score 表示为:与平均值的标准偏差值。因此 z-score 为 0 表示 z-score 与具有正态分布的数据的平均值相同,而 z-score 为 1 则相对于平均值为 1.0σ,依此类推。
假设基础数据是正态分布的,则 99.7% 的样本的 z-score 应介于 0 到 3 之间。z-score 距离 0 越远,它越不可能出现。我们将此特性应用于检测 Prometheus 序列中的异常。
- 使用样本数量较大的数据计算指标的平均值和标准偏差。在此示例中,我们使用了一周的数据。如果假设我们每分钟评估一次记录规则,那么一周的时间,能获得 10,000 多个样本。
# Long-term average value for the series - record: job:http_requests:rate5m:avg_over_time_1w expr: avg_over_time(job:http_requests:rate5m[1w]) # Long-term standard deviation for the series - record: job:http_requests:rate5m:stddev_over_time_1w expr: stddev_over_time(job:http_requests:rate5m[1w]) - 一旦有了聚合的平均值和标准差,就可以计算 Prometheus 查询的 z-score。
# Z-Score for aggregation ( job:http_requests:rate5m - job:http_requests:rate5m:avg_over_time_1w ) / job:http_requests:rate5m:stddev_over_time_1w
根据正态分布的统计原理,我们可以假设任何超出大约 +3 到 -3 范围的值都是异常。我们可以围绕这一原则建立警报。例如,当聚合超出此范围超过五分钟时,我们将收到警报。
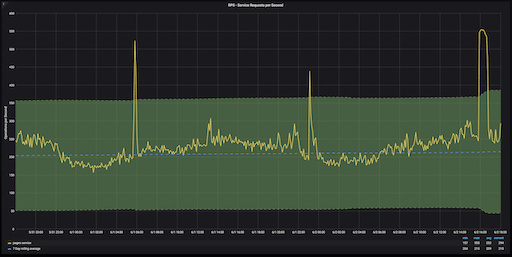
GitLab.com 页面服务 48 小时的 RPS, ±3 z-score 区域为绿色
z-score 在图形上难以解释,因为它们没有度量单位。但是此图表上的异常很容易检测。出现在绿色区域(表示 z-score 在 +3 或 -3 范围内)之外的任何值都是异常。
如果不是正态分布怎么办?
但是,请稍等:我们大跃进的假设潜在的聚合具有正态分布。如果我们使用非正态分布的数据计算 z-score,结果将不正确。有许多统计技术可以测试您的数据是否为正态分布,但是最好的选择是测试您的潜在数据的 z-score 约为 +4 到 -4。
(
max_over_time(job:http_requests:rate5m[1w]) - avg_over_time(job:http_requests:rate5m[1w])
) / stddev_over_time(job:http_requests:rate5m[1w])
# --> {job="apiserver", environment="prod"} 4.01
# --> {job="gitserver", environment="prod"} 3.96
# --> {job="webserver", environment="prod"} 2.96
(
min_over_time(job:http_requests:rate5m[1w]) - avg_over_time(job:http_requests:rate5m[1w])
) / stddev_over_time(job:http_requests:rate5m[1w])
# --> {job="apiserver", environment="prod"} -3.8
# --> {job="gitserver", environment="prod"} -4.1
# --> {job="webserver", environment="prod"} -3.2两个 Prometheus 查询测试 z-score 的最小和最大值。
如果结果返回的范围是 +20 到 -20,则尾巴太长,结果将倾斜。还要记住,这需要在聚合而不是非聚合的序列上运行。可能没有正态分布的指标包括诸如错误率、等待时间、队列长度等,但是无论如何,在固定阈值下告警,许多这些指标都趋向于工作的很好。
使用季节性检测异常
尽管时间序列数据为正态分布时,计算 z-score 效果很好,但是还有第二种方法可以产生更准确的异常检测结果。季节性是时间序列指标的一个特征,其中该指标会经历定期且可预测的变化,这些变化会在每个周期重复出现。
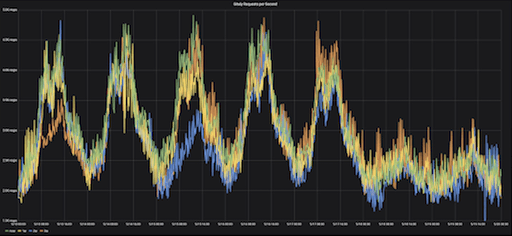
周一至周日连续四个星期的每秒 Gitaly 请求(RPS)
该图说明了连续四周的周一到周日的7天中 Gitaly 的 RPS(每秒请求数)速率。七天范围称为“偏移”,表示需要度量的模式。图上的每个星期都有不同的颜色。数据的季节性由图表中所示趋势的一致性表示 —— 每个星期一早晨,RPS 速率都会上升,而在星期五晚上,RPS 速率会逐渐下降,每周如此。
通过利用时间序列数据中的季节性,可以创建更准确的预测,从而更好地进行异常检测。
如何利用季节性?
使用 Prometheus 计算季节性,需要在一些不同的统计原理上迭代。
在第一次迭代中,我们通过将目前滚动的一周的增长趋势(注:平均值)与前一周的值相加来计算。通过从目前滚动的一周平均值中减去上周的滚动一周平均值来计算增长趋势。
- record: job:http_requests:rate5m_prediction
expr: >
job:http_requests:rate5m offset 1w # Value from last period
+ job:http_requests:rate5m:avg_over_time_1w # One-week growth trend
- job:http_requests:rate5m:avg_over_time_1w offset 1w第一次迭代有点狭窄;我们使用本周和上周的五分钟窗口来得出我们的预测。
在第二次迭代中,将上周的四个小时平均值作为平均值,并将其与本周进行比较,以扩大范围。因此,如果要预测一个星期一上午8点的指标值,不是使用一周前的相同五分钟窗口,而是使用前一周早上的上午6点至上午10点的指标平均值。
- record: job:http_requests:rate5m_prediction
expr: >
avg_over_time(job:http_requests:rate5m[4h] offset 166h) # Rounded value from last period
+ job:http_requests:rate5m:avg_over_time_1w # Add 1w growth trend
- job:http_requests:rate5m:avg_over_time_1w offset 1w在查询中使用166个小时而不是一周,因为要根据一天中的当前时间使用四个小时,因此需要将偏移减少两个小时。
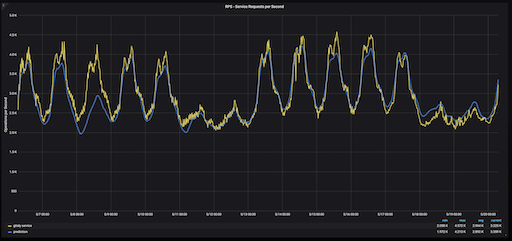
两周的 Gitaly 服务 RPS(黄色)vs 预测(蓝色)。
将实际的 Gitaly RPS(黄色)与 预测(蓝色)进行比较表明,计算相当准确。但是,这种方法有缺陷。因为5月1日是国际劳动节,一个许多国家庆祝的节日,GitLab 的使用量低于平常的星期三。由于增长率是由前一周的使用情况决定的,因此我们对下周(5月8日,星期三)RPS 的预测会比 如果5月1日(星期三)没有假期更低。
可以通过在5月1日(星期三)之前连续三周(之前的星期三,再之前的星期三和三周之前的星期三)进行三个预测来解决此问题。查询保持不变,但偏移量已调整。
- record: job:http_requests:rate5m_prediction
expr: >
quantile(0.5,
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 166h)
+ job:http_requests:rate5m:avg_over_time_1w - job:http_requests:rate5m:avg_over_time_1w offset 1w
, "offset", "1w", "", "")
or
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 334h)
+ job:http_requests:rate5m:avg_over_time_1w - job:http_requests:rate5m:avg_over_time_1w offset 2w
, "offset", "2w", "", "")
or
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 502h)
+ job:http_requests:rate5m:avg_over_time_1w - job:http_requests:rate5m:avg_over_time_1w offset 3w
, "offset", "3w", "", "")
)
without (offset)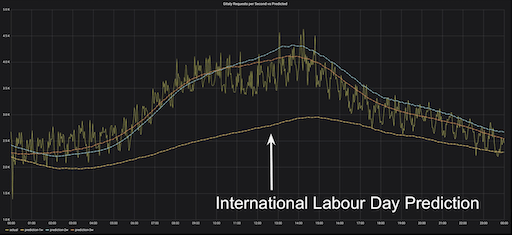
三个星期三的三个预测与实际 5月8日(星期三,国际劳动节之后的一周)的 Gitaly RPS
在该图上,绘制了5月8日星期三和5月8日之前连续三个星期的三个预测。可以看到其中两个预测是好的,但是5月1日的预测仍远未达到基准。
而且,我们不需要三个预测,我们想要一个预测。取平均值是不可行的,因为它将被倾斜的 5月1日 RPS数据所稀释。相反,我们要计算中位数。Prometheus没有中位数查询,但可以使用分位数聚合来代替中位数。该方法的一个问题是,试图在一个聚合中包括三个系列,而这三个系列实际上在三周内都是相同的系列。换句话说,它们都具有相同的标签,因此连接它们很棘手。为避免混淆,我们创建了一个名为 offset 的标签,并使用 label-replace 函数为三个星期添加offset。接下来,在分位数聚合中,将其去除,以获得了三个中间值。
- record: job:http_requests:rate5m_prediction
expr: >
quantile(0.5,
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 166h)
+ job:http_requests:rate5m:avg_over_time_1w - job:http_requests:rate5m:avg_over_time_1w offset 1w
, "offset", "1w", "", "")
or
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 334h)
+ job:http_requests:rate5m:avg_over_time_1w - job:http_requests:rate5m:avg_over_time_1w offset 2w
, "offset", "2w", "", "")
or
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 502h)
+ job:http_requests:rate5m:avg_over_time_1w - job:http_requests:rate5m:avg_over_time_1w offset 3w
, "offset", "3w", "", "")
)
without (offset)现在,从三个聚合系列中得出中值的预测更加准确。
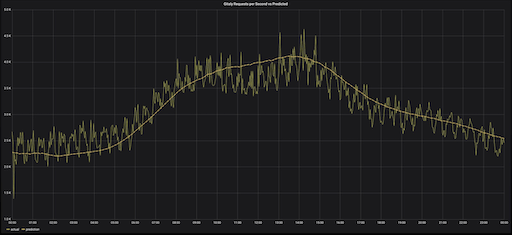
中位数预测与实际 Gitaly RPS 的比较,5月8日(星期三,国际劳动节之后的一周)
怎么知道预测是真正准确的?
为了测试预测的准确性,可以返回 z-score。可以使用 z-score 来测量样本与标准偏差预测值之间的差距。偏离预测的标准偏差越多,则特定值是异常可能性就越大。
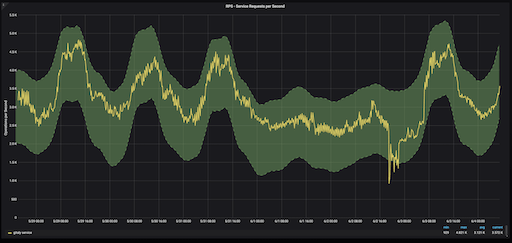
Gitaly 服务的预测正常范围 ±1.5σ
我们可以更新 Grafana 图表以使用季节性预测而不是每周滚动平均值。一天中特定时间的正常范围以绿色阴影显示。任何落在绿色阴影区域之外的东西都被认为是异常值。在这种情况下,离群值发生在周日下午,此时我们的云提供商遇到了一些网络问题。在我们的预测的任一侧使用±2σ的边界是确定季节性预测的异常值的一种很好的方法。
如何使用Prometheus设置警报
如果要为异常事件设置警报,可以对 Prometheus 应用一个非常简单的规则,该规则检查指标的 z-score 是否在标准偏差 +2 或 -2 之间。
- alert: RequestRateOutsideNormalRange
expr: >
abs(
(
job:http_requests:rate5m - job:http_requests:rate5m_prediction
) / job:http_requests:rate5m:stddev_over_time_1w
) > 2
for: 10m
labels:
severity: warning
annotations:
summary: Requests for job {{ $labels.job }} are outside of expected operating parameters在 GitLab,我们使用了自定义路由规则,该规则会在检测到任何异常时 pings Slack,但不会寻呼值班的支持人员。
总结
- Prometheus 可用于某些类型的异常检测
- 正确级别的数据聚合是异常检测的关键
- 如果数据具有正态分布,则 z-score 是一种有效的方法
- 季节性指标可以为异常检测提供出色的结果
视频链接:https://vimeo.com/341141334
原文链接:https://about.gitlab.com/blog/2019/07/23/anomaly-detection-using-prometheus/
本文翻译仅用于学习与技术交流,版权归原作者所有,如有侵权请联系删除。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/01-22-2020/use-prometheus-for-anomaly-detection.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!