
背景
随着在 Kubernetes 场景打磨下不断成长, etcd 逐渐成为技术圈众所周知的开源产品。
- 多版本并发控制
- 事务
- 租约
- 变更通知
etcd 因其丰富的功能,并被越来越多的选择,甚至于被当作 “银弹” 过度使用。本文的重点在于了解其发展历程、实现细节,并针对技术方案选型给出自己的理解。
本文所有内容基于 etcd v3.5.0
起源
2013 年,有一个叫 CoreOS 的创业团队,需要一个协调服务来存储服务配置信息、提供分布式锁等能力,来构建一款叫做 Container Linux 的产品。当分析过需求场景、痛点和核心目标,并评估社区开源的选项之后,CoreOS 团队最终选择自己造轮子,从 0 到 1 开发 etcd 以满足其需求。
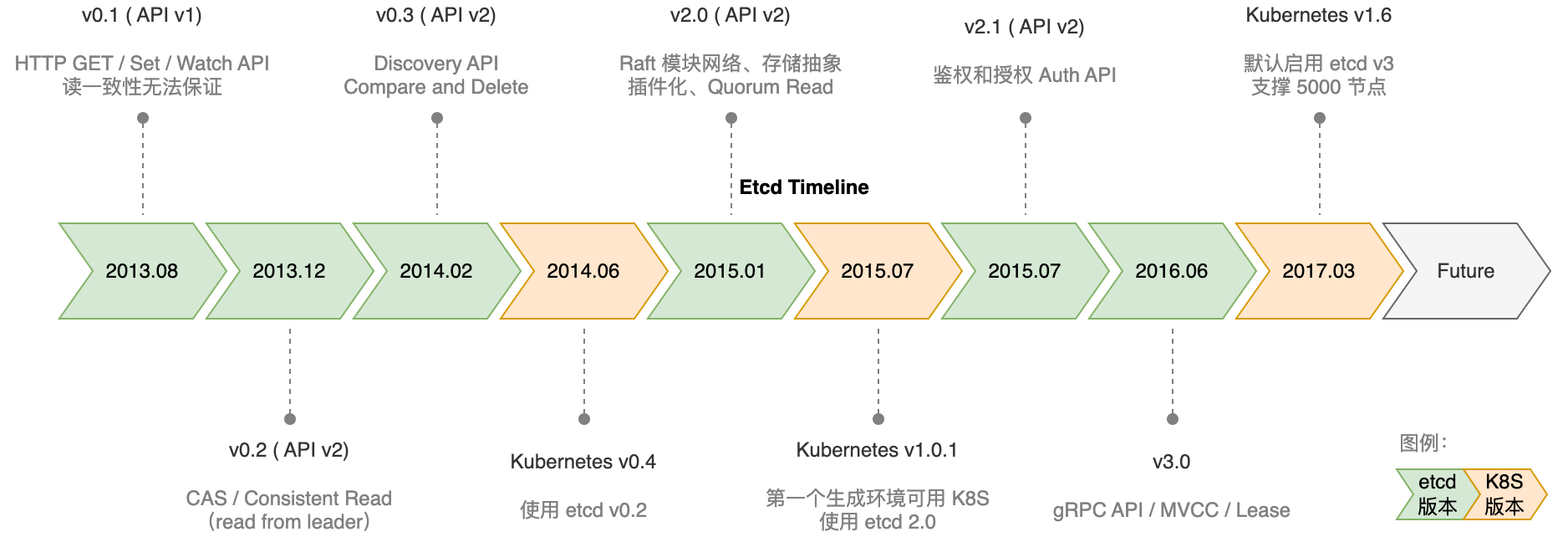
时间线
基础架构
集群架构
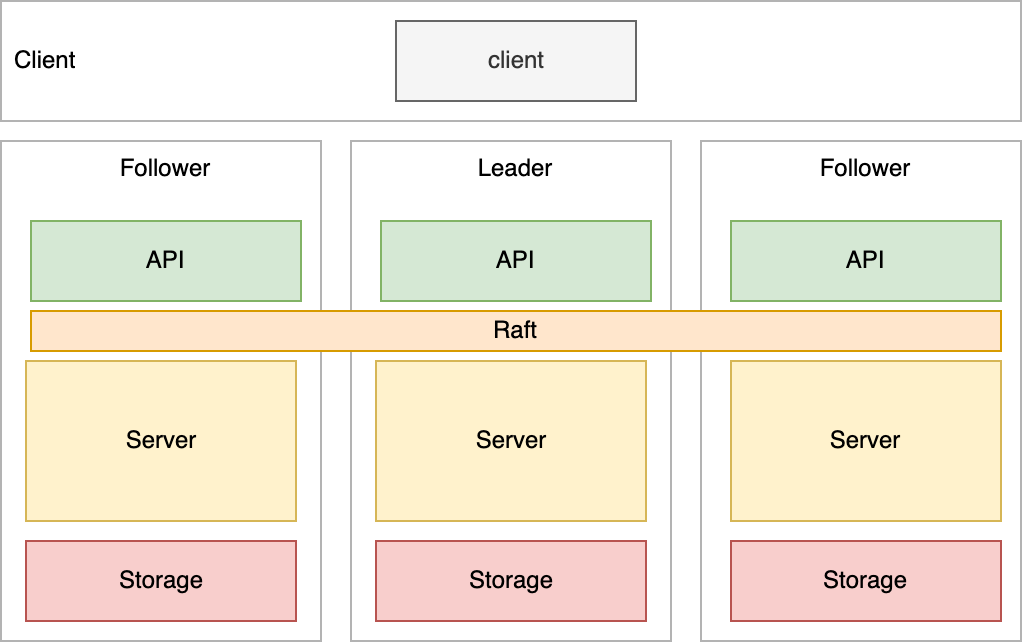
架构说明
- 集群由一个 Leader 节点和 多个 Follower 节点组成,通过 Raft 协议达成共识
- 写请求:只有 Leader 节点能处理写请求,如果当前节点只是一个 Follower,则它会把请求转发给 Leader 处理。
- 读请求:
- 串行读:直接读状态机数据返回、无需通过 Raft 协议与集群进行交互。
- 线性读:如果当前节点只是一个 Follower,它首先会从 Leader 获取集群最新的已提交的日志索引 (committed index)。然后等待直到状态机已应用索引 (applied index) 大于等于 Leader 的已提交索引时 (committed Index),再读取数据返回。
单机架构
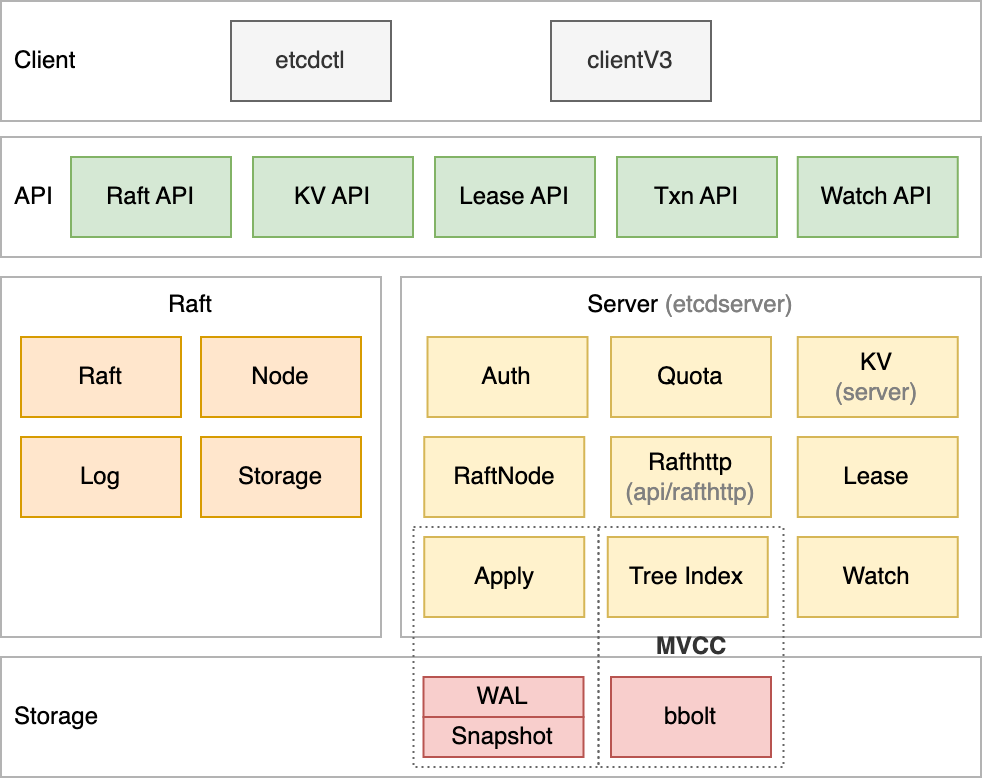
架构说明
- Client(客户端层):包含 Client v2 和 v3 两个⼤版本 API 客户端。
- API(网络层):
- 包含 Client 访问 Server、Server 节点之间的通信协议
- Client 访问 Server 协议有两个版本:v2 API 采⽤ HTTP/1.x 协议,v3 API 采用 gRPC 协议
- Server 节点之间使用 HTTP 协议,通过 Raft 算法实现数据复制和 Leader 选举等功能
- Raft(一致性算法层):维护节点的 Raft 状态机、Raft 日志等保障 etcd 多节点间的数据⼀致性
- Server(业务逻辑层):
- 包括:Auth 鉴权模块、Quota 配额模块、KV 模块、Raftnode 一致性模块、Rafthttp 一致性通信模块、Lease 租约模块、Apply 持久化应用模块、MVCC 多版本并发控制模块、Watch 变更通知模块等
- MVCC 模块主要由 treeIndex B 树索引模块和 boltdb B+ 树数据库模块组成
- Storage:存储层
- 包含 WAL 预写⽇志模块、Snapshot 快照模块、boltdb 数据库模块
- WAL 保障异常后数据不丢失,boltdb 则保存了集群元数据和写⼊的数据
核心工作流
数据写入
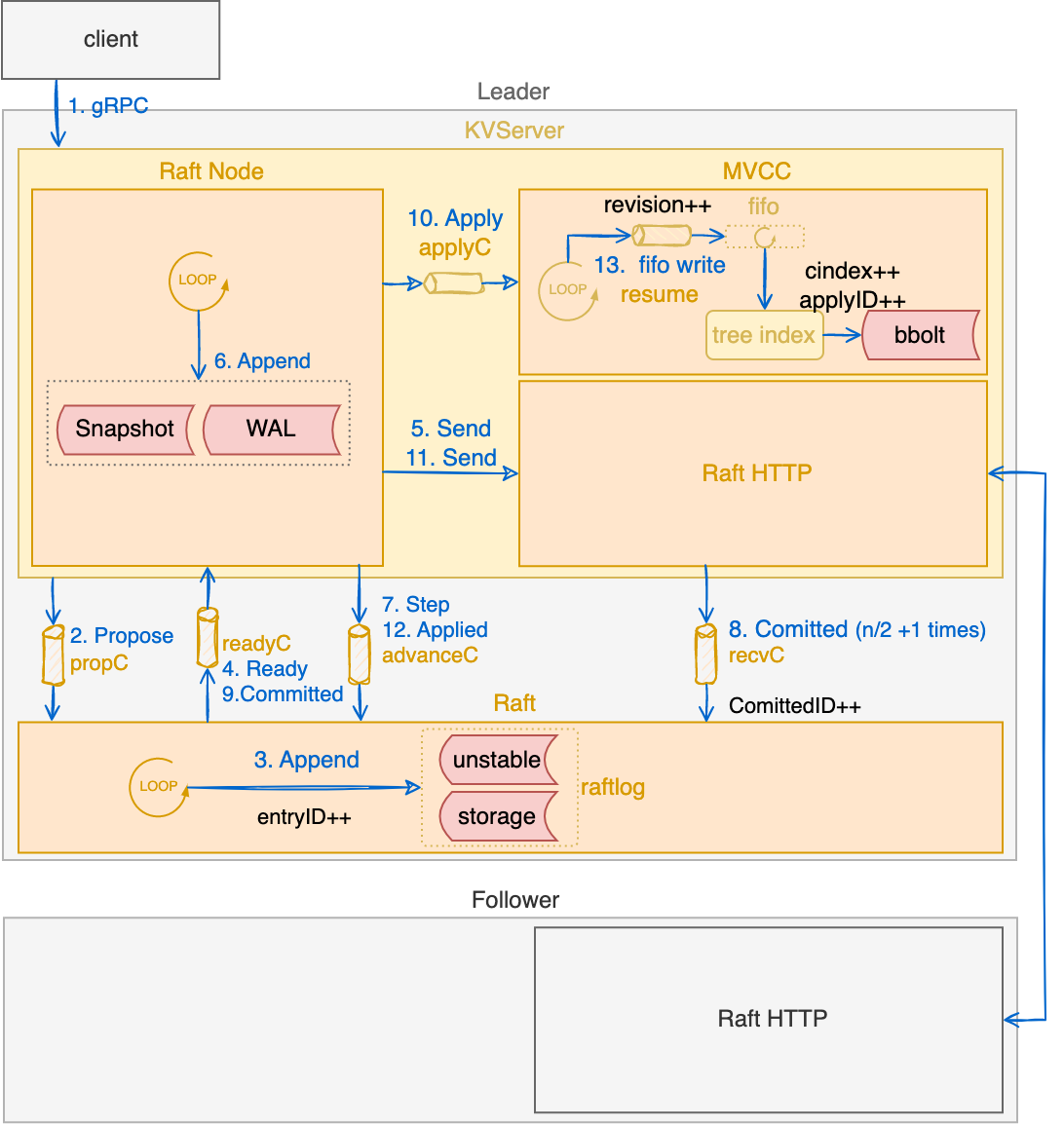
步骤:
- 客户端发送一个 Put 请求给 KVServer。
- KVServer 将请求数据进行适当的封装处理之后,调用 Raft 模块的 Propose 接口方法(步骤 2),由 raft 模块来处理写请求。
- Raft 模块将记录 (entry) 添加到当前节点的 raftLog (步骤 3),并通知 RaftNode 模块执行相关操作 (步骤 4)
- RaftNode 模块
- 首先,广播给其他节点(Follower)(步骤 5)
- 同时,将记录保存到本地 WAL 文件中(步骤 6)
- 最后,告诉 Raft 模块开始等待其他节点提交响应(步骤 7)
- 其它节点(Follower)接收到记录,并写到本地 raftlog 之后,就会给 Leader 发送一个响应。当 Leader 接收到超过半数节点的响应后,就认为这条记录已经 commit ,会更新本地 raftlog 的 commitID(步骤 8)。
- 一旦记录被 Raft 模块 commit 了,就开始通知 RaftNode 模块执行相关操作(步骤 9)。 RaftNode 模块应用(apply)数据记录(步骤 10),同时也将 commitID 广播给其它节点(步骤 11),然后通知 Raft 模块数据已经提交(步骤 12)。
- MVCC 模块异步 将数据应用(apply)到本地存储(步骤 13),并通知 KVServer。
- 最后 KVServer 将结果返回给 client,整个过程就处理结束了。
从上面的流程可以看出,一条记录首先是写入本地的 raftlog。然后发送给其它节点,当超过半数的节点接收到这条记录时,那么该记录就被认为已经 commit 了。最后才能被 KVServer apply。 所以下面的条件永远成立:
ApplyId <= CommitId <= RaftLogId复制状态机
etcd 使用 Raft 协议来维护集群内各个节点状态的一致性。每个 etcd 节点都维护了一个状态机,并且任意时刻至多存在一个有效的主节点。主节点处理所有来自客户端写操作,通过 Raft 协议保证写操作对状态机的改动会可靠的同步到其他节点。
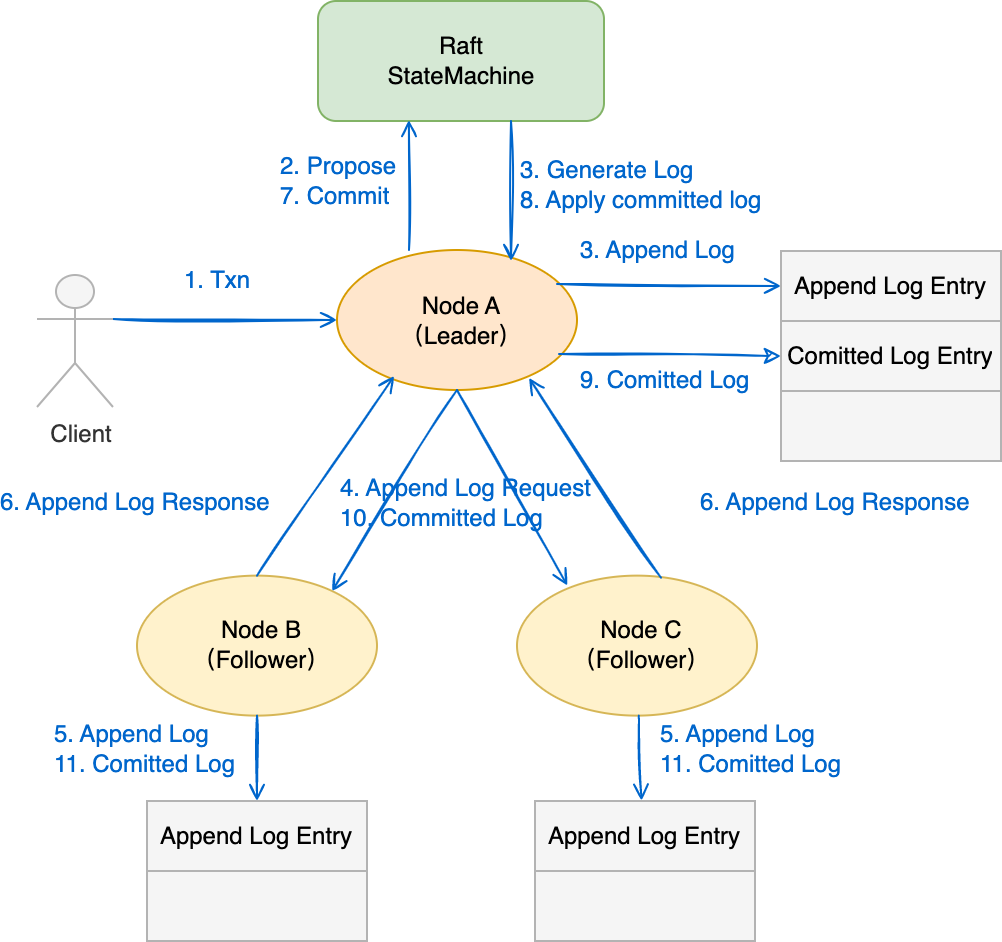
步骤:
- Client 客户端向 KVServer 发送请求
- Server 接收到请求后,向 Raft 模块提交 Proposal
- Raft 模块获取到 Proposal 后,会为 Proposal 生成日志条目,并追加到本地日志
- Leader 会向 Follower 广播消息,为每个 Follower 生成追加的 RPC 消息,包括复制给 Follower 的日志条目
- Follower 会持久化消息到 WAL 日志中,并追加到日志存储
- Follower 向 Leader 回复一个应答日志条目的消息,告知 Leader 当前已复制日志的最大索引
- Leader 在收到 Follower 的应答后,将已复制日志的最大索引信息更新到跟踪 Follower 进展的 Match Index 字段
- Leader 根据 Follower 的 MatchIndex 信息,计算出一个位置。如果该位置已经被一半以上的节点持久化,那么这个日志之前的日志条目都可以标记为已提交
- Leader 发送消息到 Follower 节点时,告知目前已经提交的索引位置
- 各个节点根据已提交的日志条目,将内容应用(apply)到存储、状态机
租约
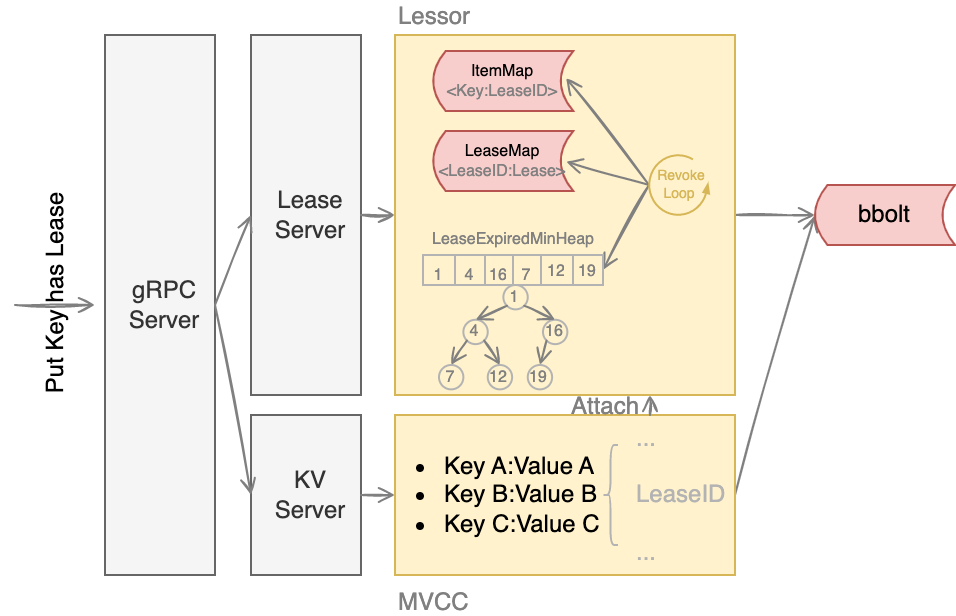
创建租约:
- 当 LeaseServer 收到 Client 的创建一个 Lease 请求后,会通过 Raft 模块
完成日志同步 - 随后 Apply 模块通过 Lessor 模块的 Grant 接口执行日志条目内容。
- 首先 Lessor 的 Grant 接口会把 Lease 保存到内存的 ItemMap 数据结构中
- 然后它需要持久化 Lease,将 Lease 数据保存到 boltdb 的 Lease bucket
- 最终返回一个唯一的 LeaseID 给 client。
附加租约:
- 当用户新增一个带 租约的 Key 时,MVCC 模块它会通过 Lessor 模块的 Attach 方法,将 key 关联到 Lease 的 key 内存集合 ItemMap。
淘汰租约:
- 淘汰过期 Lease 的工作由 Lessor 模块的一个异步 goroutine 负责。它会定时从最小堆中取出已过期的 Lease,执行删除 Lease 和其关联的 key 列表数据的 RevokeExpiredLease 任务。
- Lessor 模块会将已确认过期的 LeaseID,保存在一个名为 expiredC 的 channel 中,而
etcd server 的主循环会定期从 channel 中获取 LeaseID,发起 revoke 请求,通过 Raft
Log 传递给 Follower 节点。 - 各个节点收到 revoke Lease 请求后,获取关联到此 Lease 上的 key 列表,从 boltdb 中 删除 key,从 Lessor 的 Lease map 内存中删除此 Lease 对象,最后还需要从 boltdb 的 Lease bucket 中删除这个 Lease。
注意:
租约影响性能因素源自多方面:
- 首先是 TTL,TTL 过长会导致节点异常后,无法及时从 etcd 中删除,影响服务可用性,而过短,则要求 client 频繁发送续期请求。
- 其次是 Lease 数,如果 Lease 成千上万个,那么 etcd 可能无法支撑如此大规模的 Lease 数,导致高负载。
- 再次,Lease 过期会触发写请求,再加上变更通知产生的读请求,对 etcd server 压力非常大。
- 最后,如果因为网络异常无法续期,导致数据过期。网络恢复正常,同一份数据再次写入,将导致 DB 大小迅速增加(历史版本数据并没有真正删除,数据库压缩才会实际删除)。
从实际使用场景上来,为了降低 Lease TTL 过期带来的影响,可以将 Lease 与 Key 独立开,由系统自行控制和判定存活状态和 Key 的删除。
为了降低 etcd server 的压力可以把多个 kv 关联在一个 lease 上的,比如:
kubernetes 场景中有大量的 event,如果一个 event 一个 Lease, Lease 数量是非常多的,Lease 过期会触发大量写请求,再加上变更通知产生的读请求,对 etcd server 压力非常大。
为了解决这个问题对 etcd server 性能的影响,Lease 过期淘汰会默认限速每秒 1000 个。因此 kubernetes 场景为了优化 Lease 数,会将最近一分钟内产生的 event key 列表,复用在同一个 Lease,大大降低了 Lease 数。
变更通知
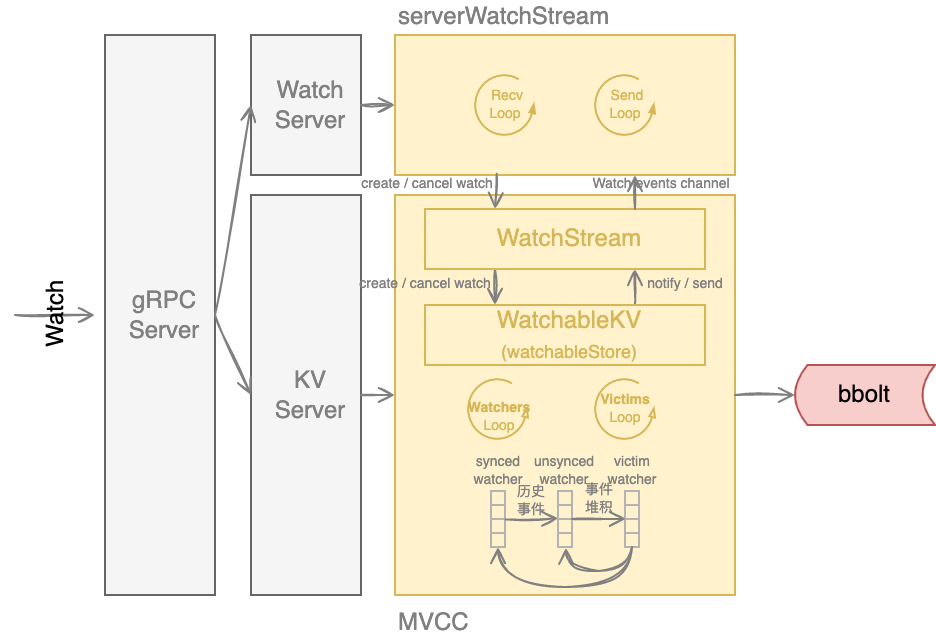
概念:
etcd 通过对 watcher 进行分类,来实现事件的可靠性:
- synced watcher,此类 watcher 监听的数据都已经同步完毕,在等待新的变更。
- unsynced watcher,此类 watcher 监听的数据还未同步完成,落后于当前最新数据变更,正在努力追赶。
- victim watcher,此类 slower watcher 的推送 channel buffer 堆满,etcd 会将其移动到专门的队列中异步机制重试。
订阅流程:
当 Client 发起一个 watch key 请求的时候,etcd 的 WatchServer 收到 watch 请求后,会创建一个 serverWatchStream, 它负责接收 client 的 gRPC Stream 的 create/cancel watcher 请求 (recvLoop goroutine),并将从 MVCC 模块接收的 Watch 事件转发给 client(sendLoop goroutine)。
当 serverWatchStream 收到 create watcher 请求后,serverWatchStream 会调用 MVCC 模块的 WatchStream 子模块分配一个 watcher id,并将 watcher 注册到 MVCC 的 WatchableKV 模块。
etcd 启动后,WatchableKV 模块会运行 syncWatchersLoop 和 syncVictimsLoop goroutine,分别负责不同场景下的事件推送。
etcd 使用 map 记录了监听单个 key 的 watcher,但是你要注意的是 Watch 特性不仅仅可以监听单 key,它还可以指定监听 key 范围、key 前缀,因此 etcd 还使用了区间树。当收到创建 watcher 请求的时候,它会把 watcher 监听的 key 范围插入到上面的区间树中,区间的值保存了监听同样 key 范围的 watcher 集合 /watcherSet。
当产生一个事件时,etcd 首先需要从 map 查找是否有 watcher 监听了单 key,其次它还需要从区间树找出与此 key 相交的所有区间,然后从区间的值获取监听的 watcher 集合。区间树支持快速查找一个 key 是否在某个区间内,时间复杂度 O(LogN),因此 etcd 基于 map 和区间树实现了 watcher 与事件快速匹配,具备良好的扩展性。
推送流程:
- 当你创建完成 watcher 后,此时你执行 put hello 修改操作时,如上图所示,请求经过后的 mvccpb.KeyValue 保存到一个 changes 数组中。
- 在 put 事务结束时,它会将 KeyValue 转换成 Event 事件,然后回调 watchableStore.notify 函数。notify 会匹配出监听过此 key 并处于 synced watcherGroup 中的 watcher,同时事件中的版本号要大于等于 watcher 监听的最小版本号,才能将事件发送到此 watcher 的事件 channel 中。
注意:
若 watcher 监听的版本号已经小于当前 etcd server 压缩的版本号,历史变更数据就可能
已丢失,因此 etcd server 会返回 ErrCompacted 错误给 client。client 收到此错误后,需重新获取数据最新版本号后,再次 Watch。在业务开发过程中,使用 Watch API 最常见的一个错误之一就是未处理此错误。
其次,Watch 返回的 WatchChan 有可能在运行过程中失败而关闭,此时 WatchResponse.Canceled 会被置为 true,WatchResponse.Err() 也会返回具体的错误信息。所以在 range WatchChan 的时候,每一次循环都要检查 WatchResponse.Canceled,在关闭的时候重新发起 Watch 或报错。
选型分析
方案选型可以从业务系统的需求和 etcd 的特性、性能,两个方面着手。
业务系统
先看使用 etcd 提供服务的目标系统。如果你正在深入 Kubernetes 或开始使用服务网格,您可能会遇到术语“控制平面(control plane)”和“数据平面(data plane)”。术语 “控制平面” 和 “数据平面” 都是关于关注点的分离,即系统内职责的明确分离。控制平面是一切与策略建立和下发有关的部分,而数据平面是一切与执行策略有关的部分。当控制平面出现故障,只会影响新的策略变更变更,但不会影响已有策略执行,即,数据平面的功能。
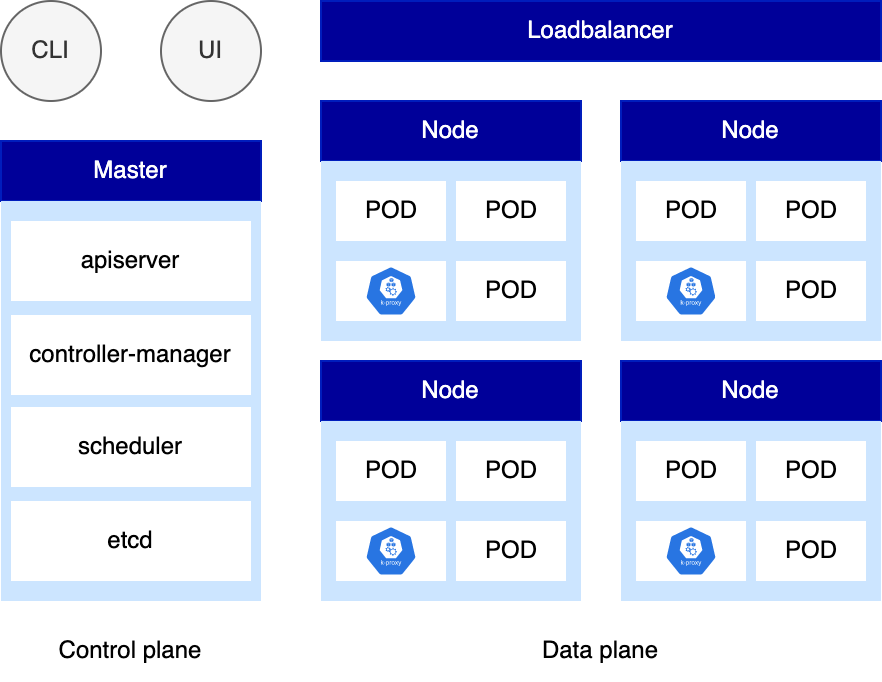
以 Kubernetes 为例,其核心服务包括:
| 组件 | 描述 |
|---|---|
| kube-apiserver | 提供了资源的唯一入口,并提供认证、授权、访问控制、API 注册和发现等 |
| kube-scheduler | 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上 |
| kube-controller-manager | 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等 |
| etcd | 存储整个集群的状态 |
| kube-proxy | 负责为 Service 提供 cluster 内部的服务发现和负载均衡 |
以上服务故障,并不会影响当前已有 Pod 正常对外提供服务。
Why etcd
再看 etcd 本身。要了解 etcd 适用的场景,质量最高的来源是其官网。
介绍:
“etcd” 名字来源于两个想法:unix “/etc” 文件夹和 分布式( “d”istributed)系统。“/etc” 文件夹是存储单个系统的配置数据的地方,而 etcd 存储大规模分布式系统的配置信息。因此,“d”istributed “/etc” 是 “etcd”。etcd 被设计为大规模分布式系统的通用基座。这类系统永远不容忍裂脑操作,并愿意牺牲可用性来实现该目标。
分布式系统使用 etcd 用于配置管理、服务发现和协调分布式工作。etcd 的常见分布式模式包括领导者选举、分布式锁和监控机器活动。
使用场景:
- CoreOS 的 Container Linux:在 Container Linux 上运行的应用程序可以获得自动、零停机的 Linux 内核更新。Container Linux 使用 Locksmith 来协调更新。Locksmith 在 etcd 上实现了分布式信号量,以确保在任何给定时间只有集群的一个子集在重新启动。
- Kubernetes 将配置数据存储到 etcd 中,用于服务发现和集群管理;etcd 的一致性对于正确调度和操作服务至关重要。Kubernetes API 服务器将集群状态持久化为 etcd。它使用 etcd 的 watch API 来监视集群并生效关键的配置变更。( 2016 年 Kubernetes 1.6 发布,默认启用 etcd v3,助力 Kubernetes 支撑 5000 节点集群规模)
其他:
- 最大可靠数据库大小: 数 GB
- 因为缺少数据分片,复制无法水平扩展
- 租约提供了一种用于减少中止请求数量的优化机制。
从基本介绍以及使用场景来看,etcd 的定位在于存储数据量小、更新频率低的数据,用于一致性要求高于可用性、无需水平扩展的场景。
性能
硬件推荐
以 超大型集群 为例,一个超大型集群服务的客户端超过 1500 个,每秒请求超过 10000 个,存储数据超过 1 GB。
| 云厂商 | 机型 | CPU | 内存 (GB) | 最大并发 IOPS | 磁盘带宽 (MB/s) |
|---|---|---|---|---|---|
| AWS | m4.4xlarge | 16 | 64 | 16,000 | 250 |
| GCE | n1-standard-16 + 500GB PD SSD | 16 | 60 | 15,000 | 250 |
性能指标
压测的硬件配置:
- Google Cloud Compute Engine
- 3 machines of 8 vCPUs + 16GB Memory + 50GB SSD
- 1 machine(client) of 16 vCPUs + 30GB Memory + 50GB SSD
- Ubuntu 17.04
- etcd 3.2.0, go 1.8.3
写性能
| Key 数量 | Key 大小 (byte) | Value 大小 (byte) | 连接数 | Client 数 | 目标 etcd server | 平均写 QPS | 平均请求延迟 | 平均服务 RSS |
|---|---|---|---|---|---|---|---|---|
| 10,000 | 8 | 256 | 1 | 1 | leader only | 583 | 1.6ms | 48 MB |
| 100,000 | 8 | 256 | 100 | 1000 | leader only | 44,341 | 22ms | 124MB |
| 100,000 | 8 | 256 | 100 | 1000 | all members | 50,104 | 20ms | 126MB |
读性能
| 请求数 | Key 大小 (byte) | Value 大小 (byte) | 连接数 | Client 数 | 一致性 | 平均读 QPS | 平均请求延迟 |
|---|---|---|---|---|---|---|---|
| 10,000 | 8 | 256 | 1 | 1 | Linearizable | 1,353 | 0.7ms |
| 10,000 | 8 | 256 | 1 | 1 | Serializable | 2,909 | 0.3ms |
| 100,000 | 8 | 256 | 100 | 1000 | Linearizable | 141,578 | 5.5ms |
| 100,000 | 8 | 256 | 100 | 1000 | Serializable | 185,758 | 2.2ms |
总结
一般 etcd 的集群为 3 或 5 个节点,Key 数量为 10w~ 规模下,预估集群性能如下:
- 写请求只有 Leader 才能处理,所以写性能不随节点数增加而增加,只取决于单机配置,处理量级大概为 1w~ QPS,平均延迟在 10ms~50ms。
- 串行读取所有节点均可处理,无需共识,处理量级大概为 10w~ QPS,平均延迟在 5ms 以内。
- 线性读取所有节点均可处理,但需要请求 Leader 获取 ReadIndex,性能会稍差,节点数对其提升有限,且容易受写请求影响,处理量级大概为 10w QPS,平均延迟在 10ms 以内。
适用场景
综合目标系统和 etcd 本身的细节来看:
- 首先,不建议将 etcd 用于目标系统的数据面。例如,配置中心产品,不适合使用 etcd 作为存储;
- 其次,谨慎将 etcd 用于对数据分片和水平扩展有要求的控制面系统。例如:跨可用区的服务发现,可以对服务类型进行区分,尽量减少多个可用区之间需要复制同步的服务数据量。
- 最后,etcd 租约、变更通知等功能的复杂度偏高。技术可控要求较高的系统,应谨慎使用相关功能。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/01-27-2023/etcd-implement-and-tech-selection.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!