
背景
毋庸置疑,数据只要有多个副本(replica/copy),就一定会存在一致性的问题。数据多副本一般有以下作用:
- 容错手段:当某一个副本出现故障时,可以从其他副本读取数据,确保容错并避免单点问题。
- 改善性能:在多个位置具有相同的数据可以降低数据访问延迟
- 将数据副本存放在更靠近用户的位置,典型的例子:CDN
- 将数据放在高性能的存储介质中,典型的例子:缓存
- 分担负荷:由于数据存在多个副本,每个副本都可以承担一部分查询请求。
通常,对副本的访问与对原始数据的访问应当是一致的,副本本身对外部用户应该是透明的,这就是通常理解的一致性。人人都在谈一致性,但是大家说的一致性却不一定是同一个东西。
一致性视角
从使用的角度,数据从存储系统分离取出来之后,会经过业务系统的加工,最终展现给普通用户。
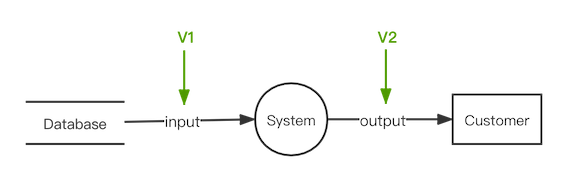
因此,存在两个视角可以来看数据一致性的问题,分别是:
- V1: 服务端视角
- V2: 用户视角
用户端一致性
首先定义如下场景:
- 存储系统:存储系统存储了用户的数据。
- 用户A:往存储系统写入数据,并读取自己与其他人的数据。
- 用户B、用户C:读取自己与其他人的数据。
从用户的角度来看,一致性包含如下三种情况:
- 强一致性:假如A先写入了一个值到存储系统,存储系统保证后续A,B,C的读取操作都将返回最新值。当然,如果写入操作“超时”,那么成功或者失败都是可能的,A不应该做任何假设。
- 弱一致性:假如A先写入了一个值到存储系统,存储系统不能保证后续A,B,C的读取操作是否能够读取到最新值。
- 最终一致性:最终一致性是弱一致性的一种特例。假如A首先写入一个值到存储系统,存储系统保证如果后续没有写操作更新同样的值,A,B,C的读取操作“最终”都会读取到A写入的最新值。“最终”一致性有一个“不一致窗口”的概念,它特指从A写入值,到后续A,B,C读取到最新值的这段时间。“不一致性窗口”的大小依赖于以下的几个因素:交互延迟,系统的负载,以及复制协议要求同步的副本数。
最终一致性描述比较粗略,其他常见的变体如下:
- 读写(Read-your-writes)一致性:如果客户端A写入了最新的值,那么A的后续操作都会读取到最新值。但是其他用户(比如B或者C)可能要过一会才能看到。
- 会话(Session)一致性:要求用户和存储系统交互的整个会话期间保证读写一致性。如果原有会话因为某种原因失效而创建了新的会话,原有会话和新会话之间的操作不保证读写一致性。
- 单调读(Monotonic read)一致性:如果客户端A已经读取了对象的某个值,那么后续操作将不会读取到更早的值。
- 单调写(Monotonic write)一致性:客户端A的写操作按顺序完成,这就意味着,对于同一个客户端的操作,存储系统的多个副本需要按照与客户端相同的顺序完成。
从用户角度看,一般要求业务系统能够支持读写一致性,会话一致性,单调读,单调写等特性,以放松一致性来提供高可用性。
服务端一致性
在开始之前确定一些定义:
N = 存储数据副本的节点数
W = 更新完成之前需要确认收到更新的副本数
R = 通过读取操作访问数据对象时获取的副本数
如果 W + R > N,则写集和读集始终重叠,并且可以保证强一致性。在实现同步复制的主备份 MySQL 方案中,N = 2,W = 2 和 R = 1。无论客户端从哪个副本中读取内容,都将始终获得一致的结果。在启用从备份读取的异步复制中,N = 2,W = 1 和 R = 1。在这种情况下,R + W = N,则不能保证一致性。
在需要提供高性能和高可用性的分布式存储系统中,副本的数量通常大于两个。仅专注于容错的系统通常使用N = 3(W = 2和R = 2配置)。微信早期的 QuorumKV,就是使用的该配置
当W + R <= N,会出现弱/最终一致性,这意味着读写集可能不会重叠。是否可以实现读写、会话和单调一致性通常取决于client与执行分布式协议的服务器的“粘性”。如果每次都是同一台服务器,那么就比较容易保证读写和单调读。同时也使得负载平衡管理和容错稍微有点困难,但这是一个简单的解决方案。
从业务系统的角度看,存储系统可以支持强一致性,也可以为了性能考虑只支持最终一致性。无法提供一致性的系统,使用比较麻烦。
复制机制
从存储系统的可用性来看,组合“存储结构”和“复制机制”有以下三种模式:
- 单主,同步/异步复制
- 自动选主,同步复制
- 多主可用,同步复制
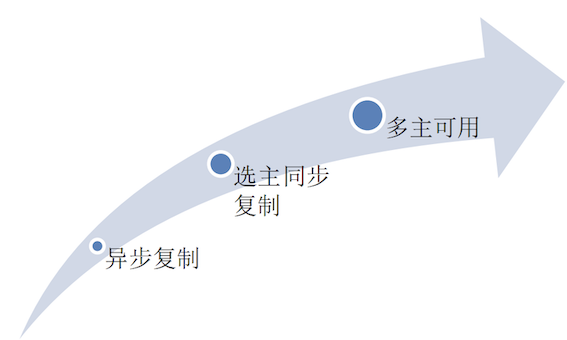
三种模式从实现难度来看,从低到高。“内存数据库 + 磁盘数据库” 类型的存储架构,如果将两者看作整体,很容易理解其“单主”的形态:
- 读请求大部分命中内存数据库,少数落到磁盘数据库
- 写请求写到磁盘数据库,然后由磁盘数据库同步到内存数据库
考虑通用架构,由于内存数据库存在数据丢失风险,数据一般会写入磁盘数据库,然后再写入或同步到内存数据库。因此在很多公司的设计中(例如Facebook和我司),均采用异步复制的方式来更新缓存。具体到MySQL,则是利用了磁盘数据库的提交日志(即Commit Log,以MySQL为例,binlog)自动异步更新缓存
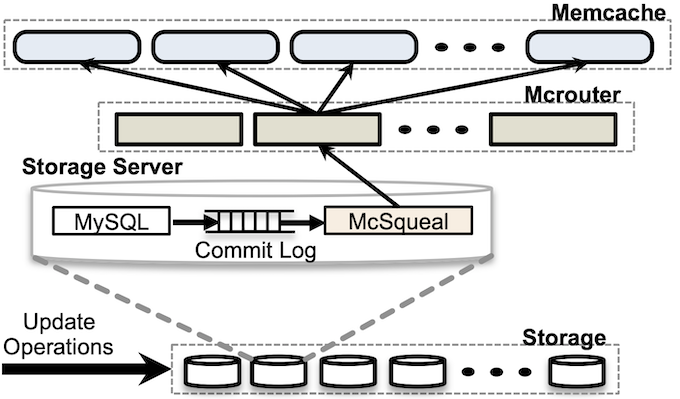
Facebook
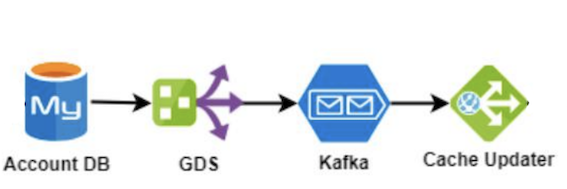
shopee
当然,异步复制只能解决最终一致性,无法解决用户角度强一致性的场景。对于这种场景可以通过 “Cache Aside Pattern” 来解决。
参考链接:
- 分布式系统的事务处理
- Eventually Consistent
- 微信后台架构与基础设施简介
- https://en.wikipedia.org/wiki/Replication_(computing)
- Scaling Memcache at Facebook
- Shopee数据事件中心的设计和实现
- 缓存更新的套路
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/03-07-2020/high-concurrency-cache-consistent.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!