
- 摘要
- 1 引言
- 2 背景
- 3 资源优化目标的演变
- 4 服务大规模系统的经验教训
- 5 故障处理的经验教训
- 6 键值接口的经验教训
- 7 相关工作
- 8 未来工作与开放问题
- 9 结论
- 致谢
- 附录 A:RocksDB 功能时间线
- 附录 B:经验教训回顾
- 附录 C:重新审视的设计选择回顾
- 参考文献
Siying Dong, Andrew Kryczka, Yanqin Jin and Michael Stumm
Facebook Inc., 1 Hacker Way, Menlo Park, CA, U.S.A
University of Toronto, Toronto, Canada
摘要
RocksDB 是一个面向大规模分布式系统、针对固态硬盘(SSD)优化的键值存储系统。本文描述了过去八年 RocksDB 开发优先级的演变过程。这种演变既是硬件趋势的结果,也是在多个组织中大规模生产环境运行 RocksDB 的丰富经验的结果。文中阐述了 RocksDB 的资源优化目标如何以及为何从写放大转向空间放大,再转向 CPU 利用率。大规模应用的实践经验表明,资源分配需要跨多个 RocksDB 实例进行统筹管理,数据格式需要保持向后和向前兼容,以支持渐进式软件部署,同时需要完善的数据库复制与备份机制支持。在故障处理方面获得的教训是:必须在系统各层尽早检测数据损坏错误。
1 引言
RocksDB [19, 54] 是 Facebook 于 2012 年基于 Google 的 LevelDB 代码库 [22] 创建的高性能持久化键值存储引擎。它针对固态硬盘(SSD)的特性进行了优化,面向大规模(分布式)应用,并被设计为可嵌入到更高级应用中的库组件。因此,每个 RocksDB 实例只管理单个服务器节点存储设备上的数据;它不处理任何跨主机的操作,如复制和负载均衡,也不执行高级操作,例如检查点——而是将这些操作的实现留给应用程序,RocksDB 只提供相应的支持以便应用高效实现这些功能。
RocksDB 及其各种组件高度可定制,允许存储引擎适应广泛的需求和工作负载;可定制项包括预写日志(WAL)处理、压缩策略和压实策略(一种移除无效数据并优化 LSM 树的过程,如 §2 所述)。RocksDB 可以调整为高写入吞吐量或高读取吞吐量、追求空间效率,或介于两者之间的目标。由于其可配置性,RocksDB 被许多应用采用,涵盖了广泛的使用场景。仅在 Facebook,就有 30 多个不同的应用使用 RocksDB,总共存储了数百 PB 的生产数据。除了作为数据库(如 MySQL [37]、Rocksandra [6]、CockroachDB [64]、MongoDB [40] 和 TiDB [27])的存储引擎外,RocksDB 还用于以下类型、特性迥异的服务(见表 1 总结):
- 流处理:RocksDB 用于 Apache Flink [12]、Kafka Stream [31]、Samza [43] 和 Facebook 的 Stylus [15] 中存储中间数据。
- 日志/队列服务:RocksDB 被 Facebook 的 LogDevice [5](同时支持 SSD 和 HDD)、Uber 的 Cherami [8] 以及 Iron.io [29] 使用。
- 索引服务:RocksDB 被 Facebook 的 Dragon [59] 和 Rockset [58] 使用。
- SSD 缓存:内存缓存服务,如 Netflix 的 EVCache [7]、奇虎的 Pika [51] 和 Redis [46] 等,使用 RocksDB 将 DRAM 淘汰的数据存储到 SSD 上。
| 用例 | 读/写模式 | 读取类型 | 特殊特性 |
|---|---|---|---|
| 数据库 | 混合型 | Get + Iterator | 事务与备份 |
| 流处理 | 写密集型 | Get 或 Iterator | 时间窗口与检查点 |
| 日志/队列 | 写密集型 | Iterator | 也支持 HDD |
| 索引服务 | 读密集型 | Iterator | 批量加载 |
| 缓存 | 写密集型 | Get | 可丢弃数据 |
表 1:RocksDB 用例及其工作负载特性
此前的一篇论文分析了若干使用 RocksDB 的数据库应用 [11]。表 2 总结了从生产工作负载获取的一些关键系统指标。
| CPU | 空间利用率 | 闪存耐久度 | 读带宽 | |
|---|---|---|---|---|
| 流处理 | 11% | 48% | 16% | 1.6% |
| 日志/队列 | 46% | 45% | 7% | 1.0% |
| 索引服务 | 47% | 61% | 5% | 10.0% |
| 缓存 | 3% | 78% | 74% | 3.5% |
表 2:各应用类别中典型用例的系统指标
拥有一个能够支持多种不同用例的存储引擎的优势在于,可以在不同应用中复用同一个存储引擎。确实,让每个应用构建自己的存储子系统是有问题的,因为这样做具有挑战性。即便是最简单的应用,也需要使用校验和防止介质损坏,保证崩溃后的数据一致性,按正确顺序发起系统调用以确保写入持久性,并以正确的方式处理文件系统返回的错误。一个成熟通用的存储引擎可以在在所有这些领域提供完善的解决方案。
当客户端应用在统一的基础设施中运行时,通用的存储引擎还能带来额外好处:监控框架、性能分析工具和调试工具都可以共享。例如,公司内不同应用的负责人可以利用相同的内部框架,将统计数据上报到同一个仪表板,使用相同的工具监控系统,并使用相同的嵌入式管理服务管理 RocksDB。这种整合不仅便于专业知识在不同团队间复用,还能将信息汇聚到统一门户,并促进开发工具来管理它们。
鉴于采用 RocksDB 的应用类型多样,其开发优先级自然会发生演变。本文描述了我们的优先级在过去八年中是如何演变的,因为我们从实际应用(包括 Facebook 内部和其他组织)中汲取了实践经验,并观察到了硬件趋势的变化,促使我们重新审视一些早期的假设。我们还描述了 RocksDB 在近期未来的开发优先级。
§2 提供了 SSD 和日志结构合并(LSM)树 [45] 的背景知识。从一开始,RocksDB 就选择 LSM 树作为其主要数据结构,以解决闪存读写性能不对称和耐久度有限的问题。我们认为 LSM 树非常适合 RocksDB,并且即使面对未来硬件趋势(见 §3),也依然适用。LSM 树数据结构是 RocksDB 能够适应具有不同需求的各类应用的原因之一。
§3 描述了主要优化目标如何从最小化写放大转向最小化空间放大,以及从优化性能转变为优化效率。
§4 总结了在服务大规模分布式系统时的经验教训。例如:(i)由于单个服务器可能托管多个实例,因此必须跨多个 RocksDB 实例管理资源分配;(ii)由于 RocksDB 软件更新是增量部署/回滚的,因此数据格式必须保持向后和向前兼容;(iii)数据库复制与备份的完善支持至关重要。
§5 讲述了我们在故障处理方面的经验。大规模分布式系统通常使用复制实现容错和高可用性。然而,必须正确处理单节点故障才能实现该目标。我们发现,简单地识别和传播文件系统及校验和错误是不够的。相反,每一层的故障(例如,比特翻转)都应尽早识别,并且应用应该能够尽可能以自动化方式指定处理它们的策略。
§6 提出了我们对改进键值接口的看法。虽然核心接口因其灵活性而简单且强大,但它局限了一些关键用例的性能。我们描述了对独立于键和值的用户定义时间戳的支持。
§8 列出了几个 RocksDB 将受益于未来研究的领域。
2 背景
闪存的特性深刻影响了 RocksDB 的设计。读写性能的不对称和有限的耐久度,在数据结构和系统架构设计上带来了挑战和机遇。因此,RocksDB 采用了闪存友好型的数据结构,并为现代硬件进行了优化。
2.1 基于闪存 SSD 的嵌入式存储
在过去十年里,基于闪存的 SSD 在服务在线数据服务方面的普及。这种低延迟、高吞吐量的设备不仅挑战了软件充分发挥其全部能力,也改变了许多有状态服务的实现方式。SSD 可为读写操作都提供每秒数十万次输入/输出操作 (IOPS),比机械硬盘快数千倍。它还能支持数百 MB 的带宽。然而,由于编程/擦除 (P/E) 周期有限,无法持续维持高写入带宽。这些因素促使我们重新审视存储引擎的数据结构,以针对此类硬件进行优化。
在许多情况下,SSD 的高性能也将性能瓶颈从设备 I/O 转移到了网络(包括延迟和吞吐量)。使得应用更倾向于将数据存储在本地 SSD 上,而不是使用远程数据存储服务。这促使嵌入于应用的键值存储引擎的需求显著增长。
RocksDB 的创建正是为满足这些需求。我们希望打造一个灵活的键值存储系统,服务于使用本地 SSD 驱动器的各种应用,并针对 SSD 的特性进行优化。LSM 树在实现这些目标中发挥了关键作用。
2.2 RocksDB 架构
RocksDB 采用日志结构合并(LSM)树 [45] 作为其存储数据的主要数据结构。
写入。 每当数据写入 RocksDB 时,数据会被添加到名为 MemTable 的内存写缓冲区,同时写入磁盘上的预写日志(WAL)。MemTable 采用跳表实现,以保持数据有序,插入和查找的时间复杂度为 O(log n)。WAL 用于故障恢复,但不是强制性的。当 MemTable 达到配置的大小后,(i)MemTable 和 WAL 变为只读,(ii)为处理后续写入操作,系统会创建新的内存表(MemTable)和预写日志(WAL),(iii)MemTable 的内容被刷新到磁盘上的 “ 有序字符串表 “(SSTable)数据文件中,(iv)已刷新的 MemTable 及其关联的 WAL 将被丢弃。每个 SSTable 以有序方式存储数据,划分为固定大小的数据块。每个 SSTable 还有一个索引块,每个数据块对应一条索引条目,支持二分查找操作。
压实 (Compaction)。 LSM 树具有多层 SSTable,如图 1 所示。最新的 SSTable 由 MemTable 刷新创建,放在 Level-0。Level-0 以上的层级由一个称为压实 (compaction) 的过程创建。给定层级上的 SSTable 大小受配置参数限制。当 Level-L 的大小目标被超过时,会从 Level-L 中选择一些 SSTable,并与 Level-(L+1) 中键范围重叠的 SSTable 合并。在此过程中,删除和覆盖的数据被移除,并且表针对读取性能和空间效率进行了优化。这个过程将写入的数据从 Level-0 逐渐迁移到最后一层 (last level)。压实 I/O 是高效的,因为它可以并行化,并且只涉及对整个文件进行批量读取和写入。
Level-0 层的 SSTable 存在键范围重叠,因为每个 SSTable 都对应一个完整的有序数据集(sorted run)。后面层级的 SSTable 各自仅包含一个有序数据集,因此这些层级的 SSTable 实际存储的是该层级有序数据集的分区片段。
读取。 在读取路径中,键查找会依次在每一层进行,直到找到该键或确定键在最后一层不存在。它从搜索所有 MemTable 开始,然后是所有 Level-0 SSTable,接着是更高层级的 SSTable。在每一层,都使用二分查找。布隆过滤器 (Bloom filter) 用于避免在 SSTable 文件内不必要的查找。扫描 (Scan) 操作则需要遍历所有层级的数据。
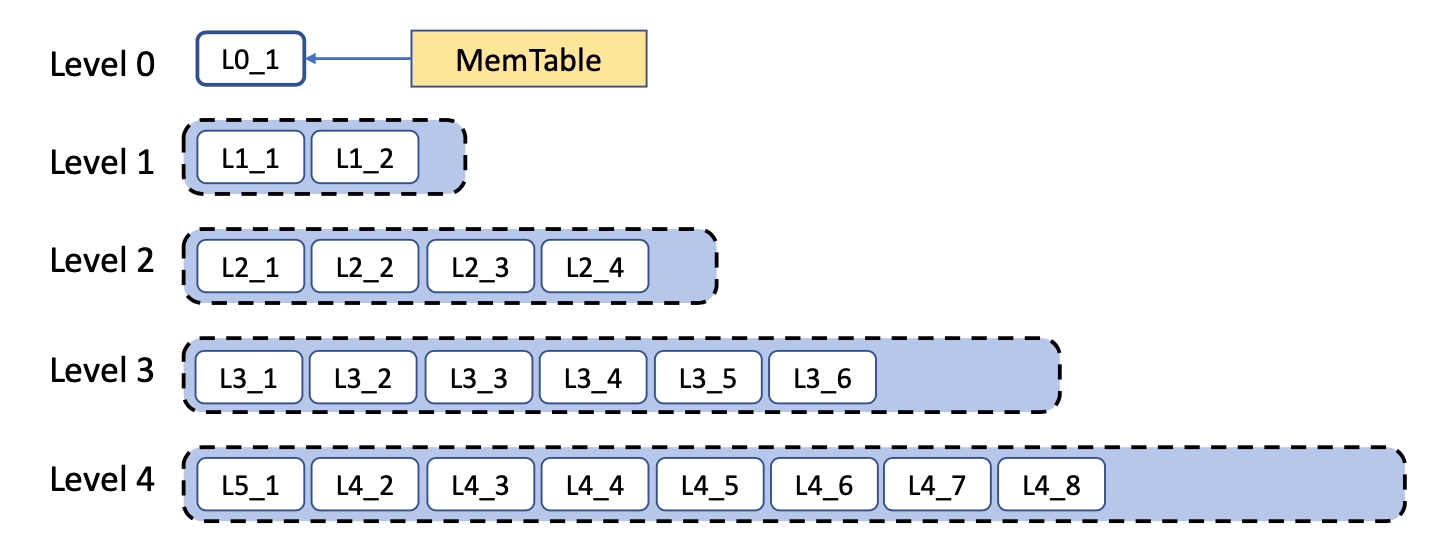
图 1:使用分层压实 (leveled compaction) 的 RocksDB LSM 树。每个白框代表一个 SSTable。
RocksDB 支持多种不同类型的压实。分层压实 (Leveled Compaction) 源自 LevelDB 并随后进行了改进 [19]。在这种压实方式下,各层被分配呈指数级增长目标的容量,如图 1 中的虚线框所示。分级压实 (Tiered Compaction)(在 RocksDB 中称为 Universal Compaction)类似于 Apache Cassandra 或 HBase 的做法。多个有序数据集会被惰性地 (lazily) 一起压实,触发时机要么是有序数据集数量过多,要么是数据库总大小与最大有数据序集大小的比值超过可配置阈值。最后,FIFO 压实 (FIFO Compaction) 则是在数据库达到大小限制后直接丢弃旧文件,仅执行轻量级压实,主要面向内存缓存类应用。
能够配置压实类型使得 RocksDB 能服务于广泛的用例。通过选择不同的压实方式,RocksDB 可被配置为读友好型、写友好型,或针对特殊缓存工作负载的极致写友好型。然而,应用所有者需要根据其特定用例权衡不同的指标 [2]。更惰性的压实算法改善了写放大和写入吞吐量,但会牺牲读取性能;而更积极的压实则会牺牲写入性能以换取更快的读取。像日志或流处理服务可以采用写密集型配置,而数据库服务则需要一个平衡的方案。表 3 通过微基准测试结果展示了这种灵活性。
| 压实方式 | 写放大 | 最大空间开销 | 平均空间开销 | 带布隆过滤器的每次 Get() I/O 次数 | 无过滤器的每次 Get() I/O 次数 | 每次迭代器 seek 的 I/O 次数 |
|---|---|---|---|---|---|---|
| Leveled | 16.07 | 9.8% | 9.5% | 0.99 | 1.7 | 1.84 |
| Tiered | 4.8 | 94.4% | 45.5% | 1.03 | 3.39 | 4.80 |
| FIFO | 2.14 | N/A | N/A | 1.16 | 528 | 967 |
表 3:RocksDB 5.9 下三种主要压实类型的写放大、开销和读取 I/O。分级压实 (Tiered) 的有序数据集数设为 12,FIFO 压实使用每个 key 20 位的布隆过滤器。使用直接 I/O,块缓存大小为完全压缩后数据库大小的 10%。写放大计算为总 SSTable 文件写入量与刷新的 MemTable 字节数之比。WAL 写入不计入。
3 资源优化目标的演变
本节描述了我们的资源优化目标如何随着时间演变:从写放大到空间放大,再到 CPU 利用率。
写放大
在最初开发 RocksDB 时,我们主要关注于节省闪存擦写周期,因此重点优化写放大,这也是当时业界的普遍观点(例如 [34])。对于许多应用,尤其是写密集型工作负载(见表 1),写放大依然是一个重要问题。
写放大体现在两个层面。SSD 本身会引入写放大:据我们的观察,放大倍数在 1.1 到 3 之间。存储和数据库软件同样会产生写放大;有时甚至高达 100(例如,仅仅更改不到 100 字节时却要写出整个 4KB/8KB/16KB 页面)。
RocksDB 的分层压实 (Leveled Compaction) 通常表现出 10 到 30 倍的写放大,这在许多情况下比 B 树方案好几倍。例如,在 MySQL 上运行 LinkBench 时,RocksDB 每个事务发出的写入量仅为基于 B 树的存储引擎 InnoDB 的 5% [37]。然而,对于写密集型应用来说,10–30 倍的写放大仍然太高。为此,我们增加了分级压实 (Tiered Compaction),它将写放大降至 4–10 倍,尽管读取性能较低;见表 3。图 2 描述了 RocksDB 在不同数据导入速率下的写放大。RocksDB 应用所有者通常在写入速率高时选择一种压实方法来减少写放大,而在写入速率低时进行更积极的压实,以实现空间效率和读取性能目标。
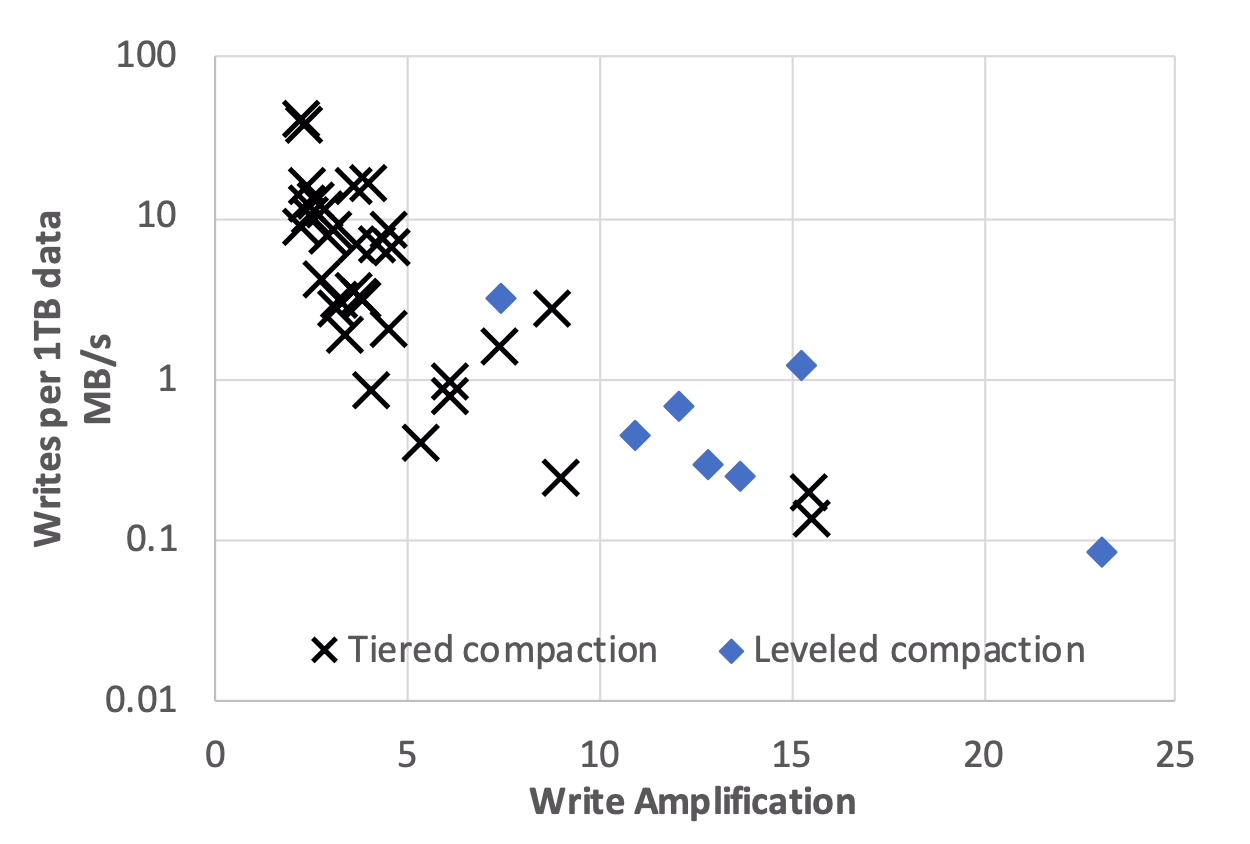
图 2:42 个随机抽样的 ZippyDB 与 MyRocks 应用写放大与写入速率的对比分析。
空间放大
经过数年开发,我们发现对于大多数应用而言,空间利用率远比写放大重要,因为闪存写入周期和写入开销都不是瓶颈。实际上,实践中使用的 IOPS 数远低于 SSD 能提供的上限(但仍然高到足以让 HDD 失去吸引力,即使忽略维护开销)。因此,我们将资源优化目标转向了磁盘空间。
幸运的是,由于其无碎片的数据布局,LSM 树在优化磁盘空间时也表现良好。然而,我们看到有机会通过减少 LSM 树中无效数据(即已删除和覆盖的数据)的数量来改进分层压实 (Leveled Compaction)。我们开发了**动态分层压实 (Dynamic Leveled Compaction)**,其中树中每个层级的大小会根据最后一层的实际大小自动调整(而不是静态设置每个层级的大小)[19]。这种方法比分层压实能获得更好、更稳定的空间效率。表 4 显示了在随机写入基准测试中测量的空间效率:动态分层压实将空间开销限制在 13%,而分层压实可能增加超过 25%。此外,分层压实下最坏情况的空间开销可能高达 90%,而动态层级调整下空间开销是稳定的。事实上,对于 Facebook 的主要数据库之一 UDB,当 InnoDB 被 RocksDB 替换时,空间占用减少了 50% [36]。
| 动态分层压实 | LevelDB 风格压实 | |||||
|---|---|---|---|---|---|---|
| 键数(百万) | 完全压实大小(GB) | 稳态 DB 大小(GB) | 空间开销(%) | 完全压实大小(GB) | 稳态 DB 大小(GB) | 空间开销(%) |
| 200 | 12.0 | 13.5 | 12.4 | 12.0 | 15.1 | 25.6 |
| 400 | 24.0 | 26.9 | 11.8 | 24.0 | 26.9 | 12.2 |
| 600 | 36.0 | 40.4 | 12.2 | 36.4 | 42.5 | 16.9 |
| 800 | 48.0 | 54.2 | 12.7 | 48.3 | 57.9 | 19.7 |
| 1,000 | 60.1 | 67.5 | 12.4 | 60.3 | 73.8 | 22.4 |
表 4: 在微基准测试中测量的 RocksDB 空间效率:数据被预先填充,每次写入都是随机选择预填充键空间中的一个键。使用 RocksDB 5.9 及所有默认选项。恒定写入速率 2MB/s。
CPU 利用率
有时会有人担忧 SSD 变得如此之快,以至于软件无法再充分利用它们的全部潜力。换言之,随着 SSD 的普及,瓶颈已从存储设备转移到 CPU,因此需要对软件进行根本性改进。根据我们的经验,我们并不认同这种担忧,也不认为未来基于 NAND 闪存的 SSD 会出现这个问题,原因有二。首先,只有极少数应用会受到 SSD IOPS 限制;正如 §4.2 所讨论的,大多数应用受到空间的限制。
其次,我们发现任何配备高端 CPU 的服务器都有足够的计算能力来饱和一块高端 SSD。在我们的环境中,RocksDB 从未遇到过无法充分利用 SSD 性能的问题。当然,配置一个导致 CPU 成为瓶颈的系统是可能的;例如,一个 CPU 配多个 SSD 的系统。但有效的系统通常是配置均衡的,这在当今技术条件下是可以实现的。写入密集型工作负载也可能导致 CPU 成为瓶颈。对于部分场景,可以通过配置 RocksDB 使用更轻量级的压缩选项来缓解。对于其他情况,该工作负载可能根本不适合 SSD,因为它会超过允许 SSD 持续使用 2-5 年的典型闪存耐久度预算。
为验证我们的观点,我们调研了生产环境中 42 个不同的 ZippyDB [65] 和 MyRocks 部署,每个服务于不同的应用。图 3 展示了结果。大多数工作负载受限于空间。有些确实是 CPU 密集型的,但主机通常不会满载,以便为业务增长和数据中心或区域级故障留有余量(或因配置不当)。这些部署大多包含数百台主机,因此平均值能反映这些用例的资源需求,考虑到工作负载可以在这些主机之间自由(重新)平衡(§4)。
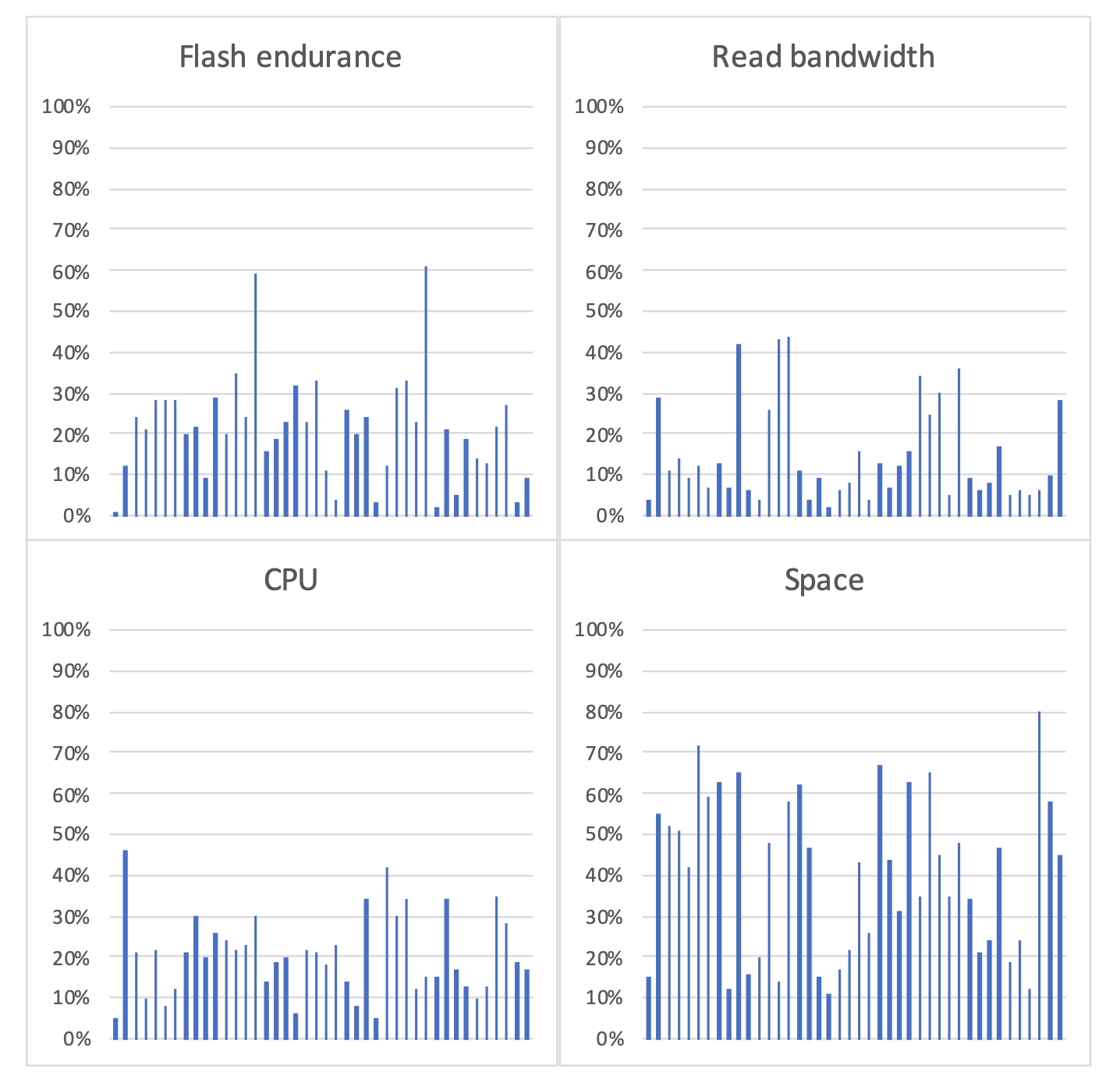
图 3:四项资源利用率。每条线代表一个不同工作负载的部署。监控周期为一个月。所有数值取该部署集群中所有主机节点的平均值。其中 CPU 利用率与读取带宽取当月峰值小时的数据,闪存耐久度与空间利用率则取整月平均值。
尽管如此,考虑到减少空间放大这个低垂的果实已经被摘取,降低 CPU 开销已成为一个重要的优化目标。降低 CPU 开销可以提升少数确实受限于 CPU 的应用的性能。更重要的是,优化 CPU 开销可以让硬件配置更具性价比——几年前,CPU 和内存的价格相对 SSD 较低,但如今 CPU 和内存价格大幅上涨,因此降低 CPU 和内存开销变得更加重要。早期降低 CPU 开销的努力包括引入前缀布隆过滤器、在索引查找前应用布隆过滤器,以及其他布隆过滤器的改进。未来仍有进一步优化空间。
适应新技术
与 SSD 相关的新架构改进很容易破坏 RocksDB 的相关性。例如,开放通道 SSD (open-channel SSDs) [50,66]、多流 SSD (multi-stream SSD) [68] 和 ZNS (Zoned Namespaces) [4] 有望改善查询延迟并节省闪存擦写周期。然而,这些新技术只会让少数 RocksDB 应用受益,因为大多数应用受限于空间,而非擦写周期或延迟。此外,让 RocksDB 直接适配这些技术会挑战其统一体验。一个值得探索的方向是将这些技术的适配下放到底层文件系统,也许 RocksDB 只需提供额外的提示 (hints)。
存储内计算(in-storage computing)或许能带来显著收益,但目前尚不清楚有多少 RocksDB 应用能真正受益。我们认为 RocksDB 适配存储内计算会很有挑战,可能需要对整个软件栈的 API 进行变更才能充分利用。我们期待未来有相关最佳实现的研究。
分离式(远程)存储看起来是更有吸引力的优化目标,也是当前的优先事项。迄今为止,我们的优化都假设闪存是本地挂载的,因为我们的系统基础设施主要是这样配置的。然而,网络速度的提升让越来越多的 I/O 可以远程完成,因此使用远程存储运行 RocksDB 的性能对于越来越多的应用变得可行。采用远程存储后,更容易同时充分利用 CPU 和 SSD 资源,因为两者可以按需独立配置(本地 SSD 很难做到)。因此,优化 RocksDB 以适配远程闪存存储已成为优先事项。我们目前正通过合并和并行化 I/O 来应对远程 I/O 延迟挑战。我们已改造 RocksDB 能处理瞬时故障、将 QoS 需求下传到底层系统,并报告性能分析信息,但仍有改进空间。
存储级内存(Storage Class Memory - SCM)是一项有前景的技术。我们正在研究如何最好地利用它。有几种可能值得考虑:1. 将 SCM 作为 DRAM 的扩展——这引发了关键问题:如何使用混合 DRAM 和 SCM 最优的实现关键数据结构(例如块缓存或 MemTable)以及在尝试利用所提供的持久性时会引入什么开销;2. 将 SCM 作为数据库的主存储,但我们注意到 RocksDB 的瓶颈往往是空间或 CPU,而非 I/O;3. 将 SCM 用于 WAL,但需考量:仅作为数据写入 SSD 前的暂存区这一用途,是否值得承担 SCM 的高成本。
重新审视主要数据结构
我们不断重新审视 LSM 树是否依然合适的问题,但始终得出肯定结论。SSD 的价格还未降到足以改变大多数用例的空间和闪存耐久度瓶颈的程度,而用 CPU 或 DRAM 换 SSD 使用量的替代方案只适合少数应用。虽然主要结论未变,但我们经常听到用户希望写放大能比 RocksDB 现有水平更低。值得注意的是,当对象较大时,通过分离 key 和 value(如 WiscKey [35] 和 ForrestDB [1])可以降低写放大,因此我们正在将其添加到 RocksDB 中(称为 BlobDB)。
4 服务大规模系统的经验教训
RocksDB 是构建各种需求各异的大规模分布式系统的基础模块。随着时间的推移,我们发现在资源管理、WAL 处理、批量文件删除、数据格式兼容性和配置管理方面需要改进。
资源管理
大规模分布式数据服务通常将数据分区成分片 (shard),并分布到多台服务器节点上进行存储。分片的大小是有限的,因为分片是负载均衡和复制的单位,,并且为了这个目的,分片在节点之间是原子性地复制的。因此,每台服务器通常会运行数十甚至上百个分片。在我们的场景下,每个分片由一个独立的 RocksDB 实例服务,这意味着一台存储主机上会运行多个 RocksDB 实例。这些实例可以运行在单一地址空间中,也可以分别运行在各自的地址空间中。
一台主机运行多个 RocksDB 实例对资源管理提出了要求。由于实例共享主机资源,必须在全局(主机级)和局部(实例级)两层进行资源管理,以确保公平高效地利用资源。单进程模式下,全局资源限制很重要,包括(1)写缓冲区和块缓存的内存、(2)压实 I/O 带宽、(3)压实线程数、(4)总磁盘使用量和(5)文件删除速率(见下文),这些限制还可能需要按 I/O 设备分别设定。局部资源限制同样重要,例如确保单个实例不能占用任何资源的过多份额。RocksDB 允许应用为每类资源创建一个或多个资源控制器(C++ 对象,传递给不同的 DB 对象),也可以按实例分别设置。最后,支持实例间的优先级调度也很重要,确保关键实例优先获得资源。
另一个经验教训是:在单进程运行多个实例时,随意创建非池化线程 (unpooled threads) 可能存在问题,尤其是线程生命周期较长时。线程过多会增加 CPU 争用、上下文切换开销,使调试极其困难,并可能引发 I/O 尖峰。如果 RocksDB 实例需要用线程执行可能会休眠或等待条件的任务,最好用线程池,这样可以方便地限制线程数量和资源消耗。
当 RocksDB 实例运行在不同进程时,全局(主机级)资源管理更具挑战性,因为每个分片只能感知局部信息。有两种策略可用。第一,每个实例都配置为保守地使用资源,而不是贪婪地占用。例如,压实时每个实例可以比 “ 正常 “ 情况下发起更少的压缩,只有压实落后时才增加。缺点是全局资源可能无法被充分利用,导致整体资源利用率不高。第二种更具操作难度的策略是让各实例间共享资源使用信息,并据此自适应调整,以期实现全局最优。RocksDB 的主机级资源管理仍有改进空间。
WAL 处理
传统数据库通常在每次写操作后强制写入预写日志(WAL),以确保持久性。而大规模分布式存储系统通常为了性能和可用性使用多副本实现,并提供不同的一致性保证。例如,如果同一数据在多个副本中存在,一旦某个副本损坏或不可访问,存储系统会用其他未受影响主机上的有效副本重建失效副本。对于这类系统,RocksDB 的 WAL 写入就没那么关键了。此外,分布式系统往往有自己的复制日志(如 Paxos 日志),此时 RocksDB 的 WAL 完全可以不用。
我们的经验是,提供可调的 WAL 同步行为的选项以满足不同应用的需求是很有用的。具体来说,我们引入了多种 WAL 操作模式:(i)同步 WAL 写入,(ii)缓冲 WAL 写入,以及(iii)完全不写 WAL。对于缓冲 WAL 处理,WAL 在后台以低优先级定期写入磁盘,以免影响 RocksDB 的业务延迟。
限速文件删除
RocksDB 通常通过文件系统与底层存储设备交互。这些文件系统是感知闪存 SSD 的,例如 XFS 的实时丢弃功能会在文件删除时向 SSD 发出 TRIM 命令 [28]。TRIM 命令被普遍认为有助于提升性能和闪存寿命 [21],我们的生产经验也验证了这一点。但 TRIM 也可能带来性能问题。TRIM 比我们最初想象的更具破坏性:除了更新地址映射(通常在 SSD 内部内存中),SSD 固件还需将这些更改写入 FTL(译者注:Flash Translation Layer) 的日志,这反过来可能触发 SSD 内部的垃圾回收,导致大量数据移动,随之对前台 I/O 延迟产生负面影响。为避免 TRIM 活动高峰及相关的 I/O 延迟增加,我们引入了文件删除限速机制,防止在压实后同时删除多个文件。
数据格式兼容性
大规模分布式应用通常在多台主机上运行服务,并要求零停机。因此,软件升级是在各主机上增量式滚动部署的;如果出现问题,更新会被回滚。随着持续部署 [56] 的普及,软件升级变得频繁;RocksDB 每月发布一个新版本。为此,磁盘上的数据必须在不同软件版本间保持前后兼容非常重要。新升级(或回滚)的 RocksDB 实例必须能理解前一版本实例写入的数据。此外,RocksDB 数据文件可能需要为了构建副本或负载平衡在分布式实例之间复制,而这些实例可能运行着不同的版本。缺乏前向兼容性保证曾导致一些 RocksDB 部署的操作困难,这促使我们添加了该保证。
RocksDB 竭尽全力确保数据保持前后兼容(新特性除外)。这在技术和流程上都具有挑战性,但我们发现这些努力是值得的。为实现向后兼容,RocksDB 必须能理解之前写入磁盘的所有格式,这增加了软件和维护复杂度。为实现前向兼容,需要理解未来的数据格式,我们旨在至少保持一年的前向兼容性。这可以通过使用通用技术部分实现,例如 Protocol Buffer [63] 或 Thrift [62] 所采用的技术。对于配置文件条目,RocksDB 需要能识别新字段,并尽力猜测如何应用或何时丢弃。我们持续使用不同版本的数据测试不同版本的 RocksDB。
管理配置
RocksDB 高度可配置,便于应用根据其工作负载进行优化。然而,我们发现配置管理是个挑战。最初,RocksDB 继承了 LevelDB 的配置参数方法,其中参数选项直接嵌入在代码中。这带来了两个问题。首先,参数选项通常与存储在磁盘上的数据相关联,导致当使用一个选项创建的数据文件无法被新配置了另一个选项的 RocksDB 实例打开时,可能产生兼容性问题。其次,代码未明确指定的配置选项会自动设置为 RocksDB 的默认值。当 RocksDB 软件更新包含对默认配置参数的更改时(例如增加内存使用量或压实并行度),应用程序有时会遇到意外的后果。
为了解决这些问题,RocksDB 首先引入了 RocksDB 实例可以使用包含配置选项的字符串参数打开数据库的能力。后来 RocksDB 引入了可选地随数据库一起存储 option 文件的支持。我们还引入了两种工具:(i)验证工具,用于验证打开数据库的选项是否与目标数据库兼容;(ii)迁移工具,用于重写数据库以使其与所需选项兼容(尽管此工具功能有限)。
RocksDB 配置管理中一个更严重的问题是配置选项数量庞大。在 RocksDB 的早期,我们做出了支持高度可定制的设计选择:我们引入了大量新参数,并支持可插拔组件,所有这些都是为了让应用程序实现其性能潜力。事实证明,这对于早期获得初始吸引力是一个成功的策略。然而,现在一个普遍的抱怨是选项太多,理解它们的影响太困难;即,指定一个“最优”配置变得非常困难。
比拥有许多需要调整的配置参数更令人望而生畏的是,最优配置不仅取决于嵌入了 RocksDB 的系统,还取决于其上应用程序产生的工作负载。例如,ZippyDB [65] ,一个内部开发的大规模分布式键值存储,其节点使用 RocksDB。ZippyDB 服务于众多不同的应用,有时单独部署,有时多租户部署。尽管在可能的情况下付出了巨大努力在所有 ZippyDB 用例中使用统一的配置,但不同用例的工作负载差异如此之大,在性能重要时,统一的配置在实践中是不可行的。表 5 显示,在我们抽样的 39 个 ZippyDB 部署中,使用了超过 25 种不同的配置。
| 配置领域: | 压实 | I/O | 压缩算法 | SSTable 文件 | 插件功能 |
|---|---|---|---|---|
| 配置数量: | 14 | 4 | 2 | 7 |
表 5:39 个 ZippyDB 部署中使用的不同配置数量
对于嵌入了 RocksDB 并交付给第三方的系统来说,调整配置参数也特别具有挑战性。考虑第三方在其某个应用中使用像 MySQL 或 ZippyDB 这样的数据库。第三方通常对 RocksDB 及其最佳调整方式知之甚少。而数据库所有者对调整其客户系统的意愿不高。
这些现实世界的经验教训引发了我们在配置支持策略上的改变。我们投入了大量精力来改进开箱即用性能并简化配置。当前重点是提供 _自动适应性_,同时继续支持丰富的显式配置,因为 RocksDB 仍服务于专业化应用。我们注意到,在保留显式可配置性的同时追求适应性会带来显著的代码维护开销,但我们相信拥有统一存储引擎的好处超过了代码的复杂性。
复制与备份支持
RocksDB 是一个单节点库。使用 RocksDB 的应用程序负责在需要时实现复制和备份。每个应用程序以自己的方式实现这些功能(有正当理由),因此 RocksDB 提供适当的支持这些功能至关重要。
引导一个新副本可以通过两种方式从现有副本复制所有数据来完成。第一种方式,可以从源副本读取所有键,然后写入目标副本(_逻辑复制_)。在源端,RocksDB 通过提供最小化对并发在线查询影响的能力来支持数据扫描操作;例如,通过提供不缓存这些操作结果的选项,从而防止缓存抖动 (cache trashing)。在目标端,支持批量加载 (bulk loading),并针对此场景进行了优化。
第二种方式,可以通过直接复制 SSTable 和其他文件(_物理复制_)来引导新副本。RocksDB 通过识别当前时间点的已有数据库文件,并防止它们被删除或更改,来辅助物理复制。支持物理复制是 RocksDB 将数据存储在底层文件系统上的一个重要原因,因为它允许每个应用程序使用自己的工具。我们认为 RocksDB 直接使用块设备接口或与 FTL 深度集成的潜在性能提升,无法超过上述好处。
对于大多数数据库和其他应用来说,备份是一个重要特性。与复制一样,应用可以选择逻辑或物理方式备份。备份与复制的一个区别在于,应用通常需要管理多个备份。虽然大多数应用程序实现自己的备份(以满足其自身需求),但如果备份需求简单,RocksDB 提供了一个备份引擎供应用程序使用。
我们认为该领域还有两个改进空间,但都需要修改键值 API,详见 §6。第一个问题涉及在不同副本上以一致顺序应用更新,这带来了性能挑战。第二个问题与串行处理的写请求性能问题有关,且副本可能出现滞后,而应用程序可能希望这些副本能更快地赶上。不同应用程序已实现多种解决方案来处理这些问题,但它们都有局限性 [20]。该挑战在于:由于 RocksDB 目前不支持用户自定义时间戳的多版本并发控制,应用程序无法进行乱序写入操作,也无法使用序列号执行快照读取。
5 故障处理的经验教训
通过生产实践,我们在故障处理方面获得了三条主要经验。首先,需要尽早检测数据损坏,,以最小化数据不可用或丢失的风险,并精确定位错误起源。其次,完整性保护必须覆盖整个系统,防止静默损坏暴露给 RocksDB 客户端或传播到其他副本(见图 4)。第三,错误应当差异化的方式处理。
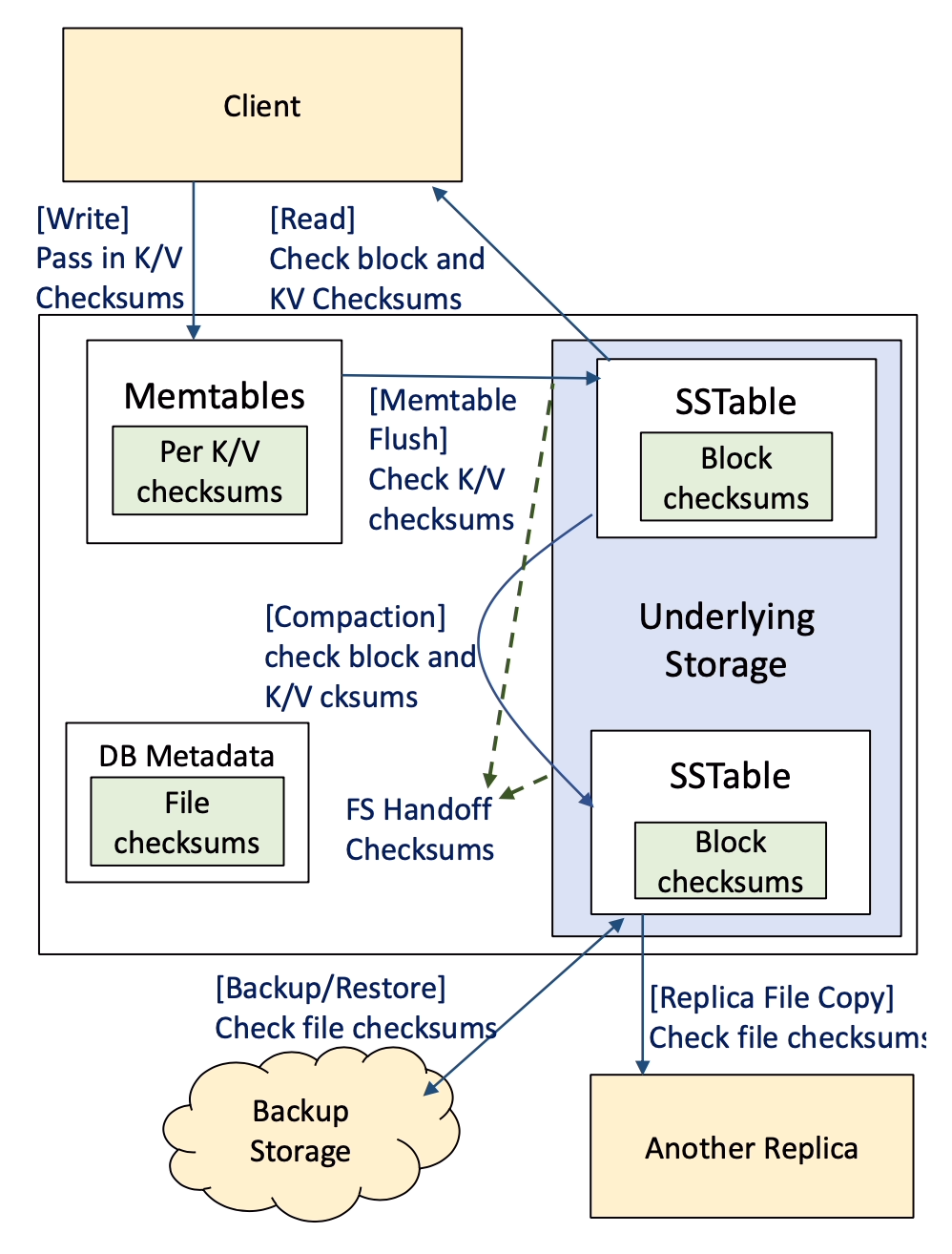
图 4:四种校验和类型
静默损坏的频率
RocksDB 用户出于性能原因通常不会使用 SSD 的数据保护功能(例如 DIF/DIX),存储介质损坏主要通过 RocksDB 的块校验和检测,这也是所有成熟数据库的常规功能,这里不再赘述。CPU/内存损坏虽极为罕见,但确实会发生,且难以准确量化。使用 RocksDB 的应用常常会运行数据一致性检查,通过比对副本来验证完整性。这能捕获错误,但这些错误可能是 RocksDB 也可能是客户端应用(例如在复制、备份或恢复数据时)引入的。
我们发现,通过比较 MyRocks 数据库表中同时具有主索引和二级索引的表,可以估计在 RocksDB 层引入损坏的频率;任何不一致都可能是在 RocksDB 层引入的,包括 CPU 或内存损坏。根据我们的测量,对于每 100PB 的数据,大约每三个月会在 RocksDB 层引入一次损坏。更糟糕的是,在 40% 的情况下,损坏已经传播到其他副本。
数据损坏在数据传输过程中也会发生,通常是由于软件缺陷。例如,底层存储系统在处理网络故障时的一个缺陷,导致我们在某段时间内观察到大约每传输 1PB 物理数据会出现 17 次校验和不匹配。
多层保护
需要尽早检测数据损坏,以最大限度减少停机和数据丢失。大多数 RocksDB 应用会在多台主机上复制其数据;当检测到校验和不匹配时,损坏的副本会被丢弃并用正确的副本替换。然而,这只有在正确的副本仍然存在时才是一个可行的选项。
目前,RocksDB 在多个层级对文件数据进行校验和,以识别其下方各层的损坏。这些以及计划中的应用层校验和如图 4 所示。多层校验和很重要,主要是因为它有助于及早检测损坏,并保护免受不同类型的威胁。从 LevelDB 继承的块校验和 (Block checksums) 防止文件系统或以下层损坏的数据暴露给客户端。2020 年添加的文件校验和 (File checksums) 防止由底层存储系统引起的损坏传播到其他副本,并防止在网络上传输 SSTable 文件时引起的损坏。WAL 文件的 handoff 校验和则能在写入时高效地早期检测损坏。
块完整性。 每个 SSTable 块或 WAL 片段都有一个附加的校验和,在数据创建时生成。与仅在文件移动时验证的文件校验和不同,由于其范围较小,此校验和在每次读取数据时都会被验证。这样做可以防止存储层损坏的数据暴露给 RocksDB 客户端。
文件完整性。 文件内容在传输操作期间特别容易损坏;例如,备份或分发 SSTable 文件时。为了解决这个问题,SSTable 受到其自身校验和的保护,该校验和在表创建时生成。SSTable 的校验和记录在其元数据的 SSTable 文件条目中,并在文件被传输到任何地方时与 SSTable 文件一起验证。然而,我们注意到其他文件,如 WAL 文件,仍未受到这种方式保护。
交接完整性。 一种用于及早检测写入损坏的成熟技术是,在要写入底层文件系统的数据上生成一个交接校验和 (handoff checksum),并将其与数据一起向下传递,在较低层进行验证 [48,70]。我们希望使用这样的写入 API 来保护 WAL 写入,因为与 SSTable 不同,WAL 受益于每次追加时的增量验证。不幸的是,本地文件系统很少支持这一点——不过一些专有栈,如 Oracle ASM [49] ,确实支持。
另一方面,当在远程存储上运行时,可以更改写入 API 以接受校验和,连接到存储服务的内部 ECC (纠错码)。RocksDB 可以在现有 WAL 片段校验和上使用校验和组合技术来高效计算写入交接校验和。由于我们的存储服务执行写入时验证,我们预计将损坏检测延迟到读取时的情况(即,在写入时验证未检出问题,直到后续读取时才被发现损坏)会极其罕见。
端到端保护
上述多层保护能在许多情况下防止了客户端读到损坏数据,但并不全面。迄今为止提到的所有保护的一个缺陷是,文件 I/O 层之上的数据未受保护,如 MemTable 和块缓存 (block cache) 中的数据。在这一层损坏的数据将是无法检测的,因此最终会暴露给用户。此外,刷新 (flush) 或压实操作可能会持久化损坏的数据,使损坏永久化。
键值完整性。 为了解决这个问题,我们目前正在实施每个键值对的校验和,以检测发生在文件 I/O 层之上的损坏。这个校验和将随键/值一起传输到它被复制的任何地方,尽管在已有替代完整性保护的文件数据中我们会省略它。
分级错误处理
RocksDB 遇到的大多数故障是底层存储系统返回的错误。这些错误可能源于多种问题,从严重问题(如只读文件系统)到瞬时问题(如磁盘已满或访问远程存储时的网络错误)。早期,RocksDB 对这类问题的反应,要么是简单地向客户端返回错误消息,要么是永久停止所有写入操作。
如今,我们的目标是仅在错误不可本地恢复时才中断 RocksDB 操作;例如,瞬时网络错误不应要求用户干预来重启 RocksDB 实例。为了实现这一点,我们改进了 RocksDB,使其在遇到被归类为瞬时的错误后能周期性重试恢复操作。因此,对于大部分发生的故障,用户无需手动干预 RocksDB,我们获得了运营上的收益。
6 键值接口的经验教训
核心的键值(KV)接口出乎意料地通用。几乎所有存储工作负载都可以通过具有 KV API 的数据存储来服务;我们很少见到有应用无法用该接口实现所需功能。这或许正是 KV 存储如此流行的原因。KV 接口是通用的。键和值都是可变长度的字节数组。应用具有很大的灵活性可以决定每个键和值中包含哪些信息,并可自由选择丰富的编码方案。因此,解析和解释键值的责任完全在应用端。KV 接口的另一个好处是可移植性。从一个键值系统迁移到另一个相对容易。不过,虽然许多用例通过这个简单接口能获得最佳性能,但我们注意到它可能限制某些应用的性能。
例如,在 RocksDB 之外实现并发控制是可行的,但很难高效,尤其是需要支持两阶段提交、在提交事务前需要部分数据持久化的场景。为此我们添加了事务支持,MyRocks (MySQL+RocksDB) 使用了它。我们继续添加特性;例如,间隙/下一键锁 和大事务支持。
在其他情况下,局限则源于键值接口本身。因此,我们已开始研究对基本键值接口的可能扩展。其中一个扩展是对用户定义时间戳的支持。
版本与时间戳
在过去的几年里,我们已经逐渐认识到数据版本化的重要性。我们得出结论,版本信息应成为 RocksDB 的一等公民,以便更好地支持多版本并发控制(MVCC)和时间点 (point-in-time) 读取等特性。为此,RocksDB 需要能够高效访问不同版本的数据。
到目前为止,RocksDB 在内部使用 56 位序列号 (sequence numbers) 来标识不同版本的 KV 对。序列号由 RocksDB 生成,并在每次客户端写入时递增(因此,所有数据在逻辑上按序列号排序)。客户端应用程序无法影响序列号。然而,RocksDB 允许应用程序获取数据库的 _快照_,之后 RocksDB 保证在快照被应用程序显式释放之前,快照时刻存在的所有 KV 对都将持续存在。因此,多个具有相同键的 KV 对可能共存,通过它们的序列号来区分。
这种版本控制方法是不充分的,因为它不能满足许多应用的需求。要读取过去的状态,必须在之前的某个时间点已经创建了快照。RocksDB 不支持获取过去的快照,因为没有 API 可以指定一个时间点。此外,支持时间点读取效率低下。最后,每个 RocksDB 实例分配自己的序列号,并且快照只能在每个实例级获取。这使具有多个(可能被复制的)分片的应用程序的版本控制复杂化,每个分片都是一个 RocksDB 实例。总之,创建能够提供跨分片一致读取的数据版本基本上是不可能的。
应用程序可以通过在键内或值内编码时间戳来绕过这些局限。然而,在两种方式下它们都会带来性能下降。在键内编码会牺牲点查找 (point-lookups) 的性能,而在值内编码会牺牲同一键乱序写入的性能,并使旧版本键的读取复杂化。我们相信应用指定的时间戳能更好地解决这些局限,应用程序可以用全局可理解的时间戳标记其数据,并将其置于键或值之外。
我们已经增加了应用指定时间戳的基本支持,并使用 DB-Bench 评估了此方法。结果如表 6 所示。每个工作负载有两个步骤:第一步填充数据库,第二步测量性能。例如,在 “fill_seq + read_random” 中,按升序写入大量键来填充初始数据库,然后在第 2 步执行随机读取操作。相较于基线(应用程序将时间戳作为键的一部分编码,对 RocksDB 透明),应用指定的时间戳 API 可以实现 1.2 倍或更高的吞吐量提升。提升源于将时间戳视为独立于用户键的元数据,因为这样可以使用点查找而不是迭代器来获取键的最新值,并且布隆过滤器可以识别不包含该键的 SSTable。此外,SSTable 可以存储覆盖的时间戳范围在其属性中,用于排除只可能包含陈旧值的 SSTable。
| 工作负载 | 吞吐提升 |
|---|---|
| fill_seq + read_random | 1.2 |
| fill_seq + read_while_writing | 1.9 |
| fill_random + read_random | 1.9 |
| fill_random + read_while_writing | 2.0 |
表 6: 使用时间戳 API 的 DB_bench 微基准测试可见 ≥ 1.2 倍的吞吐量提升。
我们希望此功能将使开发人员更容易在其系统中实现单节点 MVCC、分布式事务或解决多主复制冲突的多版本控制。然而,更复杂的 API 使用起来不那么直观,可能容易被误用。此外,与不存储时间戳相比,数据库将消耗更多的磁盘空间,并且可移植到其他系统的能力会降低。
7 相关工作
我们在 RocksDB 上的工作受益于多个领域的广泛研究。
存储引擎库
许多存储引擎被构建为可嵌入应用的库。RocksDB 的 KV 接口比 BerkeleyDB [44]、SQLite [47] 和 Hekaton [18] 等更为原始。此外,RocksDB 与这些系统的不同之处在于,专注于现代服务器工作负载的性能,这些负载需要高吞吐量和低延迟,并且通常在高端 SSD 和多核 CPU 上运行。这与面向更通用目标或为更快存储介质构建的系统不同 [18,30]。
面向 SSD 的键值存储
多年来,人们付出了大量努力来优化键值存储,特别是针对 SSD。早在 2011 年,SILT [34] 就提出了一种在内存效率、CPU 和性能之间取得平衡的键值存储。ForestDB [45] 在日志之上使用 HB+ 树进行索引。TokuDB [32] 和其他数据库使用 FractalTree/Bε 树。LOCS [67]、NoFTL-KV [66] 和 FlashKV [69] 针对开放通道 SSD 优化性能。虽然 RocksDB 受益于这些成果,但我们在提高性能方面的立场和策略是不同的,并且我们继续依赖 LSM 树。一些研究比较了 RocksDB 与其他数据库的性能,例如 InnoDB [41]、TokuDB [19][37] 和 WiredTiger [10]。
LSM-tree 改进
许多系统也使用 LSM 树并改进了其性能。写放大通常是主要的优化目标;例如,WiscKey [35]、PebblesDB [52]、IAM-tree [25] 和 TRIAD [3]。这些系统在优化写放大方面比 RocksDB 走得更远,而 RocksDB 更注重不同指标之间的权衡。SlimDB [53] 针对空间效率优化了 LSM 树;RocksDB 也专注于删除无效数据。Monkey [17] 尝试在 DRAM 和 IOPs 之间取得平衡。bLSM [57]、VT-tree [60] 和 cLSM [24] 针对 LSM 树的整体性能进行优化。
大规模存储系统
存在许多分布式存储系统 [13,14,16,26,38,64]。它们通常具有跨越多个进程、主机和数据中心的复杂架构。它们与 RocksDB 这种单节点存储引擎库没有直接可比性。其他系统(例如 MongoDB、MySQL [42]、Microsoft SQL Server [38])可以使用模块化存储引擎;它们解决了与 RocksDB 面临的类似挑战,包括故障处理和时间戳支持。
故障处理。 校验和经常用于检测数据损坏 [9,23,42]。我们关于需要端到端和交接校验和的论点,与经典的端到端论点 [55] 一致,并且与其他系统使用的策略相似:[61]、ZFS [71]、Linux [48] 和 [70]。我们关于早期检测损坏的论点与 [33] 类似,该文认为特定领域的检查是不够的。
时间戳支持。 几个存储系统提供时间戳支持:HBase [26]、WiredTiger [39] 和 BigTable [14];Cassandra [13] 将时间戳作为普通列支持。在这些系统中,时间戳是自 UNIX 纪元以来的毫秒数。Hekaton [18] 使用单调递增计数器来分配时间戳,这类似于 RocksDB 序列号。RocksDB 正在进行的用户时间戳工作可以与上述成果互补。我们希望带有用户定义时间戳扩展的键值 API,可以使上层系统更容易支持数据版本化相关的功能,同时在性能和效率方面保持低开销。
8 未来工作与开放问题
除了完成上述改进,包括优化分离式存储、键值分离、多层校验和和应用指定的时间戳外,我们计划统一分层压实 (leveled) 和分级压实 (tiered),并提升自适应性。然而,仍有若干开放问题值得进一步研究。
- 我们如何使用 SSD/HDD 混合存储来提高效率?
- 当存在大量连续的删除标记时,如何减轻对读取器的性能影响?
- 如何改进写入节流算法?
- 能否开发一种有效的方法来比较两个副本以确保它们包含相同的数据?
- 如何最好地利用 SCM?是否还应该使用 LSM 树?如何组织存储层次结构?
- 能否有一个通用的完整性 API 来处理 RocksDB 和文件系统层之间的数据交接?
9 结论
RocksDB 已从一个服务于小众应用的键值存储发展到目前被众多工业级大规模分布式应用广泛采用的系统。LSM 树作为主要数据结构很好地服务了 RocksDB,因为它表现出良好的写放大和空间放大。然而,我们对性能的看法随着时间的推移而演变。虽然写放大和空间放大仍然是主要关注点,但更多的注意力已转向 CPU 和 DRAM 效率,以及远程存储。
运行大规模应用的经验教训告诉我们:需要在不同的 RocksDB 实例之间管理资源分配;数据格式需要保持后向和前向兼容以支持增量软件部署;对数据库复制和备份的适当支持是必需的;配置管理需要简单且最好是自动化的。故障处理的经验教训告诉我们:数据损坏错误需要尽早、在系统的每一层检测。键值接口因其简单性而广受欢迎,但在性能上存在一些局限。对接口进行些许修订,或可实现更优的平衡点。
致谢
我们将 RocksDB 的成功归功于 Facebook 所有现任和前任团队成员、所有开源社区贡献者以及 RocksDB 用户。特别感谢 该项目多年的导师 Mark Callaghan,以及 RocksDB 的核心创始成员 Dhruba Borthakur。同时感谢 Jason Flinn 和 Mahesh Balakrishnan 对本文提出的宝贵意见。最后,感谢我们的指导者 Ethan Miller 和匿名审稿人提供的宝贵反馈。
附录 A:RocksDB 功能时间线
| 年份 | 性能 | 可配置性 | 功能 |
|---|---|---|---|
| 2012 | • 多线程压实 | • 压实过滤器 • 锁定 SSTable 防止删除 |
|
| 2013 | • 分层压实 • 前缀布隆过滤器 • MemTable 布隆过滤器 • MemTable 刷新的独立线程池 |
• 可插拔 MemTable • 可插拔文件格式 |
• 合并算子 (Merge Operator) |
| 2014 | • FIFO 压实 • 压实速率限制 • 缓存友好型布隆过滤器 |
• 字符串型配置选项 • 动态配置变更 |
• 备份引擎 • 多键空间(” 列族 “)支持 • 物理检查点 |
| 2015 | • 动态分层压实 • 文件删除速率限制 • Level 0 和 Level 1 并行压实 |
• 独立配置文件 • 配置兼容性检查器 |
• SSTable 文件集成的批量加载 • 乐观/悲观事务 |
| 2016 | • 最底层不同压缩算法 • MemTable 并行插入 |
• 跨实例 MemTable 总内存上限 • 压实迁移工具 |
• DeleteRange() |
| 2017 | • 最底层压实的独立线程池 • 两级文件索引 • Level 0 到 Level 0 压实 |
• 块缓存与 MemTable 统一内存上限 | |
| 2018 | • 字典压缩 • 数据块哈希索引 |
• 从空间不足错误中自动恢复 • 查询追踪与重放工具 |
|
| 2019 | • 并行 I/O 的批量 MultiGet() | • 使用对象注册表配置插件函数 | • 次级实例 |
| 2020 | • 单文件多线程压缩 | • 整文件校验和 • 从可重试错误中自动恢复 • 部分支持用户自定义时间戳 |
附录 B:经验教训回顾
我们学到的一些经验教训包括:
- 存储引擎可调优以适配不同性能特征非常重要。(§1)
- 空间效率是大多数使用 SSD 应用的瓶颈。(§3,空间放大)
- CPU 开销日益重要,有助于系统更高效运行。(§3,CPU 利用率)
- 当许多 RocksDB 实例在同一主机上运行时,全局的、每主机资源管理是必要的。(§4,资源管理)
- WAL 行为可配置(同步 WAL 写入、缓冲 WAL 写入或禁用 WAL)能为应用带来性能优势。(§4,WAL 处理)
- SSD 的 TRIM 操作有利于性能,但文件删除需限速以防偶发性能问题。(§4,速率限制的文件删除)
- RocksDB 需同时提供后向和 “ 前向 “ 兼容性。(§4,数据格式兼容性)
- 自动配置自适应有助于简化配置管理。(§4,配置管理)
- 数据复制与备份需得到妥善支持。(§4,复制与备份支持)
- 越早检测数据损坏越有利,而不是等到最后才发现。(§5)
- 虽极为罕见,CPU/内存损坏确实会发生,并且有时无法通过数据复制处理。(§5)
- 完整性保护必须覆盖整个系统,防止损坏数据(如 CPU/内存位翻转)暴露给客户端或其他副本,仅在数据静止或通过网络传输时检测损坏是不够的。(§5)
- 用户常要求 RocksDB 能自动从瞬时 I/O 错误中恢复,例如空间不足或由网络问题引起的错误。(§5)
- 错误处理需根据原因和后果区别对待。(§5)
- 键/值接口是通用的,但存在一些性能局限;为键/值添加时间戳可以在性能和简单性之间提供良好的平衡。(§6)
附录 C:重新审视的设计选择回顾
一些值得注意的重新审视的设计选择包括:
- 可定制性总是对用户有益的。(§4,配置管理)
- RocksDB 可能无法感知 CPU 位翻转。(§5)
- 遇到任何 I/O 错误时直接 panic 是可以的。(§5)
参考文献
[1] Jung-Sang Ahn, Chiyoung Seo, Ravi Mayuram, Rahim Yaseen, Jin-Soo Kim, and Seungryoul Maeng. ForestDB: A fast key-value storage system for variable-length string keys. IEEE Trans. on Computers, 65(3):902–915, 2015.
[2] Manos Athanassoulis, Michael S Kester, Lukas M Maas, Radu Stoica, Stratos Idreos, Anastasia Ailamaki, and Mark Callaghan. Designing access methods: The RUM conjecture. In Proc. Intl. Conf on Extending Database Technology (EDBT), volume 2016, pages 461–466, 2016.
[3] Oana Balmau, Diego Didona, Rachid Guerraoui, Willy Zwaenepoel, Huapeng Yuan, Aashray Arora, Karan Gupta, and Pavan Konka. TRIAD: Creating synergies between memory, disk and log in log-structured key-value stores. In Proc. USENIX Annual Technical Conference (USENIX-ATC’17), pages 363–375, 2017.
[4] Matias Bjørling. Zone Append: A new way of writing to zoned storage. In Proc. Usenix Linux Storage and Filesystems Conference (VAULT’20), 2020.
[5] Facebook Engineering Blog. LogDevice: A distributed data store for logs. https://engineering.fb.com/core-data/logdevice-a-distributed-data-store-for-logs/. [Online; retrieved September 2020].
[6] Instagram Engineering Blog. Open-sourcing a 10x reduction in Apache Cassandra tail latency. https://instagram-engineering.com/open-sourcing-a-10x-reduction-in-apache-cassandra-tail-latency-d64f86b43589. [Online; retrieved September 2020].
[7] Netflix Technology Blog. Application data caching using SSDs: The Moneta project: Next generation EV-Cache for better cost optimization. https://netflixtechblog.com/application-data-caching-using-ssds-5bf25df851ef. [Online; retrieved September 2020].
[8] Uber Engineering Blog. Cherami: Uber Engineering’s durable and scalable task queue in Go. https://eng.uber.com/cherami-message-queue-system/. [Online; retrieved September 2020].
[9] Dhruba Borthakur. HDFS architecture guide. Hadoop Apache Project, 53(1-13):2, 2008.
[10] Mark Callaghan. MongoRocks and WiredTiger versus LinkBench on a small server. http://smalldatum.blogspot.com/2016/10/mongorocks-and-wiredtiger-versus.html. [Online; retrieved Jan 2021].
[11] Zhichao Cao, Siying Dong, Sagar Vemuri, and David H.C. Du. Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook. In 18th USENIX Conf. on File and Storage Technologies (FAST’20), pages 209–223, February 2020.
[12] Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. Apache Flink: Stream and batch processing in a single engine. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 36(4), 2015.
[13] Apache Cassandra. https://cassandra.apache.org/. [Online; retrieved September 2020].
[14] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C Hsieh, Deborah A Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E Gruber. Bigtable: A distributed storage system for structured data. ACM Trans. on Computer Systems (TOCS), 26(2):1–26, 2008.
[15] Guoqiang Jerry Chen, Janet L Wiener, Shridhar Iyer, Anshul Jaiswal, Ran Lei, Nikhil Simha, Wei Wang, Kevin Wilfong, Tim Williamson, and Serhat Yilmaz. Realtime data processing at Facebook. In Proc. Intl. Conf. on Management of Data, pages 1087–1098, 2016.
[16] James C Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, Jeffrey John Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, et al. Spanner: Google’s globally distributed database. ACM Trans. on Computer Systems (TOCS), 31(3):1–22, 2013.
[17] Niv Dayan, Manos Athanassoulis, and Stratos Idreos. Monkey: Optimal navigable key-value store. In Proc. Intl. Conf. on Management of Data (SIGMOD’17), pages 79–94, 2017.
[18] Cristian Diaconu, Craig Freedman, Erik Ismert, Per-Ake Larson, Pravin Mittal, Ryan Stonecipher, Nitin Verma, and Mike Zwilling. Hekaton: SQL server’s memory-optimized OLTP engine. In Proc. ACM SIGMOD Intl. Conf. on Management of Data (SIGMOD’13), pages 1243–1254, 2013.
[19] Siying Dong, Mark Callaghan, Leonidas Galanis, Dhruba Borthakur, Tony Savor, and Michael Stumm. Optimizing space amplification in RocksDB. In Proc. Conf. on Innovative Data Systems Research (CIDR’17), 2017.
[20] Jose Faleiro. The dangers of logical replication and a practical solution. In Proc. 18th Intl. Workshop on High Performance Transaction Systems (HPTS’19), 2019.
[21] Tasha Frankie, Gordon Hughes, and Ken Kreutz-Delgado. A mathematical model of the trim command in NAND-flash SSDs. In Proc. 50th Annual Southeast Regional Conference (ACM-SE’12), pages 59–64, 2012.
[22] S. Ghemawat and J. Dean. LevelDB. https://github.com/google/leveldb, 2011.
[23] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google File System. In Proc. 19th ACM Symp. on Operating systems principles (SOSP’13), pages 29–43, 2003.
[24] Guy Golan-Gueta, Edward Bortnikov, Eshcar Hillel, and Idit Keidar. Scaling concurrent log-structured data stores. In Proc. European Conf. on Computer Systems (EUROSYS’15), pages 1–14, 2015.
[25] Caixin Gong, Shuibing He, Yili Gong, and Yingchun Lei. On integration of appends and merges in log-structured merge trees. In Proc. 48th Intl. Conf. on Parallel Processing (ICPP’19), pages 1–10, 2019.
[26] Apache HBase. https://hbase.apache.org/. [Online; retrieved September 2020].
[27] Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang, Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, Wan Wei, Cong Liu, Jian Zhang, Jianjun Li, Xuelian Wu, Lingyu Song, Ruoxi Sun, Shuaipeng Yu, Lei Zhao, Nicholas Cameron, Liquan Pei, and Xin Tang. TiDB: A Raft-based HTAP database. Proc. VLDB Endow., 13(12):3072–3084, August 2020.
[28] Intel. Trim overview. https://www.intel.com/content/www/us/en/support/articles/000016148/memory-and-storage.html. [Online; retrieved Jan 2021].
[29] Iron.io. Confluent https://www.iron.io. [Online; retrieved September 2020].
[30] Hideaki Kimura. FOEDUS: OLTP engine for a thousand cores and NVRAM. In Proc. SIGMOD Intl. Conf. on Management of Data (SIGMOD’15), pages 691–706, 2015.
[31] Jay Kreps. Introducing Kafka Streams: Stream processing made simple. Confluent https://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple/. [Online; retrieved September 2020].
[32] B Kuszmaul. How TokuDB fractal tree indexes work. Technical report, Technical report, TokuTek, 2010.
[33] Chuck Lever. End-to-end data integrity requirements for NFS. Oracle Corp. https://datatracker.ietf.org/meeting/83/materials/slides-83-nfsv4-2. [Online; retrieved September 2020].
[34] Hyeontaek Lim, Bin Fan, David G Andersen, and Michael Kaminsky. SILT: A memory-efficient, high-performance key-value store. In Proc. 23rd ACM Symp. on Operating Systems Principles (SOSP’11), pages 1–13, 2011.
[35] Lanyue Lu, Thanumalayan Sankaranarayana Pillai, Hariharan Gopalakrishnan, Andrea C Arpaci-Dusseau, and Remzi H Arpaci-Dusseau. Wisckey: Separating keys from values in SSD-conscious storage. ACM Trans. on Storage (TOS), 13(1):1–28, 2017.
[36] Yoshinori Matsunobu. Migrating a database from InnoDB to MyRock. Facebook Engineering Blog 2017. [Online; retrieved September 2020].
[37] Yoshinori Matsunobu, Siying Dong, and Herman Lee. MyRocks: LSM-tree database storage engine serving Facebook’s Social Graph. Proc. VLDB Endowment, 13(12):3217–3230, August 2020.
[38] Microsoft. Microsoft SQL Server. https://www.microsoft.com/en-us/sql-server/. [Online; retrieved September 2020].
[39] MongoDB. WiredTiger Storage Engine. https://docs.mongodb.com/manual/core/wiredtiger/. [Online; retrieved September 2020].
[40] MongoRocks. RocksDB storage engine module for MongoDB. https://github.com/mongodb-partners/mongo-rocks. [Online; retrieved September 2020].
[41] MySQL. Introduction to InnoDB. https://dev.mysql.com/doc/refman/5.6/en/innodb-introduction.html. [Online; retrieved September 2020].
[42] MySQL. MySQL. https://www.mysql.com/. [Online; retrieved September 2020].
[43] Shadi A Noghabi, Kartik Paramasivam, Yi Pan, Navina Ramesh, Jon Bringhurst, Indranil Gupta, and Roy H Campbell. Samza: Stateful scalable stream processing at LinkedIn. Proc. of the VLDB Endowment, 10(12):1634–1645, 2017.
[44] Michael A Olson, Keith Bostic, and Margo I Seltzer. Berkeley DB. In USENIX Annual Technical Conference, FREENIX Track, pages 183–191, 1999.
[45] Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. The log-structured merge-tree (LSM-tree). Acta Informatica, 33(4):351–385, 1996.
[46] Keren Ouaknine, Oran Agra, and Zvika Guz. Optimization of RocksDB for Redis on flash. In Proc. Intl. Conf. on Compute and Data Analysis, pages 155–161, 2017.
[47] Mike Owens. The definitive guide to SQLite. Apress, 2006.
[48] Martin K Petersen. Linux data integrity extensions. In Linux Symposium, volume 4, page 5, 2008.
[49] Martin K. Petersen and Sergio Leunissen. Eliminating silent data corruption with Oracle Linux. Oracle Corp. https://oss.oracle.com/~mkp/docs/data-integrity-webcast.pdf. [Online; retrieved September 2020].
[50] Ivan Luiz Picoli, Niclas Hedam, Philippe Bonnet, and Pinar Tözün. Open-channel SSD (What is it good for). In Proc. Conf. on Innovative Data Systems Research (CIDR’20), 2020.
[51] Qihoo. Confluent https://github.com/Qihoo360/pika. [Online; retrieved September 2020].
[52] Pandian Raju, Rohan Kadekodi, Vijay Chidambaram, and Ittai Abraham. PebblesDB: Building key-value stores using fragmented log-structured merge trees. In Proc. 26th Symp. on Operating Systems Principles (SOSP’17), pages 497–514, 2017.
[53] Kai Ren, Qing Zheng, Joy Arulraj, and Garth Gibson. SlimDB: A space-efficient key-value storage engine for semi-sorted data. Proc. of the VLDB Endowment (VLDB’17), 10(13):2037–2048, 2017.
[54] RocksDB.org. A persistent key-value store for fast storage environments. https://rocksdb.org. [Online; retrieved September 2020].
[55] Jerome H Saltzer, David P Reed, and David D Clark. End-to-end arguments in system design. ACM Trans. on Computer Systems (TOCS), 2(4):277–288, 1984.
[56] Tony Savor, Mitchell Douglas, Michael Gentili, Laurie Williams, Kent Beck, and Michael Stumm. Continuous deployment at Facebook and OANDA. In 2016 IEEE/ACM 38th International Conference on Software Engineering Companion (ICSE-C), pages 21–30. IEEE, 2016.
[57] Russell Sears and Raghu Ramakrishnan. bLSM: a general purpose log-structured merge tree. In Proc. Intl. Conf. on Management of Data (SIGMOD’12), pages 217–228, 2012.
[58] Arun Sharma. How we use RocksDB at Rockset. Rockset Blog https://rockset.com/blog/how-we-use-rocksdb-at-rockset/. [Online; retrieved September 2020].
[59] Arun Sharma. LogDevice: A distributed data store for logs. Facebook Engineering Blog https://engineering.fb.com/data-infrastructure/dragon-a-distributed-graph-query-engine/. [Online; retrieved September 2020].
[60] Pradeep J Shetty, Richard P Spillane, Ravikant R Malpani, Binesh Andrews, Justin Seyster, and Erez Zadok. Building workload-independent storage with VT-trees. In Proc. 11th USENIX Conf. on File and Storage Technologies (FAST’13), pages 17–30, 2013.
[61] Gopalan Sivathanu, Charles P Wright, and Erez Zadok. Enhancing file system integrity through checksums. Technical report, Citeseer, 2004.
[62] Mark Slee, Aditya Agarwal, and Marc Kwiatkowski. Thrift: Scalable cross-language services implementation. Facebook White Paper, 5(8), 2007.
[63] Google Open Source. Protobuf. https://opensource.google/projects/protobuf. [Online; retrieved September 2020].
[64] Rebecca Taft, Irfan Sharif, Andrei Matei, Nathan VanBenschoten, Jordan Lewis, Tobias Grieger, Kai Niemi, Andy Woods, Anne Birzin, Raphael Poss, Paul Bardea, Amruta Ranade, Ben Darnell, Bram Gruneir, Justin Jaffray, Lucy Zhang, and Peter Mattis. CockroachDB: The resilient geo-distributed SQL database. In Proc. ACM SIGMOD Intl. Conf. on Management of Data (SIGMOD’20), page 1493–1509, 2020.
[65] Amy Tai, Andrew Kryczka, Shobhit O. Kanaujia, Kyle Jamieson, Michael J. Freedman, and Asaf Cidon. Who’s afraid of uncorrectable bit errors? Online recovery of flash errors with distributed redundancy. In 2019 USENIX Annual Technical Conference (USENIX ATC’19), pages 977–992, Renton, WA, July 2019.
[66] Tobias Vinçon, Sergej Hardock, Christian Riegger, Julian Oppermann, Andreas Koch, and Ilia Petrov. NoFTL-KV: Tackling write-amplification on KV-stores with native storage management. In Proc. 21st Intl. Conf. on Extending Database Technology (EDBT’18), pages 457–460, 2018.
[67] Peng Wang, Guangyu Sun, Song Jiang, Jian Ouyang, Shiding Lin, Chen Zhang, and Jason Cong. An efficient design and implementation of LSM-tree based key-value store on open-channel SSD. In Proc. 9th European Conf. on Computer Systems (EUROSYS’14), pages 1–14, 2014.
[68] Fei Yang, K Dou, S Chen, JU Kang, and S Cho. Multi-streaming RocksDB. In Proc. Non-Volatile Memories Workshop, 2015.
[69] Jiacheng Zhang, Youyou Lu, Jiwu Shu, and Xiongjun Qin. FlashKV: Accelerating KV performance with open-channel SSDs. ACM Trans on Embedded Computing Systems (TECS), 16(5s):1–19, 2017.
[70] Yupu Zhang, Daniel S Myers, Andrea C Arpaci-Dusseau, and Remzi H Arpaci-Dusseau. Zettabyte reliability with flexible end-to-end data integrity. In Proc. 29th IEEE Symp. on Mass Storage Systems and Technologies (MSST’13), pages 1–14, 2013.
[71] Yupu Zhang, Abhishek Rajimwale, Andrea C Arpaci-Dusseau, and Remzi H Arpaci-Dusseau. End-to-end data integrity for file systems: A ZFS case study. In Proc. 8th USENIX Conf. on File and Storage Technologies (FAST’10), pages 29–42, 2010.
本文为中文翻译,仅用于学习与分享,版权归原作者所有。
Slides: Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience
相关论文:RocksDB: Evolution of Development Priorities in a Key-value Store Serving Large-scale Applications
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/08-03-2025/the-rocksdb-experience.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!