
背景
MySQL数据库作为数据持久化的存储系统,在实际业务中应用广泛。在应用也经常会因为SQL遇到各种各样的瓶颈。最常用的MySQL引擎是innodb,索引类型是B-Tree索引,增删改查等操作最经常遇到的问题是“查”,查询又以索引为重点(没索引不是病,慢起来太要命)。踩过O2O优惠券、摇一摇周边两个业务的一些坑,当谈到SQL优化时,想分享下innodb下B-Tree索引的一些理解与实践。
接下来的内容,安排如下:
- 介绍索引的工作原理;
- 引用实例具体介绍索引;
- 如何使用explain排查线上问题;
- 实际碰到的问题汇总;
索引如何工作
当查询时,MySQL的查询优化器会使用统计数据预估使用各个索引的代价(COST),与不使用索引的代价(COST)比较。MySQL会选择代价最低的方式执行查询。MySQL如何使用索引,可以用下面的伪代码来说明:
min_cost = INIT_VALUE
min_cost_index = NONE
for(index in all_indexs):
if (index match WHERE_CLAUSE):
cur_cost = COST(index)
if(cur_cost < min_cost):
min_cost = cur_cost
min_cost_index = indexINIT_VALUE:不使用索引时的代价
all_indexs:查询表上所有的索引COST:基本是由“估计需要扫描的行数”(rows)来确定
WHERE_CLAUSE:查询SQL中的WHERE子句
大致的意思:MySQL会遍历该查询相关的表(table)的每一条索引,然后判断该索引能否被本次查询使用(possible_keys)。当索引可以使用时,MySQL预估使用该索引进行查询的cost,然后选择预估代价最低的方式(key)执行查询。
索引匹配(match)
怎样判断索引是否匹配(match)SQL查询?
1、索引的左前缀规则;索引中的列由左向右逐一匹配,如果中间某一列不能使用索引则后序列不在查询中不再被使用。
例如,如果有一个3列索引(str_col1,col2,col3),其中str_col1为字符串,则对(str_col1)、(str_col1,col2)和(str_col1,col2,col3)上的查询进行了索引。
如果列不构成索引最左面的前缀,MySQL不能使用索引。假定有下面显示的SELECT语句。
SELECT * FROM tbl_name WHERE str_col1=val1;
SELECT * FROM tbl_name WHERE str_col1=val1 AND col2=val2;
SELECT * FROM tbl_name WHERE col2=val2;
SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;如果 (str_col1,col2,col3)有一个索引,只有前2个查询使用索引。第3个和第4个查询确实包括索引的列,但(col2)和(col2,col3)不是 (col1,col2,col3)的最左边的前缀。
2、where语句中列的表达式为=、>、>=、<、<=、BETWEEN、ISNULL或者LIKE ’pattern’(其中’pattern’不以通配符开始)
3、每个AND组作为表达式匹配索引。
SELECT * FROM tbl_name WHERE (str_col1=val1 OR col4 =val4) AND col2=val2;因为str_col1=val1 OR col4 =val4作为一组,col4不匹配索引中的列,所以查询不匹配索引。
4、如果表达式中存在类型转换或者列上有复杂函数则与该列不匹配索引中的列。
SELECT * FROM tbl_name WHERE str_col1=1;
SELECT * FROM tbl_name WHERE SUBSTRING(str_col1,1,8) = ‘title’;第1个查询,因为1是整数、str_col1是字符串,所以不匹配索引;第2个查询str_col1有复杂函数,同样不匹配索引。
索引的COST
MySQL如何计算索引的COST?
索引的cost基本是由“估计需要扫描的行数”(rows)来确定。数据来源于information_schema,在MySQL启动的时候读入内存,运行时只使用内存值,存储引擎会动态更新这些值。
我们可以通过explain看下“估计需要扫描的行数”,可以通过optimizer_trace查询适用每一条SQL的具体的cost值。explain也是线上排查问题的利器,后面会重点介绍。
索引实例分析
索引的字段究竟是怎么从where语句中提取,并被MySQL使用呢,下面将以一个实例分析这个过程。内容全文为摘取何登成的文章《SQL中的where条件,在数据库中提取与应用浅析》,并做了部分删改。
我们创建一张测试表,一个索引,然后插入几条记录。(注意:下面的实例,使用的表的结构不是InnoDB引擎所采用的聚簇索引表。图例仅为说明,原理适用innodb)
create table t1 (a int primary key, b int, c int, d int, e varchar(20));
create index idx_t1_bcd on t1(b, c, d);
insert into t1 values (4,3,1,1,’d’);
insert into t1 values (1,1,1,1,’a’);
insert into t1 values (8,8,8,8,’h’):
insert into t1 values (2,2,2,2,’b’);
insert into t1 values (5,2,3,5,’e’);
insert into t1 values (3,3,2,2,’c’);
insert into t1 values (7,4,5,5,’g’);
insert into t1 values (6,6,4,4,’f’);t1表的存储结构如下图所示(只画出了idx_t1_bcd索引与t1表结构,没有包括t1表的主键索引):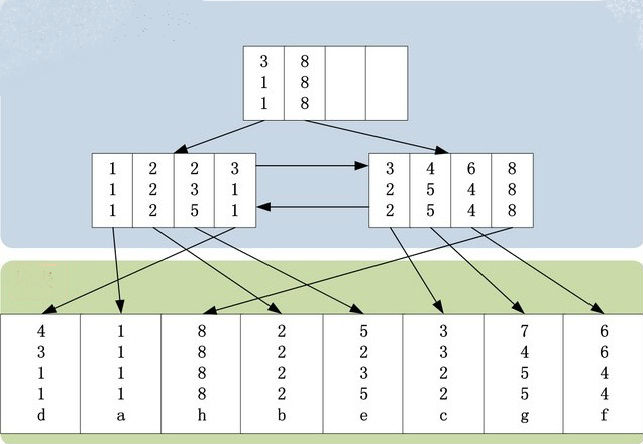
简单说明上图,idx_t1_bcd索引上有[b,c,d]三个字段,不包括[a,e]字段。idx_t1_bcd索引,首先按照b字段排序,b字段相同,则按照c字段排序,以此类推。
考虑以下SQL:
select * from t1 where b >= 2 and b < 8 and c > 1 and d != 4 and e != ‘a’;可以发现where条件使用到了[b,c,d,e]四个字段,而t1表的idx_t1_bcd索引,恰好使用了[b,c,d]这三个字段,那么走idx_t1_bcd索引进行条件过滤,应该是一个不错的选择。
所有SQL的where条件,均可归纳为3大类:Index Key (First Key & Last Key),Index Filter,Table Filter。
接下来,让我们来详细分析这3大类分别是如何定义,以及如何提取的。
l Index Key
用于确定SQL查询在索引中的连续范围(起始范围+结束范围)的查询条件,被称之为Index Key。由于一个范围,至少包含一个起始与一个终止,Index Key也被拆分为Index First Key和Index Last Key,分别用于定位索引查找的起始,以及索引查询的终止条件。
Index First Key
提取规则:从索引的第一个键值开始,检查其在where条件中是否存在,若存在并且条件是=、>=,则将对应的条件加入Index First Key之中,继续读取索引的下一个键值,使用同样的提取规则;若存在并且条件是>,则将对应的条件加入Index First Key中,同时终止Index First Key的提取;若不存在,同样终止Index First Key的提取。
针对上面的SQL,应用这个提取规则,提取出来的Index First Key为(b >= 2, c > 1)。由于c的条件为 >,提取结束,不包括d。
Index Last Key
提取规则:从索引的第一个键值开始,检查其在where条件中是否存在,若存在并且条件是=、<=,则将对应条件加入到Index Last Key中,继续提取索引的下一个键值,使用同样的提取规则;若存在并且条件是 < ,则将条件加入到Index Last Key中,同时终止提取;若不存在,同样终止Index Last Key的提取。
针对上面的SQL,应用这个提取规则,提取出来的Index Last Key为(b < 8),由于是 < 符号,因此提取b之后结束。
2 Index Filter
在完成Index Key的提取之后,我们根据where条件固定了索引的查询范围,但是此范围中的项,并不都是满足查询条件的项。在上面的SQL用例中,(3,1,1),(6,4,4)均属于范围中,但是又均不满足SQL的查询条件。
Index Filter的提取规则:同样从索引列的第一列开始,检查其在where条件中是否存在:若存在并且where条件仅为 =,则跳过第一列继续检查索引下一列,下一索引列采取与索引第一列同样的提取规则;若where条件为 >=、>、<、<= 其中的几种,则跳过索引第一列,将其余where条件中索引相关列全部加入到Index Filter之中;若索引第一列的where条件包含 =、>=、>、<、<= 之外的条件,则将此条件以及其余where条件中索引相关列全部加入到Index Filter之中;若第一列不包含查询条件,则将所有索引相关条件均加入到Index Filter之中。
针对上面的用例SQL,索引第一列只包含 >=、< 两个条件,因此第一列可跳过,将余下的c、d两列加入到Index Filter中。因此获得的Index Filter为 c > 1 and d != 4 。
3 Table Filter
Table Filter是最简单,最易懂,也是提取最为方便的。提取规则:所有不属于索引列的查询条件,均归为Table Filter之中。
同样,针对上面的用例SQL,Table Filter就为 e != ‘a’。
根据以上实例其实可以总结出一些规律,WHERE语句究竟怎样(是否)匹配索引,不用迷信出自他人之口的规则。只需要简单的按照索引自左向右的每一列,从WHERE语句提取条件,能否从索引树的根节点出发,到达索引树的叶节点,成功匹配出一个或几个范围区间,即能自己自行判断是否能使用索引。反过来,最左前缀匹配、Like不能以通配符开始、AND分组,也都是由B-Tree本身特性决定的。
索引问题排查
前面我们谈使用索引的cost的值提到过explain。下面介绍explain的值,并以一个实际遇到的问题说明如何排查问题。
Explain详解
使用一个示例SQL来解释explain:
select id from v_ibeacon_device_d where ftime >= 20151126 and ftime <= 20151126 and biz_id = 11602 limit 50;IDX_BID_FTIME<biz_id, ftime>是表r_ibeacon_biz_device_d的其中一条索引。
Biz_id,ftime均为bigint类型。
我们着重关注几个重点字段的重点值:
我们着重关注几个重点字段的重点值:
- type:索引的使用方式
eq_ref … 索引,关联匹配若干行
ref … 索引(前缀)匹配
range … 索引范围扫(BETWEEN、IN、>=、LIKE)得到数据
index … 索引全扫描
all … 表全扫描示例中使用的索引是使用全索引范围扫描,所以type为range
possible_keys:适用查询的索引列表。示例中有三条索引适用本次查询。
key: 查询实际执行使用的索引。示例使用的为IDX_BID_FTIME
key_len:查询使用索引的长度。
null 1字节
tinyint 1字节
int 4字节
bigint 8字节
double 8字节
datetime 8字节
timestamp 4字节
varchar(10)变长字段且允许NULL: 10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
char(10)固定字段且允许NULL: 10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL)以上是常用类型的长度,示例中key_len为18,即:8字节(biz_idbigint)+1字节(biz_id允许为null)+8字节(ftimebigint)+1字节(ftime允许为null)。所以本次查询是使用了索引的所有字段加速查询
- rows:查询预估扫描的行数
Explain跟进问题
摇一摇周边后台的数据统计接口偶尔会有小尖峰,涉及了一条SQL:
select d.id from v_ibeacon_page d where d.ftime >= 20151126 and d.ftime <= 20151126 and d.biz_id = 11023 and d.page_id = 778495 limit 0,20;表r_ibeacon_biz_page_d 的主要字段信息如下:
ftime bigint(20)
biz_id bigint(20)
page_id varchar(200)
索引为:IDX_BID_PID_FTIME<biz_id,page_id,ftime>
Explain结果如下:
explain select d.id from v_ibeacon_page d where d.ftime >= 20151126 and d.ftime <= 20151126 and d.biz_id = 11023 and d.page_id = 778495 limit 0,20;
+----+-------------+-------+-------+-------------------+-------------------+---------+------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+-------------------+-------------------+---------+------+------+--------------------------+
| 1 | SIMPLE | d | ref | IDX_BID_PID_FTIME | IDX_BID_PID_FTIME | 9 | const|141614| Using where; Using index |
+----+-------------+-------+-------+-------------------+-------------------+---------+------+------+--------------------------+
1 row in set (0.00 sec)观察以上explain结果可以看到一切正常,SQL“符合预期”的走了索引。但是rows稍微多了点,但是看起来也“好像”ok。但是问题就是出现尖峰。
问题排查:
首先,注意到的一点就是explain中的type异常,是ref。按照上面的解释,如果走了索引那应该是range类型才对啊。
其次,观察key_len,9,发现确实有些不对,怎么会这么小。按照类型所占字节,9刚好为biz_id的长度,确定这条SQL虽然走了索引,但是只使用了biz_id字段。原因呢?
然后执行“desc r_ibeacon_biz_page_d”,查看表结构的索引字段,突然发现page_id的类型怎么是varchar,再看SQL中page_id=11023。突然意识到了什么,此时刚好违反索引匹配的第四条规则。更改SQL“page_id=11023”为“page_id=‘11023’”验证.看到type=range、key_len=621,符合预期。接下来要做的就是更改表中page_id的类型为bigint。隔天再看接口的尖峰果然削平。
Explain是一个很好的工具,可以用来验证SQL是否使用了索引,更重要的是验证SQL是否如预期的使用索引上。排查线上问题还有profile和optimizer_trace,由于实际没有太多用到暂且不表。
常见问题汇总
Range怎么使用索引?
详见上文
Order by使用索引吗?
该问题可以由以下资料解释:
SQL queries with an order by clause don’t need to sort the result explicitly if the relevant index already delivers the rows in the required order. That means the same index that is used for the where clause must also cover the order by clause.
总之一句话:索引本身并不能避免排序,当根据索引取出的数据已经满足order by子句的要求就可以避免排序操作。
order by太慢?
避免数据排序,采用索引排序(分页查询文艺写法)
limit offset太慢?
避免大offset,使用where语句过滤更多的行。更多参考的实践《Efficient Pagination Using MySQL》
- 为什么不走索引(索引也走了,还是慢)?
类型是否一致: int vs char(varchar)、varchar(32)vs varchar(64)
字符集是否一致:涉及表关联时,两表字符集是否一致。
- 多列数据作为组合索引如何使用?
多列索引的情况,如果存在复杂的查询操作,需要增加一列hash列用于数据的过滤,如下:
SELECT * FROM tbl_name WHERE hash_col=MD5(CONCAT(val1,val2)) AND col1=val1 AND col2=val2;
更新记录:
2016.02.01 增加组合索引复杂查询的使用方法
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/12-02-2015/mysql-index-optimize.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!